 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Hierarchical Structure in Vision Models with Sparse Autoencoders
May 21, 2025The ImageNet hierarchy provides a structured taxonomy of object categories, offering a valuable lens through which to analyze the representations learned by deep vision models. In this work, we conduct a comprehensive analysis of how vision models encode the ImageNet hierarchy, leveraging Sparse Autoencoders (SAEs) to probe their internal representations. SAEs have been widely used as an explanation tool for large language models (LLMs), where they enable the discovery of semantically meaningful features. Here, we extend their use to vision models to investigate whether learned representations align with the ontological structure defined by the ImageNet taxonomy. Our results show that SAEs uncover hierarchical relationships in model activations, revealing an implicit encoding of taxonomic structure. We analyze the consistency of these representations across different layers of the popular vision foundation model DINOv2 and provide insights into how deep vision models internalize hierarchical category information by increasing information in the class token through each layer. Our study establishes a framework for systematic hierarchical analysis of vision model representations and highlights the potential of SAEs as a tool for probing semantic structure in deep networks.
Steering Large Language Models to Evaluate and Amplify Creativity
Dec 08, 2024Although capable of generating creative text, Large Language Models (LLMs) are poor judges of what constitutes "creativity". In this work, we show that we can leverage this knowledge of how to write creatively in order to better judge what is creative. We take a mechanistic approach that extracts differences in the internal states of an LLM when prompted to respond "boringly" or "creatively" to provide a robust measure of creativity that corresponds strongly with human judgment. We also show these internal state differences can be applied to enhance the creativity of generated text at inference time.
Training-Free Mitigation of Language Reasoning Degradation After Multimodal Instruction Tuning
Dec 04, 2024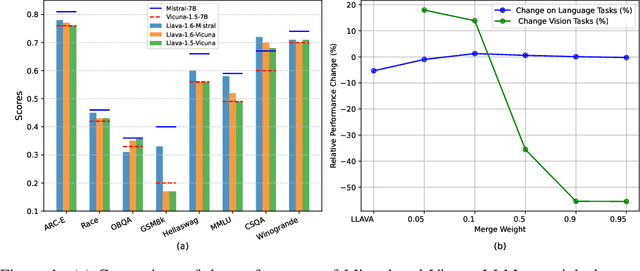

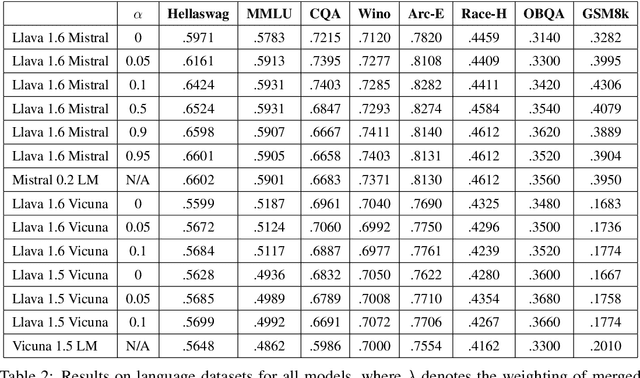
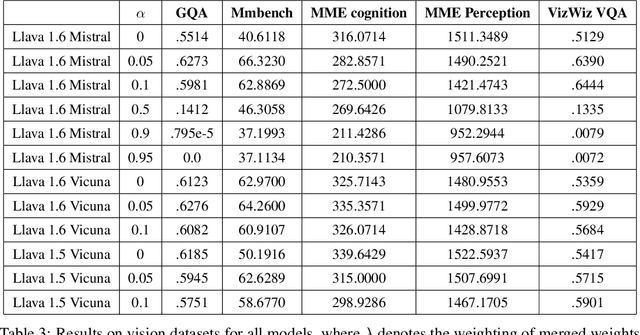
Multimodal models typically combine a powerful large language model (LLM) with a vision encoder and are then trained on multimodal data via instruction tuning. While this process adapts LLMs to multimodal settings, it remains unclear whether this adaptation compromises their original language reasoning capabilities. In this work, we explore the effects of multimodal instruction tuning on language reasoning performance. We focus on LLaVA, a leading multimodal framework that integrates LLMs such as Vicuna or Mistral with the CLIP vision encoder. We compare the performance of the original LLMs with their multimodal-adapted counterparts across eight language reasoning tasks. Our experiments yield several key insights. First, the impact of multimodal learning varies between Vicuna and Mistral: we observe a degradation in language reasoning for Mistral but improvements for Vicuna across most tasks. Second, while multimodal instruction learning consistently degrades performance on mathematical reasoning tasks (e.g., GSM8K), it enhances performance on commonsense reasoning tasks (e.g., CommonsenseQA). Finally, we demonstrate that a training-free model merging technique can effectively mitigate the language reasoning degradation observed in multimodal-adapted Mistral and even improve performance on visual tasks.
