 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning
Feb 03, 2026Deep Research (DR) agents extend Large Language Models (LLMs) beyond parametric knowledge by autonomously retrieving and synthesizing evidence from large web corpora into long-form reports, enabling a long-horizon agentic paradigm. However, unlike real-time conversational assistants, DR is computationally expensive and time-consuming, creating an autonomy-interaction dilemma: high autonomy on ambiguous user queries often leads to prolonged execution with unsatisfactory outcomes. To address this, we propose IntentRL, a framework that trains proactive agents to clarify latent user intents before starting long-horizon research. To overcome the scarcity of open-ended research data, we introduce a scalable pipeline that expands a few seed samples into high-quality dialogue turns via a shallow-to-deep intent refinement graph. We further adopt a two-stage reinforcement learning (RL) strategy: Stage I applies RL on offline dialogues to efficiently learn general user-interaction behavior, while Stage II uses the trained agent and a user simulator for online rollouts to strengthen adaptation to diverse user feedback. Extensive experiments show that IntentRL significantly improves both intent hit rate and downstream task performance, outperforming the built-in clarify modules of closed-source DR agents and proactive LLM baselines.
R$^3$L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Jan 07, 2026Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$^3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$^3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning
Aug 20, 2025Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model without exposing their private data. Data heterogeneity is a fundamental challenge in FL, which can result in poor convergence and performance degradation. Client drift has been recognized as one of the factors contributing to this issue resulting from the multiple local updates in FedAvg. However, in cross-device FL, a different form of drift arises due to the partial client participation, but it has not been studied well. This drift, we referred as period drift, occurs as participating clients at each communication round may exhibit distinct data distribution that deviates from that of all clients. It could be more harmful than client drift since the optimization objective shifts with every round. In this paper, we investigate the interaction between period drift and client drift, finding that period drift can have a particularly detrimental effect on cross-device FL as the degree of data heterogeneity increases. To tackle these issues, we propose a predict-observe framework and present an instantiated method, FedEve, where these two types of drift can compensate each other to mitigate their overall impact. We provide theoretical evidence that our approach can reduce the variance of model updates. Extensive experiments demonstrate that our method outperforms alternatives on non-iid data in cross-device settings.
AdaFusion: Prompt-Guided Inference with Adaptive Fusion of Pathology Foundation Models
Aug 07, 2025Pathology foundation models (PFMs) have demonstrated strong representational capabilities through self-supervised pre-training on large-scale, unannotated histopathology image datasets. However, their diverse yet opaque pretraining contexts, shaped by both data-related and structural/training factors, introduce latent biases that hinder generalisability and transparency in downstream applications. In this paper, we propose AdaFusion, a novel prompt-guided inference framework that, to our knowledge, is among the very first to dynamically integrate complementary knowledge from multiple PFMs. Our method compresses and aligns tile-level features from diverse models and employs a lightweight attention mechanism to adaptively fuse them based on tissue phenotype context. We evaluate AdaFusion on three real-world benchmarks spanning treatment response prediction, tumour grading, and spatial gene expression inference. Our approach consistently surpasses individual PFMs across both classification and regression tasks, while offering interpretable insights into each model's biosemantic specialisation. These results highlight AdaFusion's ability to bridge heterogeneous PFMs, achieving both enhanced performance and interpretability of model-specific inductive biases.
Editing as Unlearning: Are Knowledge Editing Methods Strong Baselines for Large Language Model Unlearning?
May 26, 2025Large language Model (LLM) unlearning, i.e., selectively removing information from LLMs, is vital for responsible model deployment. Differently, LLM knowledge editing aims to modify LLM knowledge instead of removing it. Though editing and unlearning seem to be two distinct tasks, we find there is a tight connection between them. In this paper, we conceptualize unlearning as a special case of editing where information is modified to a refusal or "empty set" $\emptyset$ response, signifying its removal. This paper thus investigates if knowledge editing techniques are strong baselines for LLM unlearning. We evaluate state-of-the-art (SOTA) editing methods (e.g., ROME, MEMIT, GRACE, WISE, and AlphaEdit) against existing unlearning approaches on pretrained and finetuned knowledge. Results show certain editing methods, notably WISE and AlphaEdit, are effective unlearning baselines, especially for pretrained knowledge, and excel in generating human-aligned refusal answers. To better adapt editing methods for unlearning applications, we propose practical recipes including self-improvement and query merging. The former leverages the LLM's own in-context learning ability to craft a more human-aligned unlearning target, and the latter enables ROME and MEMIT to perform well in unlearning longer sample sequences. We advocate for the unlearning community to adopt SOTA editing methods as baselines and explore unlearning from an editing perspective for more holistic LLM memory control.
