 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAR: Next-Scale Autoregressive Generation for Spatial Gene Expression Prediction
Oct 05, 2025



Spatial Transcriptomics (ST) offers spatially resolved gene expression but remains costly. Predicting expression directly from widely available Hematoxylin and Eosin (H&E) stained images presents a cost-effective alternative. However, most computational approaches (i) predict each gene independently, overlooking co-expression structure, and (ii) cast the task as continuous regression despite expression being discrete counts. This mismatch can yield biologically implausible outputs and complicate downstream analyses. We introduce GenAR, a multi-scale autoregressive framework that refines predictions from coarse to fine. GenAR clusters genes into hierarchical groups to expose cross-gene dependencies, models expression as codebook-free discrete token generation to directly predict raw counts, and conditions decoding on fused histological and spatial embeddings. From an information-theoretic perspective, the discrete formulation avoids log-induced biases and the coarse-to-fine factorization aligns with a principled conditional decomposition. Extensive experimental results on four Spatial Transcriptomics datasets across different tissue types demonstrate that GenAR achieves state-of-the-art performance, offering potential implications for precision medicine and cost-effective molecular profiling. Code is publicly available at https://github.com/oyjr/genar.
FLEX-CLIP: Feature-Level GEneration Network Enhanced CLIP for X-shot Cross-modal Retrieval
Nov 26, 2024Given a query from one modality, few-shot cross-modal retrieval (CMR) retrieves semantically similar instances in another modality with the target domain including classes that are disjoint from the source domain. Compared with classical few-shot CMR methods, vision-language pretraining methods like CLIP have shown great few-shot or zero-shot learning performance. However, they still suffer challenges due to (1) the feature degradation encountered in the target domain and (2) the extreme data imbalance. To tackle these issues, we propose FLEX-CLIP, a novel Feature-level Generation Network Enhanced CLIP. FLEX-CLIP includes two training stages. In multimodal feature generation, we propose a composite multimodal VAE-GAN network to capture real feature distribution patterns and generate pseudo samples based on CLIP features, addressing data imbalance. For common space projection, we develop a gate residual network to fuse CLIP features with projected features, reducing feature degradation in X-shot scenarios. Experimental results on four benchmark datasets show a 7%-15% improvement over state-of-the-art methods, with ablation studies demonstrating enhancement of CLIP features.
A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems
Feb 28, 2024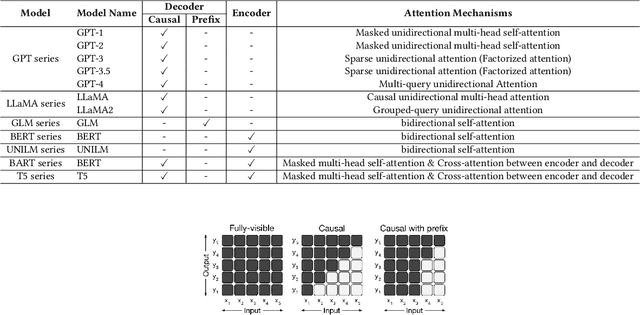

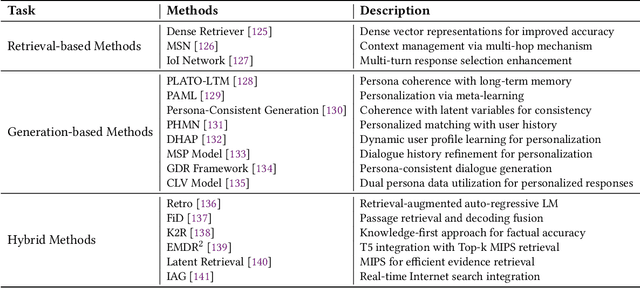
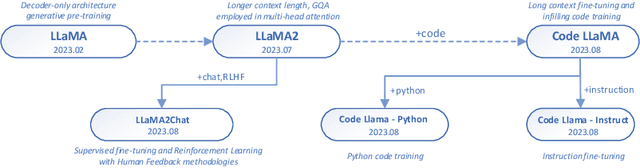
This survey provides a comprehensive review of research on multi-turn dialogue systems, with a particular focus on multi-turn dialogue systems based on large language models (LLMs). This paper aims to (a) give a summary of existing LLMs and approaches for adapting LLMs to downstream tasks; (b) elaborate recent advances in multi-turn dialogue systems, covering both LLM-based open-domain dialogue (ODD) and task-oriented dialogue (TOD) systems, along with datasets and evaluation metrics; (c) discuss some future emphasis and recent research problems arising from the development of LLMs and the increasing demands on multi-turn dialogue systems.