 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning
Feb 03, 2026Deep Research (DR) agents extend Large Language Models (LLMs) beyond parametric knowledge by autonomously retrieving and synthesizing evidence from large web corpora into long-form reports, enabling a long-horizon agentic paradigm. However, unlike real-time conversational assistants, DR is computationally expensive and time-consuming, creating an autonomy-interaction dilemma: high autonomy on ambiguous user queries often leads to prolonged execution with unsatisfactory outcomes. To address this, we propose IntentRL, a framework that trains proactive agents to clarify latent user intents before starting long-horizon research. To overcome the scarcity of open-ended research data, we introduce a scalable pipeline that expands a few seed samples into high-quality dialogue turns via a shallow-to-deep intent refinement graph. We further adopt a two-stage reinforcement learning (RL) strategy: Stage I applies RL on offline dialogues to efficiently learn general user-interaction behavior, while Stage II uses the trained agent and a user simulator for online rollouts to strengthen adaptation to diverse user feedback. Extensive experiments show that IntentRL significantly improves both intent hit rate and downstream task performance, outperforming the built-in clarify modules of closed-source DR agents and proactive LLM baselines.
Attention Basin: Why Contextual Position Matters in Large Language Models
Aug 07, 2025The performance of Large Language Models (LLMs) is significantly sensitive to the contextual position of information in the input. To investigate the mechanism behind this positional bias, our extensive experiments reveal a consistent phenomenon we term the attention basin: when presented with a sequence of structured items (e.g., retrieved documents or few-shot examples), models systematically assign higher attention to the items at the beginning and end of the sequence, while neglecting those in the middle. Crucially, our analysis further reveals that allocating higher attention to critical information is key to enhancing model performance. Based on these insights, we introduce Attention-Driven Reranking (AttnRank), a two-stage framework that (i) estimates a model's intrinsic positional attention preferences using a small calibration set, and (ii) reorders retrieved documents or few-shot examples to align the most salient content with these high-attention positions. AttnRank is a model-agnostic, training-free, and plug-and-play method with minimal computational overhead. Experiments on multi-hop QA and few-shot in-context learning tasks demonstrate that AttnRank achieves substantial improvements across 10 large language models of varying architectures and scales, without modifying model parameters or training procedures.
Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
Nov 26, 2024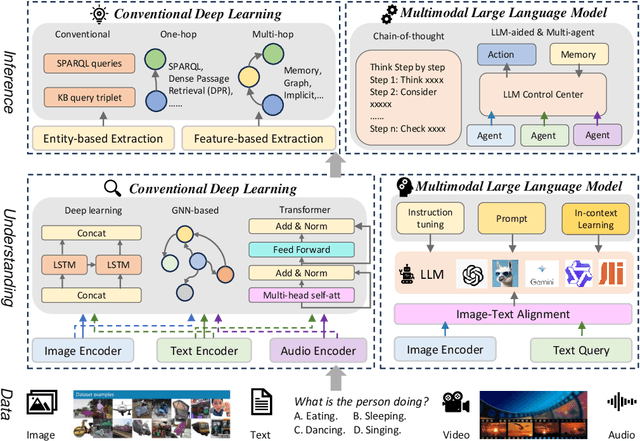
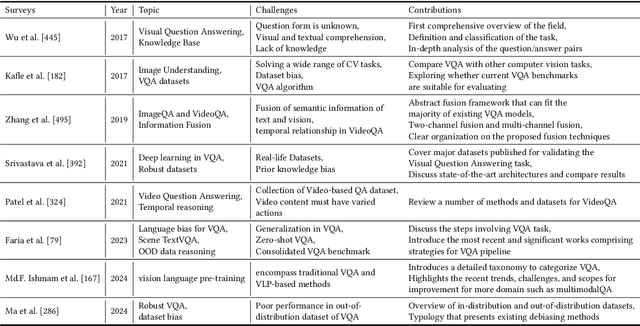
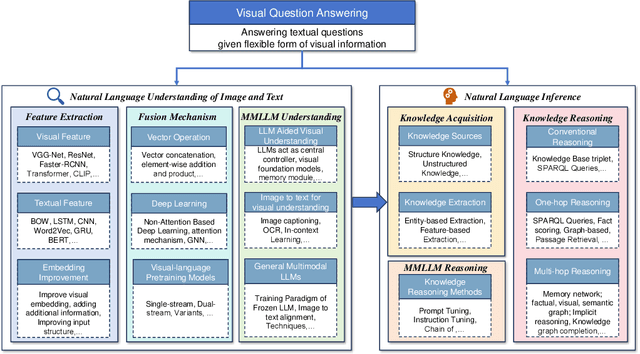
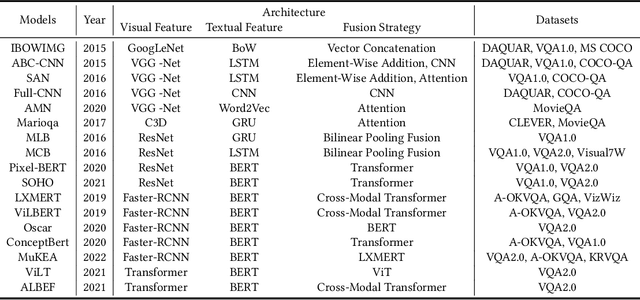
Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.