 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
TempoQR: Temporal Question Reasoning over Knowledge Graphs
Dec 10, 2021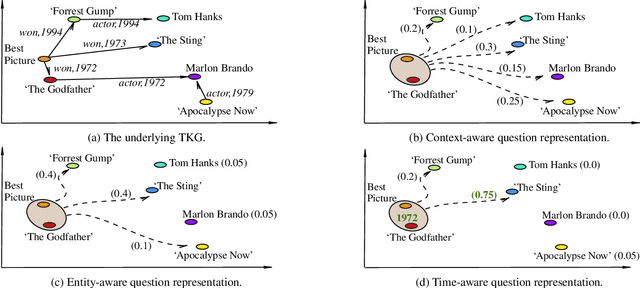

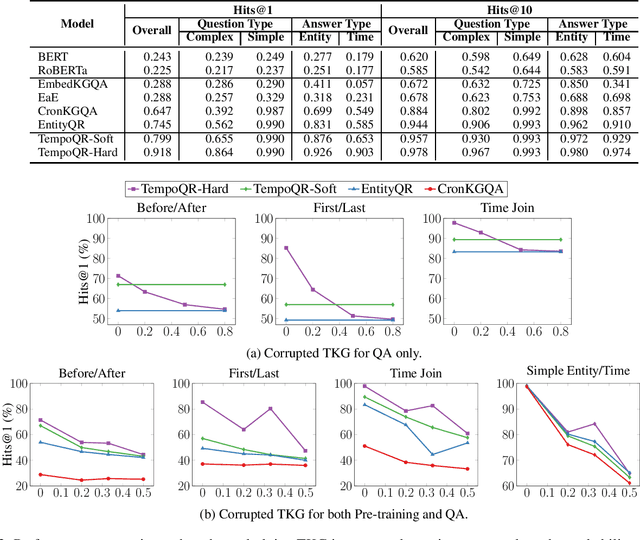
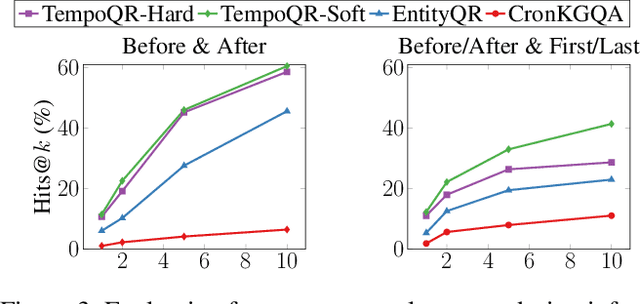
Knowledge Graph Question Answering (KGQA) involves retrieving facts from a Knowledge Graph (KG) using natural language queries. A KG is a curated set of facts consisting of entities linked by relations. Certain facts include also temporal information forming a Temporal KG (TKG). Although many natural questions involve explicit or implicit time constraints, question answering (QA) over TKGs has been a relatively unexplored area. Existing solutions are mainly designed for simple temporal questions that can be answered directly by a single TKG fact. This paper puts forth a comprehensive embedding-based framework for answering complex questions over TKGs. Our method termed temporal question reasoning (TempoQR) exploits TKG embeddings to ground the question to the specific entities and time scope it refers to. It does so by augmenting the question embeddings with context, entity and time-aware information by employing three specialized modules. The first computes a textual representation of a given question, the second combines it with the entity embeddings for entities involved in the question, and the third generates question-specific time embeddings. Finally, a transformer-based encoder learns to fuse the generated temporal information with the question representation, which is used for answer predictions. Extensive experiments show that TempoQR improves accuracy by 25--45 percentage points on complex temporal questions over state-of-the-art approaches and it generalizes better to unseen question types.
Semi-supervised Interactive Intent Labeling
May 12, 2021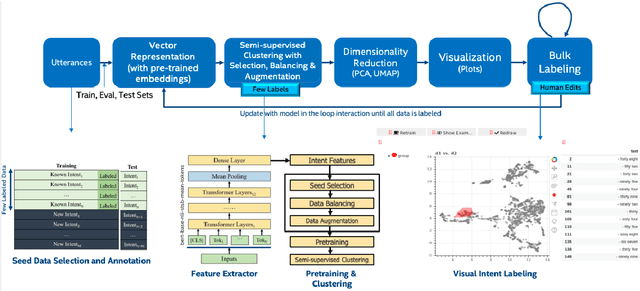

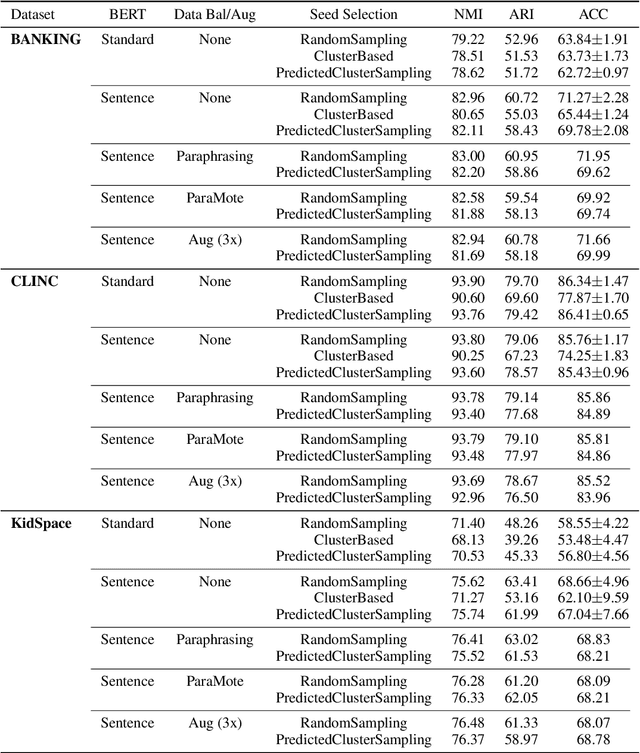
Building the Natural Language Understanding (NLU) modules of task-oriented Spoken Dialogue Systems (SDS) involves a definition of intents and entities, collection of task-relevant data, annotating the data with intents and entities, and then repeating the same process over and over again for adding any functionality/enhancement to the SDS. In this work, we showcase an Intent Bulk Labeling system where SDS developers can interactively label and augment training data from unlabeled utterance corpora using advanced clustering and visual labeling methods. We extend the Deep Aligned Clustering work with a better backbone BERT model, explore techniques to select the seed data for labeling, and develop a data balancing method using an oversampling technique that utilizes paraphrasing models. We also look at the effect of data augmentation on the clustering process. Our results show that we can achieve over 10% gain in clustering accuracy on some datasets using the combination of the above techniques. Finally, we extract utterance embeddings from the clustering model and plot the data to interactively bulk label the samples, reducing the time and effort for data labeling of the whole dataset significantly.