Debias your Large Multi-Modal Model at Test-Time with Non-Contrastive Visual Attribute Steering
Nov 15, 2024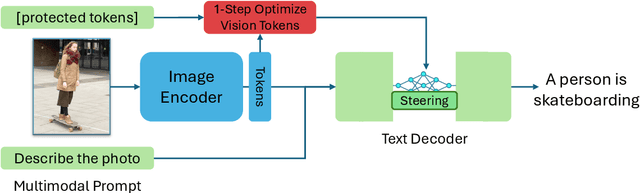
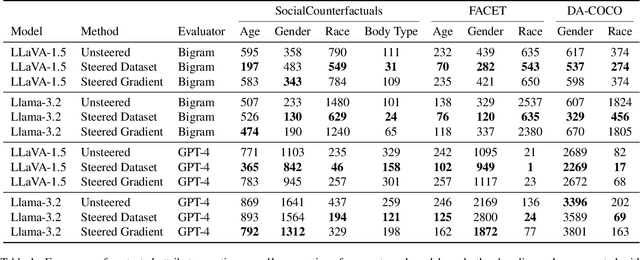
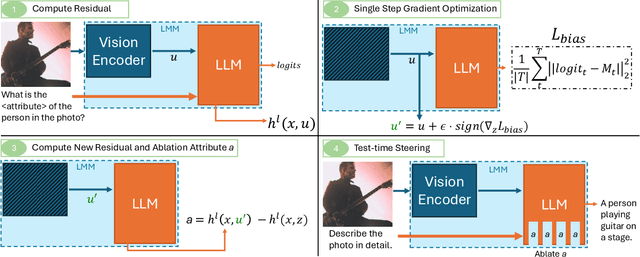
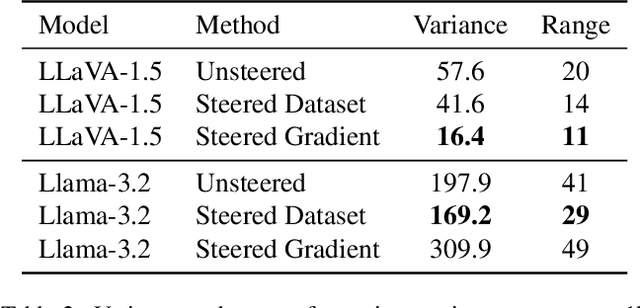
Large Multi-Modal Models (LMMs) have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input, such as an image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LMMs that directly removes biased representations during text generation to decrease outputs related to protected attributes, or even representing them internally. Our proposed method is training-free; given a single image and a list of target attributes, we can ablate the corresponding representations with just one step of gradient descent on the image itself. Our experiments show that not only can we can minimize the propensity of LMMs to generate text related to protected attributes, but we can improve sentiment and even simply use synthetic data to inform the ablation while retaining language modeling capabilities on real data such as COCO or FACET. Furthermore, we find the resulting generations from a debiased LMM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
