 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX-CLIP: Feature-Level GEneration Network Enhanced CLIP for X-shot Cross-modal Retrieval
Nov 26, 2024Given a query from one modality, few-shot cross-modal retrieval (CMR) retrieves semantically similar instances in another modality with the target domain including classes that are disjoint from the source domain. Compared with classical few-shot CMR methods, vision-language pretraining methods like CLIP have shown great few-shot or zero-shot learning performance. However, they still suffer challenges due to (1) the feature degradation encountered in the target domain and (2) the extreme data imbalance. To tackle these issues, we propose FLEX-CLIP, a novel Feature-level Generation Network Enhanced CLIP. FLEX-CLIP includes two training stages. In multimodal feature generation, we propose a composite multimodal VAE-GAN network to capture real feature distribution patterns and generate pseudo samples based on CLIP features, addressing data imbalance. For common space projection, we develop a gate residual network to fuse CLIP features with projected features, reducing feature degradation in X-shot scenarios. Experimental results on four benchmark datasets show a 7%-15% improvement over state-of-the-art methods, with ablation studies demonstrating enhancement of CLIP features.
Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
Nov 26, 2024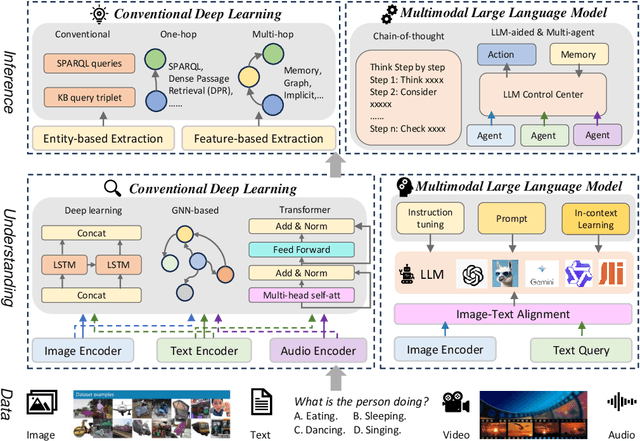
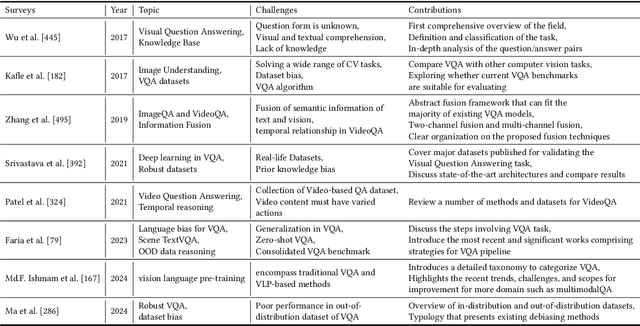
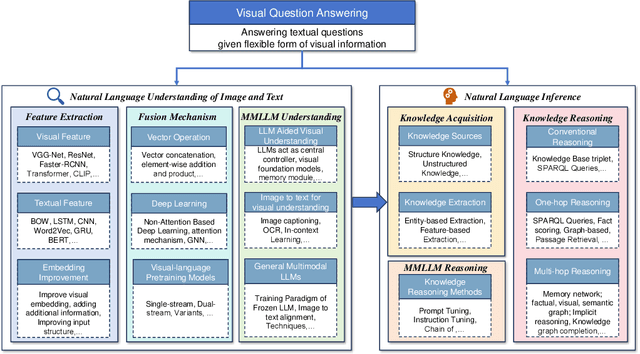
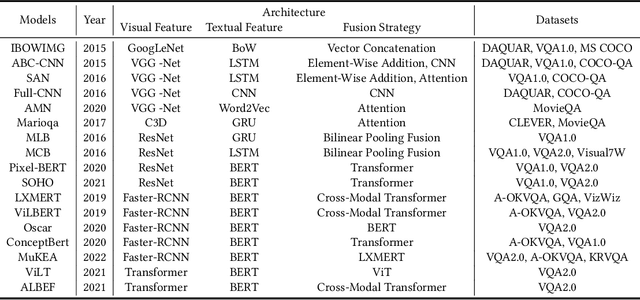
Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.