You Are Your Own Best Teacher: Achieving Centralized-level Performance in Federated Learning under Heterogeneous and Long-tailed Data
Mar 10, 2025Data heterogeneity, stemming from local non-IID data and global long-tailed distributions, is a major challenge in federated learning (FL), leading to significant performance gaps compared to centralized learning. Previous research found that poor representations and biased classifiers are the main problems and proposed neural-collapse-inspired synthetic simplex ETF to help representations be closer to neural collapse optima. However, we find that the neural-collapse-inspired methods are not strong enough to reach neural collapse and still have huge gaps to centralized training. In this paper, we rethink this issue from a self-bootstrap perspective and propose FedYoYo (You Are Your Own Best Teacher), introducing Augmented Self-bootstrap Distillation (ASD) to improve representation learning by distilling knowledge between weakly and strongly augmented local samples, without needing extra datasets or models. We further introduce Distribution-aware Logit Adjustment (DLA) to balance the self-bootstrap process and correct biased feature representations. FedYoYo nearly eliminates the performance gap, achieving centralized-level performance even under mixed heterogeneity. It enhances local representation learning, reducing model drift and improving convergence, with feature prototypes closer to neural collapse optimality. Extensive experiments show FedYoYo achieves state-of-the-art results, even surpassing centralized logit adjustment methods by 5.4\% under global long-tailed settings.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
Merging LoRAs like Playing LEGO: Pushing the Modularity of LoRA to Extremes Through Rank-Wise Clustering
Sep 24, 2024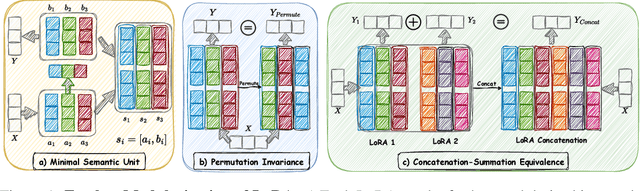
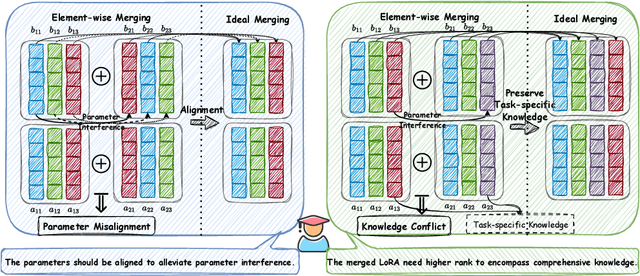
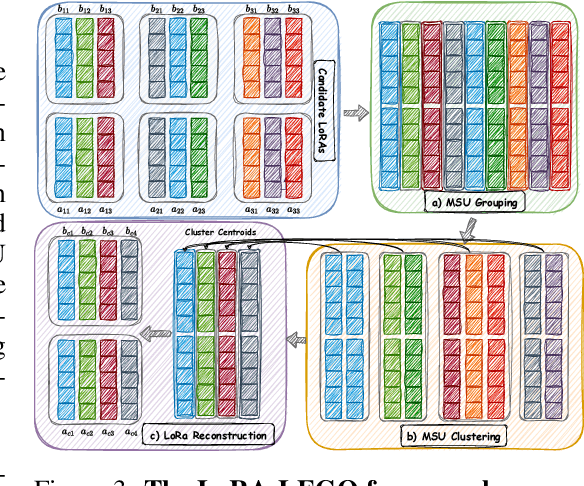
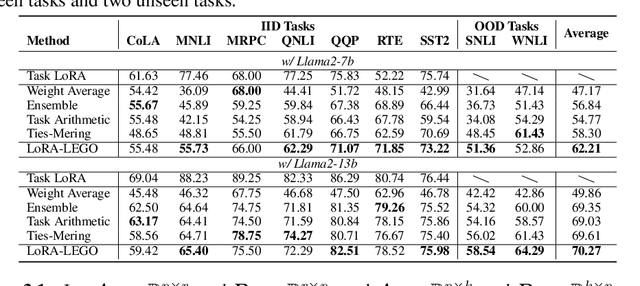
Low-Rank Adaptation (LoRA) has emerged as a popular technique for fine-tuning large language models (LLMs) to various domains due to its modular design and widespread availability on platforms like Huggingface. This modularity has sparked interest in combining multiple LoRAs to enhance LLM capabilities. However, existing methods for LoRA composition primarily focus on task-specific adaptations that require additional training, and current model merging techniques often fail to fully leverage LoRA's modular nature, leading to parameter interference and performance degradation. In this paper, we investigate the feasibility of disassembling and reassembling multiple LoRAs at a finer granularity, analogous to assembling LEGO blocks. We introduce the concept of Minimal Semantic Units (MSUs), where the parameters corresponding to each rank in LoRA function as independent units. These MSUs demonstrate permutation invariance and concatenation-summation equivalence properties, enabling flexible combinations to create new LoRAs. Building on these insights, we propose the LoRA-LEGO framework. This framework conducts rank-wise parameter clustering by grouping MSUs from different LoRAs into $k$ clusters. The centroid of each cluster serves as a representative MSU, enabling the assembly of a merged LoRA with an adjusted rank of $k$. Additionally, we apply a dual reweighting strategy to optimize the scale of the merged LoRA. Experiments across various benchmarks demonstrate that our method outperforms existing approaches in LoRA merging.
WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
May 23, 2024Large language models (LLMs) need knowledge updates to meet the ever-growing world facts and correct the hallucinated responses, facilitating the methods of lifelong model editing. Where the updated knowledge resides in memories is a fundamental question for model editing. In this paper, we find that editing either long-term memory (direct model parameters) or working memory (non-parametric knowledge of neural network activations/representations by retrieval) will result in an impossible triangle -- reliability, generalization, and locality can not be realized together in the lifelong editing settings. For long-term memory, directly editing the parameters will cause conflicts with irrelevant pretrained knowledge or previous edits (poor reliability and locality). For working memory, retrieval-based activations can hardly make the model understand the edits and generalize (poor generalization). Therefore, we propose WISE to bridge the gap between memories. In WISE, we design a dual parametric memory scheme, which consists of the main memory for the pretrained knowledge and a side memory for the edited knowledge. We only edit the knowledge in the side memory and train a router to decide which memory to go through when given a query. For continual editing, we devise a knowledge-sharding mechanism where different sets of edits reside in distinct subspaces of parameters, and are subsequently merged into a shared memory without conflicts. Extensive experiments show that WISE can outperform previous model editing methods and overcome the impossible triangle under lifelong model editing of question answering, hallucination, and out-of-distribution settings across trending LLM architectures, e.g., GPT, LLaMA, and Mistral. Code will be released at https://github.com/zjunlp/EasyEdit.