Debiasing Large Vision-Language Models by Ablating Protected Attribute Representations
Oct 17, 2024



Large Vision Language Models (LVLMs) such as LLaVA have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LVLMs by directly ablating biased attributes during text generation to avoid generating text related to protected attributes, or even representing them internally. Our method requires no training and a relatively small amount of representative biased outputs (~1000 samples). Our experiments show that not only can we can minimize the propensity of LVLMs to generate text related to protected attributes, but we can even use synthetic data to inform the ablation while retaining captioning performance on real data such as COCO. Furthermore, we find the resulting generations from a debiased LVLM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023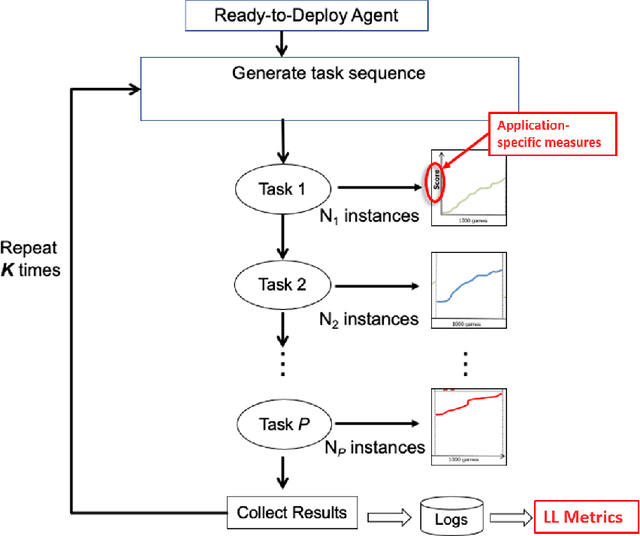
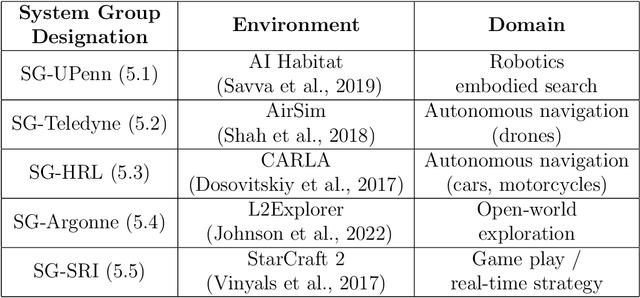


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Contrastive Identification of Covariate Shift in Image Data
Aug 19, 2021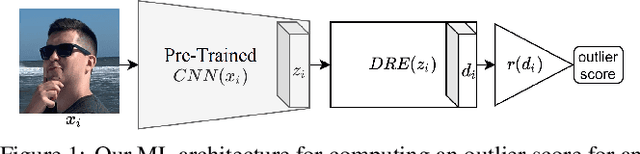

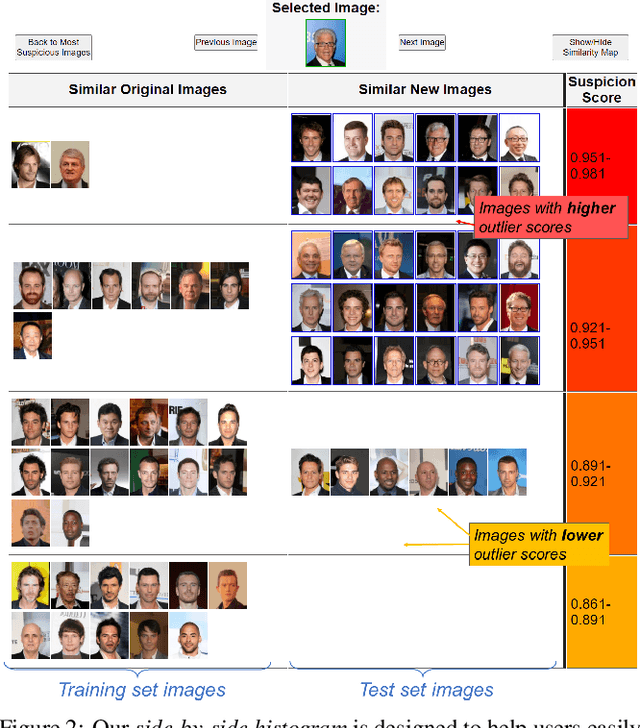
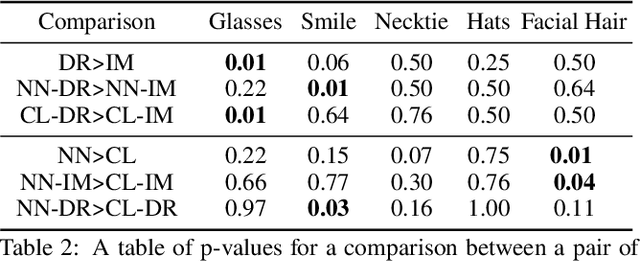
Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.
