 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Chatbot to Digital Colleague: The Paradigm Shift Toward Persistent Autonomous AI
Jun 12, 2026Large Language Models (LLMs) are undergoing a fundamental transformation from conversational generators into integrated AI systems capable of reasoning, action, memory, and self-improvement. We conceptualize this transition as a shift from Chatbot to Digital Colleague: from conversational answers to persistent work. We organize this transition along two tightly coupled dimensions. First, at the cognitive core level, LLMs are advancing from Chatbot-era "fast thinking" systems driven by next-token prediction toward Thinking LLMs that leverage inference-time computation, Chain-of-Thought reasoning, reflection, process supervision, and reinforcement learning to support more deliberate and reliable cognition. Second, at the tool-augmented task execution level, LLMs are progressing from tool-calling Agents that invoke external resources in an ad hoc manner toward OpenClaw-style workstation systems (OpenClaw) equipped with persistent Workspaces, skills, verification loops, and governance. The "Workspace + Skill" paradigm makes episodic tool use colleague-like via state persistence, reusable procedures, task closure, and experience reuse. We examine data construction shifts from instruction-response pairs to State-Action-Observation trajectories and evaluation from static benchmarks to sandboxed, auditable, self-evolving AI ecosystems.
Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
Mar 19, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success in interpreting natural scenes, their ability to process discrete symbols -- the fundamental building blocks of human cognition -- remains a critical open question. Unlike continuous visual data, symbols such as mathematical formulas, chemical structures, and linguistic characters require precise, deeper interpretation. This paper introduces a comprehensive benchmark to evaluate how top-tier MLLMs navigate these "discrete semantic spaces" across five domains: language, culture, mathematics, physics, and chemistry. Our investigation uncovers a counterintuitive phenomenon: models often fail at basic symbol recognition yet succeed in complex reasoning tasks, suggesting they rely on linguistic probability rather than true visual perception. By exposing this "cognitive mismatch", we highlight a significant gap in current AI capabilities: the struggle to truly perceive and understand the symbolic languages that underpin scientific discovery and abstract thought. This work offers a roadmap for developing more rigorous, human-aligned intelligent systems.
EvoConfig: Self-Evolving Multi-Agent Systems for Efficient Autonomous Environment Configuration
Jan 23, 2026A reliable executable environment is the foundation for ensuring that large language models solve software engineering tasks. Due to the complex and tedious construction process, large-scale configuration is relatively inefficient. However, most methods always overlook fine-grained analysis of the actions performed by the agent, making it difficult to handle complex errors and resulting in configuration failures. To address this bottleneck, we propose EvoConfig, an efficient environment configuration framework that optimizes multi-agent collaboration to build correct runtime environments. EvoConfig features an expert diagnosis module for fine-grained post-execution analysis, and a self-evolving mechanism that lets expert agents self-feedback and dynamically adjust error-fixing priorities in real time. Empirically, EvoConfig matches the previous state-of-the-art Repo2Run on Repo2Run's 420 repositories, while delivering clear gains on harder cases: on the more challenging Envbench, EvoConfig achieves a 78.1% success rate, outperforming Repo2Run by 7.1%. Beyond end-to-end success, EvoConfig also demonstrates stronger debugging competence, achieving higher accuracy in error identification and producing more effective repair recommendations than existing methods.
TangramPuzzle: Evaluating Multimodal Large Language Models with Compositional Spatial Reasoning
Jan 23, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual recognition and semantic understanding. Nevertheless, their ability to perform precise compositional spatial reasoning remains largely unexplored. Existing benchmarks often involve relatively simple tasks and rely on semantic approximations or coarse relative positioning, while their evaluation metrics are typically limited and lack rigorous mathematical formulations. To bridge this gap, we introduce TangramPuzzle, a geometry-grounded benchmark designed to evaluate compositional spatial reasoning through the lens of the classic Tangram game. We propose the Tangram Construction Expression (TCE), a symbolic geometric framework that grounds tangram assemblies in exact, machine-verifiable coordinate specifications, to mitigate the ambiguity of visual approximation. We design two complementary tasks: Outline Prediction, which demands inferring global shapes from local components, and End-to-End Code Generation, which requires solving inverse geometric assembly problems. We conduct extensive evaluation experiments on advanced open-source and proprietary models, revealing an interesting insight: MLLMs tend to prioritize matching the target silhouette while neglecting geometric constraints, leading to distortions or deformations of the pieces.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Refine Knowledge of Large Language Models via Adaptive Contrastive Learning
Feb 11, 2025How to alleviate the hallucinations of Large Language Models (LLMs) has always been the fundamental goal pursued by the LLMs research community. Looking through numerous hallucination-related studies, a mainstream category of methods is to reduce hallucinations by optimizing the knowledge representation of LLMs to change their output. Considering that the core focus of these works is the knowledge acquired by models, and knowledge has long been a central theme in human societal progress, we believe that the process of models refining knowledge can greatly benefit from the way humans learn. In our work, by imitating the human learning process, we design an Adaptive Contrastive Learning strategy. Our method flexibly constructs different positive and negative samples for contrastive learning based on LLMs' actual mastery of knowledge. This strategy helps LLMs consolidate the correct knowledge they already possess, deepen their understanding of the correct knowledge they have encountered but not fully grasped, forget the incorrect knowledge they previously learned, and honestly acknowledge the knowledge they lack. Extensive experiments and detailed analyses on widely used datasets demonstrate the effectiveness of our method.
Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
Nov 26, 2024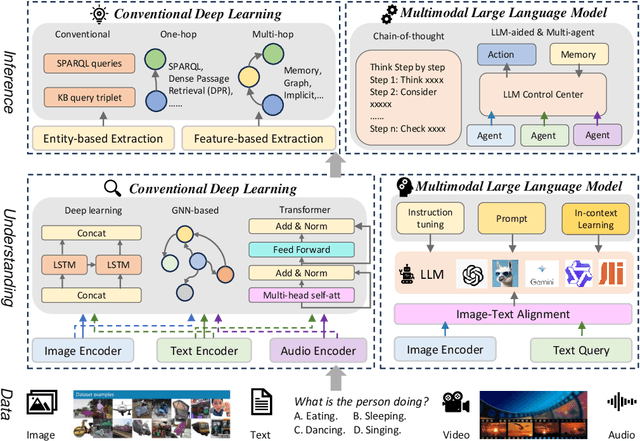
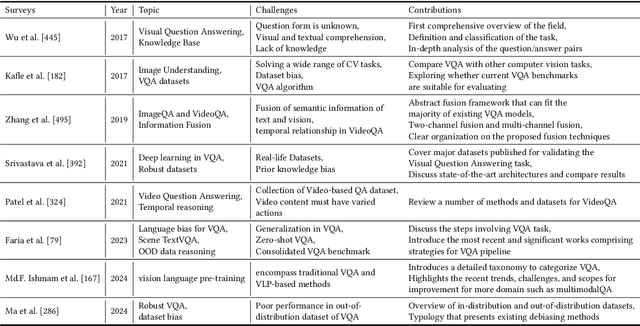
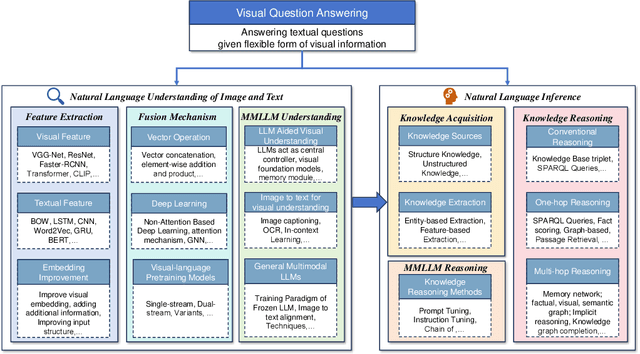
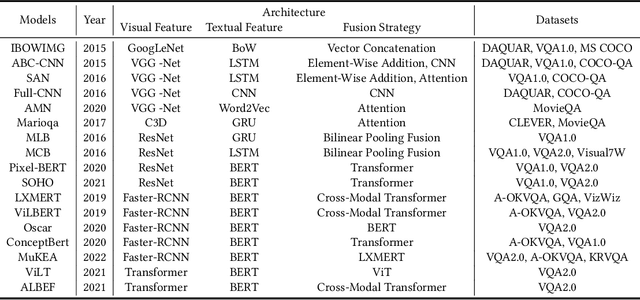
Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.
FLEX-CLIP: Feature-Level GEneration Network Enhanced CLIP for X-shot Cross-modal Retrieval
Nov 26, 2024Given a query from one modality, few-shot cross-modal retrieval (CMR) retrieves semantically similar instances in another modality with the target domain including classes that are disjoint from the source domain. Compared with classical few-shot CMR methods, vision-language pretraining methods like CLIP have shown great few-shot or zero-shot learning performance. However, they still suffer challenges due to (1) the feature degradation encountered in the target domain and (2) the extreme data imbalance. To tackle these issues, we propose FLEX-CLIP, a novel Feature-level Generation Network Enhanced CLIP. FLEX-CLIP includes two training stages. In multimodal feature generation, we propose a composite multimodal VAE-GAN network to capture real feature distribution patterns and generate pseudo samples based on CLIP features, addressing data imbalance. For common space projection, we develop a gate residual network to fuse CLIP features with projected features, reducing feature degradation in X-shot scenarios. Experimental results on four benchmark datasets show a 7%-15% improvement over state-of-the-art methods, with ablation studies demonstrating enhancement of CLIP features.
Dynamic Demonstration Retrieval and Cognitive Understanding for Emotional Support Conversation
Apr 03, 2024Emotional Support Conversation (ESC) systems are pivotal in providing empathetic interactions, aiding users through negative emotional states by understanding and addressing their unique experiences. In this paper, we tackle two key challenges in ESC: enhancing contextually relevant and empathetic response generation through dynamic demonstration retrieval, and advancing cognitive understanding to grasp implicit mental states comprehensively. We introduce Dynamic Demonstration Retrieval and Cognitive-Aspect Situation Understanding (\ourwork), a novel approach that synergizes these elements to improve the quality of support provided in ESCs. By leveraging in-context learning and persona information, we introduce an innovative retrieval mechanism that selects informative and personalized demonstration pairs. We also propose a cognitive understanding module that utilizes four cognitive relationships from the ATOMIC knowledge source to deepen situational awareness of help-seekers' mental states. Our supportive decoder integrates information from diverse knowledge sources, underpinning response generation that is both empathetic and cognitively aware. The effectiveness of \ourwork is demonstrated through extensive automatic and human evaluations, revealing substantial improvements over numerous state-of-the-art models, with up to 13.79\% enhancement in overall performance of ten metrics. Our codes are available for public access to facilitate further research and development.