 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefine Knowledge of Large Language Models via Adaptive Contrastive Learning
Feb 11, 2025How to alleviate the hallucinations of Large Language Models (LLMs) has always been the fundamental goal pursued by the LLMs research community. Looking through numerous hallucination-related studies, a mainstream category of methods is to reduce hallucinations by optimizing the knowledge representation of LLMs to change their output. Considering that the core focus of these works is the knowledge acquired by models, and knowledge has long been a central theme in human societal progress, we believe that the process of models refining knowledge can greatly benefit from the way humans learn. In our work, by imitating the human learning process, we design an Adaptive Contrastive Learning strategy. Our method flexibly constructs different positive and negative samples for contrastive learning based on LLMs' actual mastery of knowledge. This strategy helps LLMs consolidate the correct knowledge they already possess, deepen their understanding of the correct knowledge they have encountered but not fully grasped, forget the incorrect knowledge they previously learned, and honestly acknowledge the knowledge they lack. Extensive experiments and detailed analyses on widely used datasets demonstrate the effectiveness of our method.
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Sep 26, 2024



Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Do Large Language Model Understand Multi-Intent Spoken Language ?
Mar 08, 2024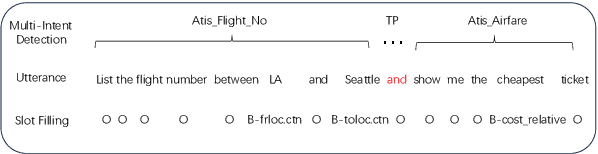
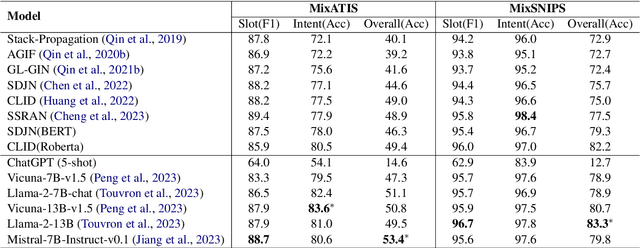
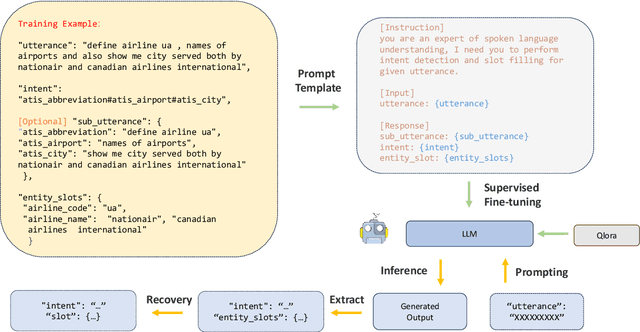

This study marks a significant advancement by harnessing Large Language Models (LLMs) for multi-intent spoken language understanding (SLU), proposing a unique methodology that capitalizes on the generative power of LLMs within an SLU context. Our innovative technique reconfigures entity slots specifically for LLM application in multi-intent SLU environments and introduces the concept of Sub-Intent Instruction (SII), enhancing the dissection and interpretation of intricate, multi-intent communication within varied domains. The resultant datasets, dubbed LM-MixATIS and LM-MixSNIPS, are crafted from pre-existing benchmarks. Our research illustrates that LLMs can match and potentially excel beyond the capabilities of current state-of-the-art multi-intent SLU models. It further explores LLM efficacy across various intent configurations and dataset proportions. Moreover, we introduce two pioneering metrics, Entity Slot Accuracy (ESA) and Combined Semantic Accuracy (CSA), to provide an in-depth analysis of LLM proficiency in this complex field.
Mitigating Catastrophic Forgetting in Multi-domain Chinese Spelling Correction by Multi-stage Knowledge Transfer Framework
Feb 18, 2024Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in given sentences. Recently, multi-domain CSC has gradually attracted the attention of researchers because it is more practicable. In this paper, we focus on the key flaw of the CSC model when adapting to multi-domain scenarios: the tendency to forget previously acquired knowledge upon learning new domain-specific knowledge (i.e., catastrophic forgetting). To address this, we propose a novel model-agnostic Multi-stage Knowledge Transfer (MKT) framework, which utilizes a continuously evolving teacher model for knowledge transfer in each domain, rather than focusing solely on new domain knowledge. It deserves to be mentioned that we are the first to apply continual learning methods to the multi-domain CSC task. Experiments prove the effectiveness of our proposed method, and further analyses demonstrate the importance of overcoming catastrophic forgetting for improving the model performance.
Towards Real-World Writing Assistance: A Chinese Character Checking Benchmark with Faked and Misspelled Characters
Nov 19, 2023



