 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Counterfactuals: Evaluating Cultural Biases in Large Vision-Language Models with Counterfactual Examples
Mar 02, 2026Large Vision-Language Models (LVLMs) have grown increasingly powerful in recent years, but can also exhibit harmful biases. Prior studies investigating such biases have primarily focused on demographic traits related to the visual characteristics of a person depicted in an image, such as their race or gender. This has left biases related to cultural differences (e.g., religion, socioeconomic status), which cannot be readily discerned from an individual's appearance alone, relatively understudied. A key challenge in measuring cultural biases is that determining which group an individual belongs to often depends upon cultural context cues in images, and datasets annotated with cultural context cues are lacking. To address this gap, we introduce Cultural Counterfactuals: a high-quality synthetic dataset containing nearly 60k counterfactual images for measuring cultural biases related to religion, nationality, and socioeconomic status. To ensure that cultural contexts are accurately depicted, we generate our dataset using an image-editing model to place people of different demographics into real cultural context images. This enables the construction of counterfactual image sets which depict the same person in multiple different contexts, allowing for precise measurement of the impact that cultural context differences have on LVLM outputs. We demonstrate the utility of Cultural Counterfactuals for quantifying cultural biases in popular LVLMs.
WARM-CAT: : Warm-Started Test-Time Comprehensive Knowledge Accumulation for Compositional Zero-Shot Learning
Feb 26, 2026Compositional Zero-Shot Learning (CZSL) aims to recognize novel attribute-object compositions based on the knowledge learned from seen ones. Existing methods suffer from performance degradation caused by the distribution shift of label space at test time, which stems from the inclusion of unseen compositions recombined from attributes and objects. To overcome the challenge, we propose a novel approach that accumulates comprehensive knowledge in both textual and visual modalities from unsupervised data to update multimodal prototypes at test time. Building on this, we further design an adaptive update weight to control the degree of prototype adjustment, enabling the model to flexibly adapt to distribution shift during testing. Moreover, a dynamic priority queue is introduced that stores high-confidence images to acquire visual prototypes from historical images for inference. Since the model tends to favor compositions already stored in the queue during testing, we warm-start the queue by initializing it with training images for visual prototypes of seen compositions and generating unseen visual prototypes using the mapping learned between seen and unseen textual prototypes. Considering the semantic consistency of multimodal knowledge, we align textual and visual prototypes by multimodal collaborative representation learning. To provide a more reliable evaluation for CZSL, we introduce a new benchmark dataset, C-Fashion, and refine the widely used but noisy MIT-States dataset. Extensive experiments indicate that our approach achieves state-of-the-art performance on four benchmark datasets under both closed-world and open-world settings. The source code and datasets are available at https://github.com/xud-yan/WARM-CAT .
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
Investigating the Robustness of Retrieval-Augmented Generation at the Query Level
Jul 09, 2025Large language models (LLMs) are very costly and inefficient to update with new information. To address this limitation, retrieval-augmented generation (RAG) has been proposed as a solution that dynamically incorporates external knowledge during inference, improving factual consistency and reducing hallucinations. Despite its promise, RAG systems face practical challenges-most notably, a strong dependence on the quality of the input query for accurate retrieval. In this paper, we investigate the sensitivity of different components in the RAG pipeline to various types of query perturbations. Our analysis reveals that the performance of commonly used retrievers can degrade significantly even under minor query variations. We study each module in isolation as well as their combined effect in an end-to-end question answering setting, using both general-domain and domain-specific datasets. Additionally, we propose an evaluation framework to systematically assess the query-level robustness of RAG pipelines and offer actionable recommendations for practitioners based on the results of more than 1092 experiments we performed.
A Semantic Parsing Framework for End-to-End Time Normalization
Jul 08, 2025Time normalization is the task of converting natural language temporal expressions into machine-readable representations. It underpins many downstream applications in information retrieval, question answering, and clinical decision-making. Traditional systems based on the ISO-TimeML schema limit expressivity and struggle with complex constructs such as compositional, event-relative, and multi-span time expressions. In this work, we introduce a novel formulation of time normalization as a code generation task grounded in the SCATE framework, which defines temporal semantics through symbolic and compositional operators. We implement a fully executable SCATE Python library and demonstrate that large language models (LLMs) can generate executable SCATE code. Leveraging this capability, we develop an automatic data augmentation pipeline using LLMs to synthesize large-scale annotated data with code-level validation. Our experiments show that small, locally deployable models trained on this augmented data can achieve strong performance, outperforming even their LLM parents and enabling practical, accurate, and interpretable time normalization.
