 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebias your Large Multi-Modal Model at Test-Time with Non-Contrastive Visual Attribute Steering
Paper and Code
Nov 15, 2024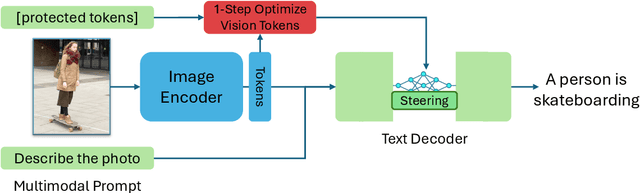
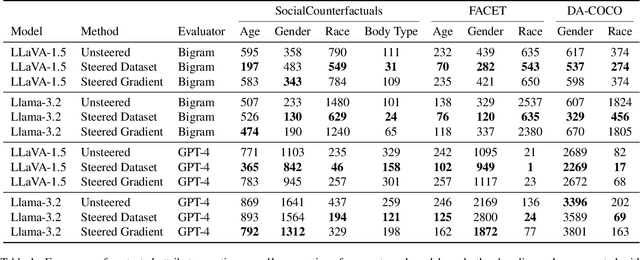
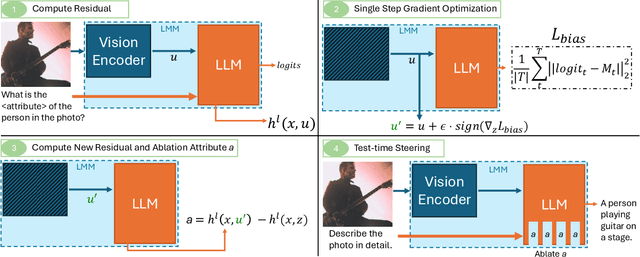
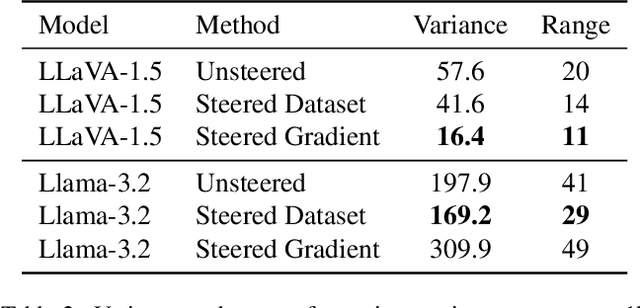
Large Multi-Modal Models (LMMs) have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input, such as an image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LMMs that directly removes biased representations during text generation to decrease outputs related to protected attributes, or even representing them internally. Our proposed method is training-free; given a single image and a list of target attributes, we can ablate the corresponding representations with just one step of gradient descent on the image itself. Our experiments show that not only can we can minimize the propensity of LMMs to generate text related to protected attributes, but we can improve sentiment and even simply use synthetic data to inform the ablation while retaining language modeling capabilities on real data such as COCO or FACET. Furthermore, we find the resulting generations from a debiased LMM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.