Generative Particle Variational Inference via Estimation of Functional Gradients
Mar 01, 2021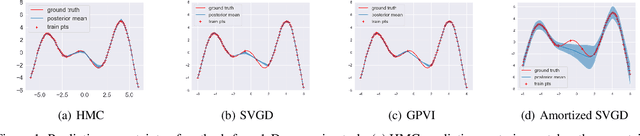
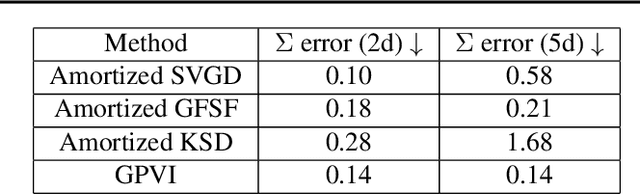
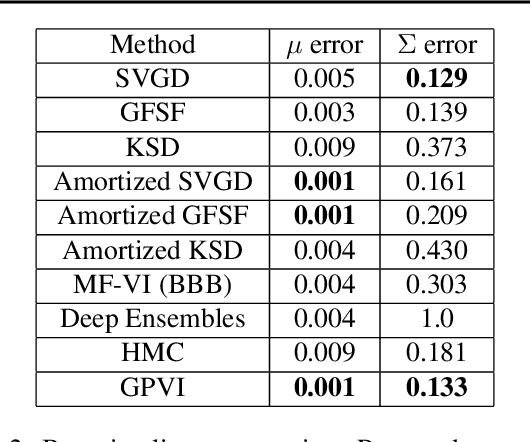
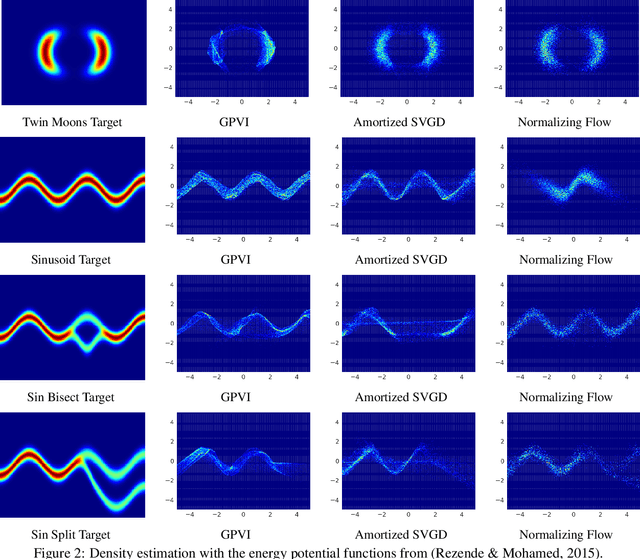
Recently, particle-based variational inference (ParVI) methods have gained interest because they directly minimize the Kullback-Leibler divergence and do not suffer from approximation errors from the evidence-based lower bound. However, many ParVI approaches do not allow arbitrary sampling from the posterior, and the few that do allow such sampling suffer from suboptimality. This work proposes a new method for learning to approximately sample from the posterior distribution. We construct a neural sampler that is trained with the functional gradient of the KL-divergence between the empirical sampling distribution and the target distribution, assuming the gradient resides within a reproducing kernel Hilbert space. Our generative ParVI (GPVI) approach maintains the asymptotic performance of ParVI methods while offering the flexibility of a generative sampler. Through carefully constructed experiments, we show that GPVI outperforms previous generative ParVI methods such as amortized SVGD, and is competitive with ParVI as well as gold-standard approaches like Hamiltonian Monte Carlo for fitting both exactly known and intractable target distributions.