TiMo: Spatiotemporal Foundation Model for Satellite Image Time Series
May 13, 2025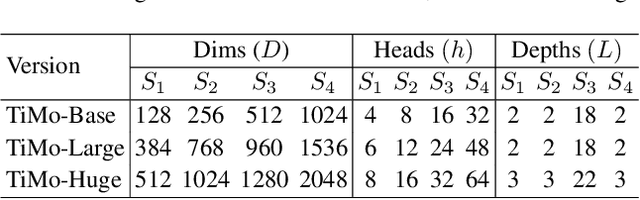
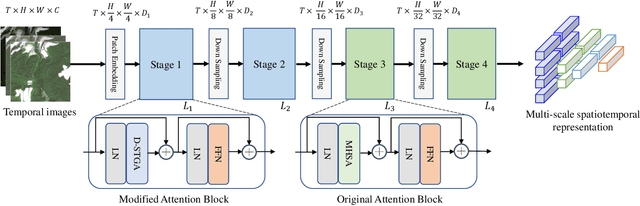
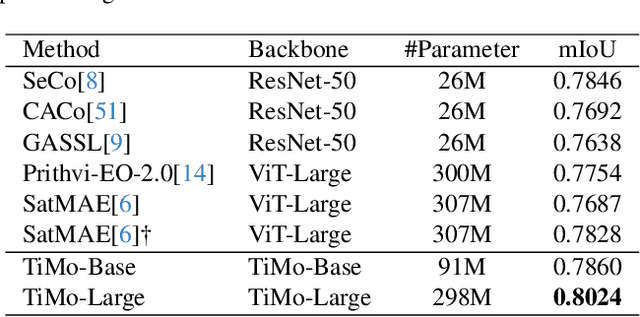
Satellite image time series (SITS) provide continuous observations of the Earth's surface, making them essential for applications such as environmental management and disaster assessment. However, existing spatiotemporal foundation models rely on plain vision transformers, which encode entire temporal sequences without explicitly capturing multiscale spatiotemporal relationships between land objects. This limitation hinders their effectiveness in downstream tasks. To overcome this challenge, we propose TiMo, a novel hierarchical vision transformer foundation model tailored for SITS analysis. At its core, we introduce a spatiotemporal gyroscope attention mechanism that dynamically captures evolving multiscale patterns across both time and space. For pre-training, we curate MillionST, a large-scale dataset of one million images from 100,000 geographic locations, each captured across 10 temporal phases over five years, encompassing diverse geospatial changes and seasonal variations. Leveraging this dataset, we adapt masked image modeling to pre-train TiMo, enabling it to effectively learn and encode generalizable spatiotemporal representations.Extensive experiments across multiple spatiotemporal tasks-including deforestation monitoring, land cover segmentation, crop type classification, and flood detection-demonstrate TiMo's superiority over state-of-the-art methods. Code, model, and dataset will be released at https://github.com/MiliLab/TiMo.
Distribution-aware Dataset Distillation for Efficient Image Restoration
Apr 21, 2025With the exponential increase in image data, training an image restoration model is laborious. Dataset distillation is a potential solution to this problem, yet current distillation techniques are a blank canvas in the field of image restoration. To fill this gap, we propose the Distribution-aware Dataset Distillation method (TripleD), a new framework that extends the principles of dataset distillation to image restoration. Specifically, TripleD uses a pre-trained vision Transformer to extract features from images for complexity evaluation, and the subset (the number of samples is much smaller than the original training set) is selected based on complexity. The selected subset is then fed through a lightweight CNN that fine-tunes the image distribution to align with the distribution of the original dataset at the feature level. To efficiently condense knowledge, the training is divided into two stages. Early stages focus on simpler, low-complexity samples to build foundational knowledge, while later stages select more complex and uncertain samples as the model matures. Our method achieves promising performance on multiple image restoration tasks, including multi-task image restoration, all-in-one image restoration, and ultra-high-definition image restoration tasks. Note that we can train a state-of-the-art image restoration model on an ultra-high-definition (4K resolution) dataset using only one consumer-grade GPU in less than 8 hours (500 savings in computing resources and immeasurable training time).
AdaQual-Diff: Diffusion-Based Image Restoration via Adaptive Quality Prompting
Apr 17, 2025Restoring images afflicted by complex real-world degradations remains challenging, as conventional methods often fail to adapt to the unique mixture and severity of artifacts present. This stems from a reliance on indirect cues which poorly capture the true perceptual quality deficit. To address this fundamental limitation, we introduce AdaQual-Diff, a diffusion-based framework that integrates perceptual quality assessment directly into the generative restoration process. Our approach establishes a mathematical relationship between regional quality scores from DeQAScore and optimal guidance complexity, implemented through an Adaptive Quality Prompting mechanism. This mechanism systematically modulates prompt structure according to measured degradation severity: regions with lower perceptual quality receive computationally intensive, structurally complex prompts with precise restoration directives, while higher quality regions receive minimal prompts focused on preservation rather than intervention. The technical core of our method lies in the dynamic allocation of computational resources proportional to degradation severity, creating a spatially-varying guidance field that directs the diffusion process with mathematical precision. By combining this quality-guided approach with content-specific conditioning, our framework achieves fine-grained control over regional restoration intensity without requiring additional parameters or inference iterations. Experimental results demonstrate that AdaQual-Diff achieves visually superior restorations across diverse synthetic and real-world datasets.