Writing assistance is an application closely related to human life and is also a fundamental Natural Language Processing (NLP) research field. Its aim is to improve the correctness and quality of input texts, with character checking being crucial in detecting and correcting wrong characters. From the perspective of the real world where handwriting occupies the vast majority, characters that humans get wrong include faked characters (i.e., untrue characters created due to writing errors) and misspelled characters (i.e., true characters used incorrectly due to spelling errors). However, existing datasets and related studies only focus on misspelled characters mainly caused by phonological or visual confusion, thereby ignoring faked characters which are more common and difficult. To break through this dilemma, we present Visual-C$^3$, a human-annotated Visual Chinese Character Checking dataset with faked and misspelled Chinese characters. To the best of our knowledge, Visual-C$^3$ is the first real-world visual and the largest human-crafted dataset for the Chinese character checking scenario. Additionally, we also propose and evaluate novel baseline methods on Visual-C$^3$. Extensive empirical results and analyses show that Visual-C$^3$ is high-quality yet challenging. The Visual-C$^3$ dataset and the baseline methods will be publicly available to facilitate further research in the community.
A Frustratingly Easy Plug-and-Play Detection-and-Reasoning Module for Chinese Spelling Check
Oct 13, 2023In recent years, Chinese Spelling Check (CSC) has been greatly improved by designing task-specific pre-training methods or introducing auxiliary tasks, which mostly solve this task in an end-to-end fashion. In this paper, we propose to decompose the CSC workflow into detection, reasoning, and searching subtasks so that the rich external knowledge about the Chinese language can be leveraged more directly and efficiently. Specifically, we design a plug-and-play detection-and-reasoning module that is compatible with existing SOTA non-autoregressive CSC models to further boost their performance. We find that the detection-and-reasoning module trained for one model can also benefit other models. We also study the primary interpretability provided by the task decomposition. Extensive experiments and detailed analyses demonstrate the effectiveness and competitiveness of the proposed module.
On the Effectiveness of Large Language Models for Chinese Text Correction
Jul 18, 2023Recently, the development and progress of Large Language Models (LLMs) have amazed the entire Artificial Intelligence community. As an outstanding representative of LLMs and the foundation model that set off this wave of research on LLMs, ChatGPT has attracted more and more researchers to study its capabilities and performance on various downstream Natural Language Processing (NLP) tasks. While marveling at ChatGPT's incredible performance on kinds of tasks, we notice that ChatGPT also has excellent multilingual processing capabilities, such as Chinese. To explore the Chinese processing ability of ChatGPT, we focus on Chinese Text Correction, a fundamental and challenging Chinese NLP task. Specifically, we evaluate ChatGPT on the Chinese Grammatical Error Correction (CGEC) and Chinese Spelling Check (CSC) tasks, which are two main Chinese Text Correction scenarios. From extensive analyses and comparisons with previous state-of-the-art fine-tuned models, we empirically find that the ChatGPT currently has both amazing performance and unsatisfactory behavior for Chinese Text Correction. We believe our findings will promote the landing and application of LLMs in the Chinese NLP community.
Progressive Multi-task Learning Framework for Chinese Text Error Correction
Jul 03, 2023
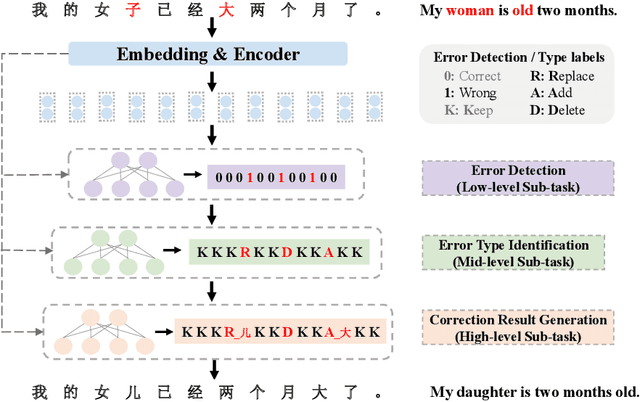
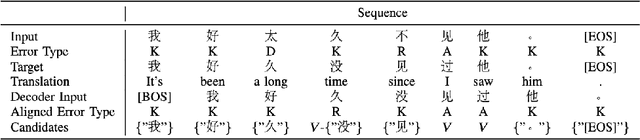

Chinese Text Error Correction (CTEC) aims to detect and correct errors in the input text, which benefits human's daily life and various downstream tasks. Recent approaches mainly employ Pre-trained Language Models (PLMs) to resolve CTEC task and achieve tremendous success. However, previous approaches suffer from issues of over-correction and under-correction, and the former is especially conspicuous in the precision-critical CTEC task. To mitigate the issue of overcorrection, we propose a novel model-agnostic progressive multitask learning framework for CTEC, named ProTEC, which guides a CTEC model to learn the task from easy to difficult. We divide CTEC task into three sub-tasks from easy to difficult: Error Detection, Error Type Identification, and Correction Result Generation. During the training process, ProTEC guides the model to learn text error correction progressively by incorporating these sub-tasks into a multi-task training objective. During the inference process, the model completes these sub-tasks in turn to generate the correction results. Extensive experiments and detailed analyses fully demonstrate the effectiveness and efficiency of our proposed framework.