Avoiding Side Effects in Complex Environments
Jun 11, 2020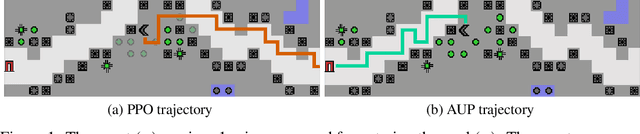


Reward function specification can be difficult, even in simple environments. Realistic environments contain millions of states. Rewarding the agent for making a widget may be easy, but penalizing the multitude of possible negative side effects is hard. In toy environments, Attainable Utility Preservation (AUP) avoids side effects by penalizing shifts in the ability to achieve randomly generated goals. We scale this approach to large, randomly generated environments based on Conway's Game of Life. By preserving optimal value for a single randomly generated reward function, AUP incurs modest overhead, completes the specified task, and avoids side effects.
Implicit Generative Modeling for Efficient Exploration
Nov 19, 2019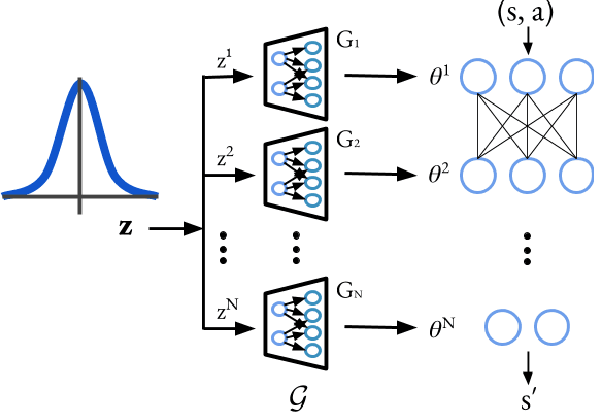

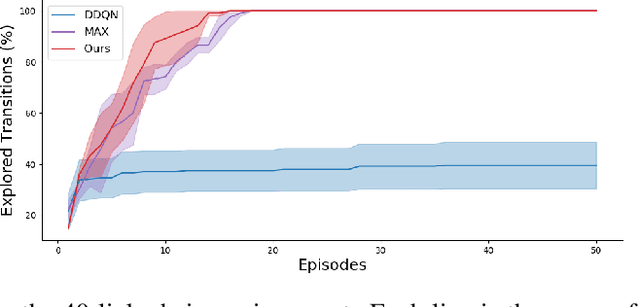
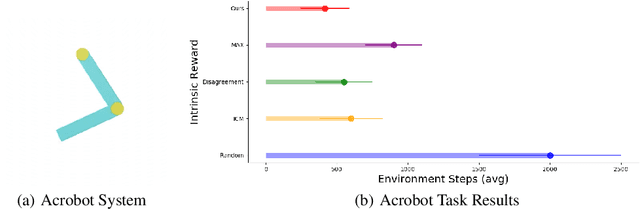
Efficient exploration remains a challenging problem in reinforcement learning, especially for those tasks where rewards from environments are sparse. A commonly used approach for exploring such environments is to introduce some "intrinsic" reward. In this work, we focus on model uncertainty estimation as an intrinsic reward for efficient exploration. In particular, we introduce an implicit generative modeling approach to estimate a Bayesian uncertainty of the agent's belief of the environment dynamics. Each random draw from our generative model is a neural network that instantiates the dynamic function, hence multiple draws would approximate the posterior, and the variance in the future prediction based on this posterior is used as an intrinsic reward for exploration. We design a training algorithm for our generative model based on the amortized Stein Variational Gradient Descent. In experiments, we compare our implementation with state-of-the-art intrinsic reward-based exploration approaches, including two recent approaches based on an ensemble of dynamic models. In challenging exploration tasks, our implicit generative model consistently outperforms competing approaches regarding data efficiency in exploration.