 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
May 22, 2025While recent text-to-image (T2I) models show impressive capabilities in synthesizing images from brief descriptions, their performance significantly degrades when confronted with long, detail-intensive prompts required in professional applications. We present DetailMaster, the first comprehensive benchmark specifically designed to evaluate T2I models' systematical abilities to handle extended textual inputs that contain complex compositional requirements. Our benchmark introduces four critical evaluation dimensions: Character Attributes, Structured Character Locations, Multi-Dimensional Scene Attributes, and Explicit Spatial/Interactive Relationships. The benchmark comprises long and detail-rich prompts averaging 284.89 tokens, with high quality validated by expert annotators. Evaluation on 7 general-purpose and 5 long-prompt-optimized T2I models reveals critical performance limitations: state-of-the-art models achieve merely ~50% accuracy in key dimensions like attribute binding and spatial reasoning, while all models showing progressive performance degradation as prompt length increases. Our analysis highlights systemic failures in structural comprehension and detail overload handling, motivating future research into architectures with enhanced compositional reasoning. We open-source the dataset, data curation code, and evaluation tools to advance detail-rich T2I generation and enable broad applications that would otherwise be infeasible due to the lack of a dedicated benchmark.
Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
Nov 26, 2024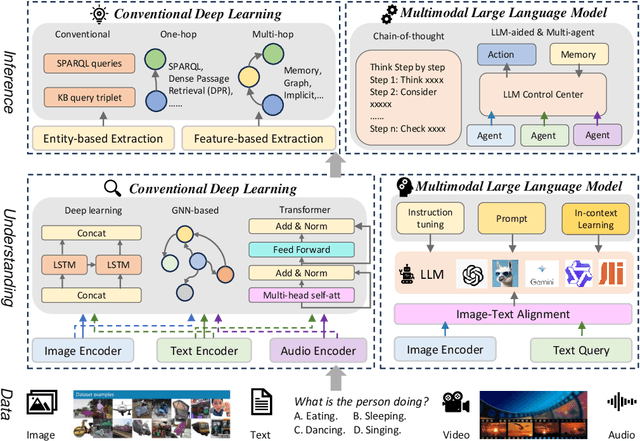
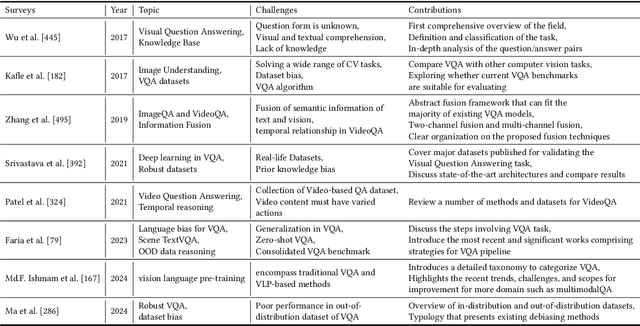
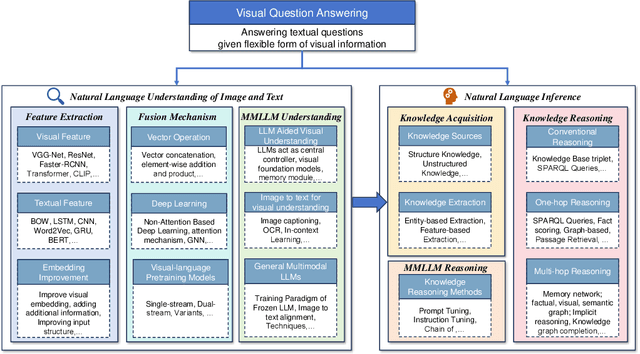
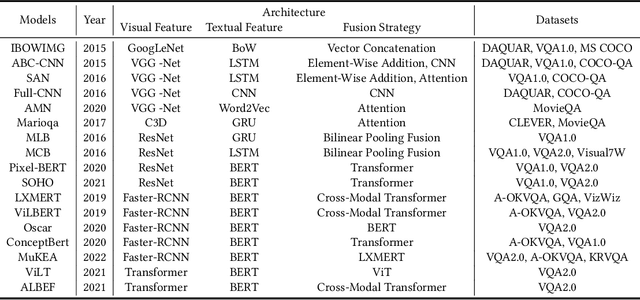
Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.