Transformer-Based Temporal Information Extraction and Application: A Review
Apr 10, 2025

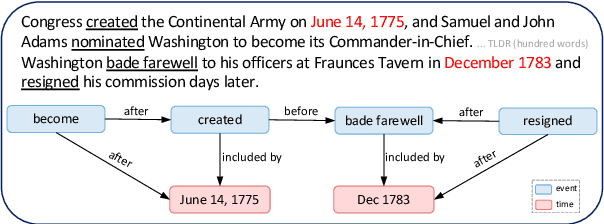

Temporal information extraction (IE) aims to extract structured temporal information from unstructured text, thereby uncovering the implicit timelines within. This technique is applied across domains such as healthcare, newswire, and intelligence analysis, aiding models in these areas to perform temporal reasoning and enabling human users to grasp the temporal structure of text. Transformer-based pre-trained language models have produced revolutionary advancements in natural language processing, demonstrating exceptional performance across a multitude of tasks. Despite the achievements garnered by Transformer-based approaches in temporal IE, there is a lack of comprehensive reviews on these endeavors. In this paper, we aim to bridge this gap by systematically summarizing and analyzing the body of work on temporal IE using Transformers while highlighting potential future research directions.
Conformal Robust Beamforming via Generative Channel Models
Apr 09, 2025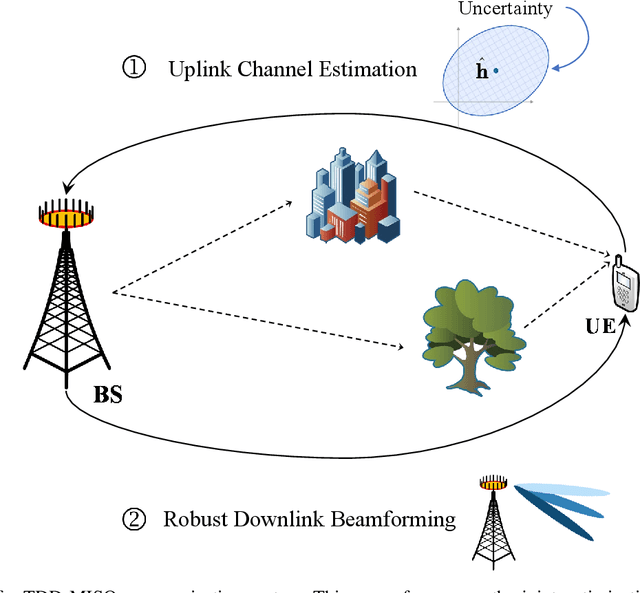
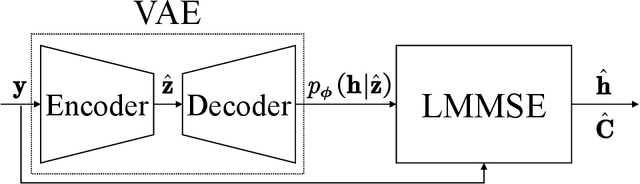
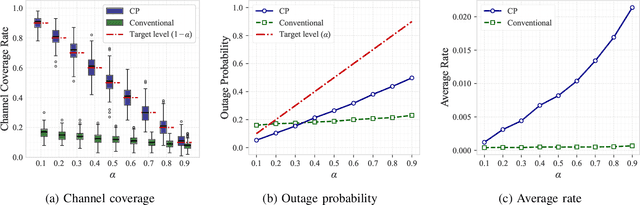
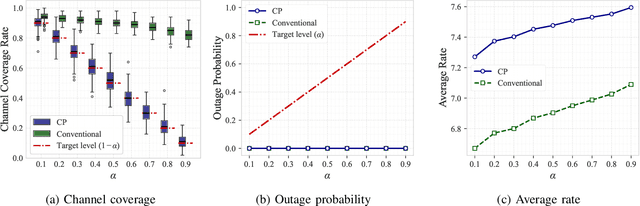
Traditional approaches to outage-constrained beamforming optimization rely on statistical assumptions about channel distributions and estimation errors. However, the resulting outage probability guarantees are only valid when these assumptions accurately reflect reality. This paper tackles the fundamental challenge of providing outage probability guarantees that remain robust regardless of specific channel or estimation error models. To achieve this, we propose a two-stage framework: (i) construction of a channel uncertainty set using a generative channel model combined with conformal prediction, and (ii) robust beamforming via the solution of a min-max optimization problem. The proposed method separates the modeling and optimization tasks, enabling principled uncertainty quantification and robust decision-making. Simulation results confirm the effectiveness and reliability of the framework in achieving model-agnostic outage guarantees.