 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Feb 17, 2025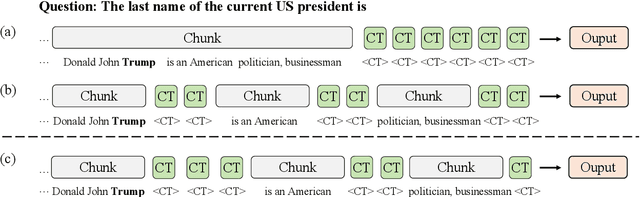
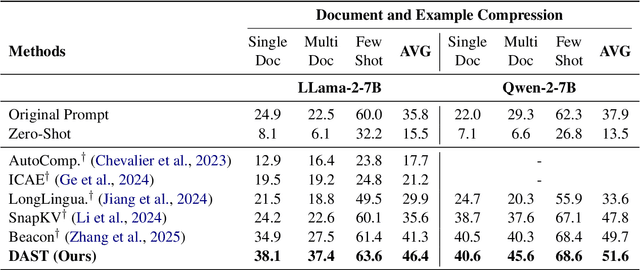
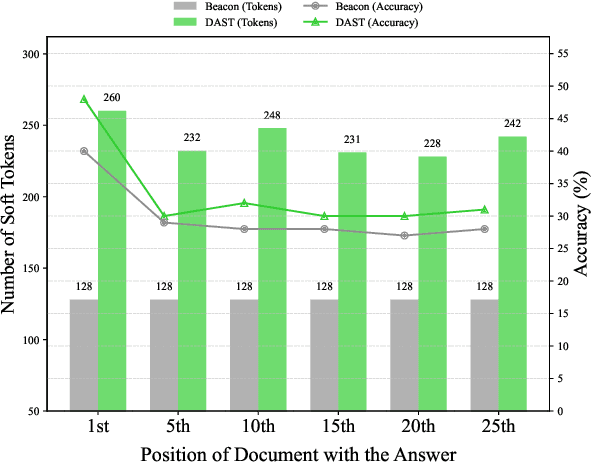
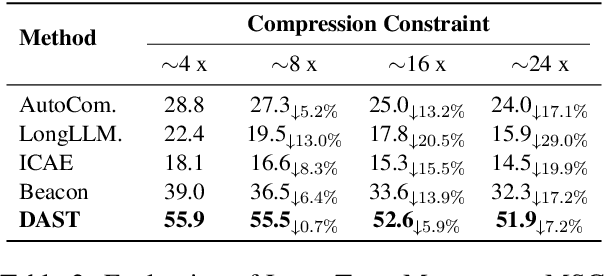
Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.
Towards Real-World Writing Assistance: A Chinese Character Checking Benchmark with Faked and Misspelled Characters
Nov 19, 2023



Writing assistance is an application closely related to human life and is also a fundamental Natural Language Processing (NLP) research field. Its aim is to improve the correctness and quality of input texts, with character checking being crucial in detecting and correcting wrong characters. From the perspective of the real world where handwriting occupies the vast majority, characters that humans get wrong include faked characters (i.e., untrue characters created due to writing errors) and misspelled characters (i.e., true characters used incorrectly due to spelling errors). However, existing datasets and related studies only focus on misspelled characters mainly caused by phonological or visual confusion, thereby ignoring faked characters which are more common and difficult. To break through this dilemma, we present Visual-C$^3$, a human-annotated Visual Chinese Character Checking dataset with faked and misspelled Chinese characters. To the best of our knowledge, Visual-C$^3$ is the first real-world visual and the largest human-crafted dataset for the Chinese character checking scenario. Additionally, we also propose and evaluate novel baseline methods on Visual-C$^3$. Extensive empirical results and analyses show that Visual-C$^3$ is high-quality yet challenging. The Visual-C$^3$ dataset and the baseline methods will be publicly available to facilitate further research in the community.