 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Interpretability for LLM-based Multi-Agent Reinforcement Learning
Feb 05, 2026Large language models (LLMs) are increasingly trained in complex Reinforcement Learning, multi-agent environments, making it difficult to understand how behavior changes over training. Sparse Autoencoders (SAEs) have recently shown to be useful for data-centric interpretability. In this work, we analyze large-scale reinforcement learning training runs from the sophisticated environment of Full-Press Diplomacy by applying pretrained SAEs, alongside LLM-summarizer methods. We introduce Meta-Autointerp, a method for grouping SAE features into interpretable hypotheses about training dynamics. We discover fine-grained behaviors including role-playing patterns, degenerate outputs, language switching, alongside high-level strategic behaviors and environment-specific bugs. Through automated evaluation, we validate that 90% of discovered SAE Meta-Features are significant, and find a surprising reward hacking behavior. However, through two user studies, we find that even subjectively interesting and seemingly helpful SAE features may be worse than useless to humans, along with most LLM generated hypotheses. However, a subset of SAE-derived hypotheses are predictively useful for downstream tasks. We further provide validation by augmenting an untrained agent's system prompt, improving the score by +14.2%. Overall, we show that SAEs and LLM-summarizer provide complementary views into agent behavior, and together our framework forms a practical starting point for future data-centric interpretability work on ensuring trustworthy LLM behavior throughout training.
Democratizing Diplomacy: A Harness for Evaluating Any Large Language Model on Full-Press Diplomacy
Aug 10, 2025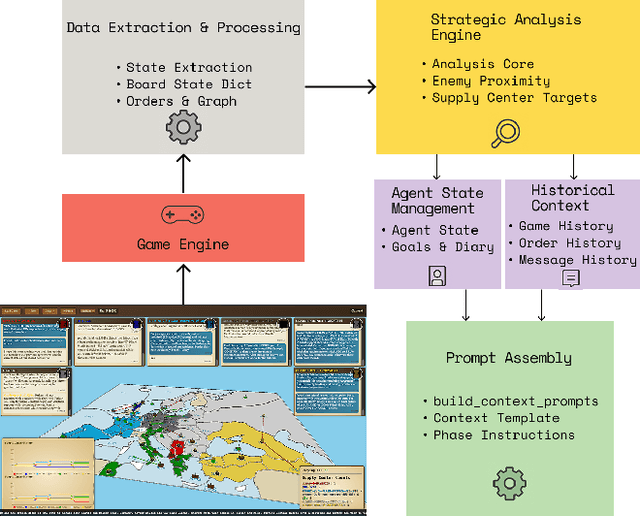



We present the first evaluation harness that enables any out-of-the-box, local, Large Language Models (LLMs) to play full-press Diplomacy without fine-tuning or specialized training. Previous work required frontier LLMs, or fine-tuning, due to the high complexity and information density of Diplomacy's game state. Combined with the high variance of matches, these factors made Diplomacy prohibitive for study. In this work, we used data-driven iteration to optimize a textual game state representation such that a 24B model can reliably complete matches without any fine tuning. We develop tooling to facilitate hypothesis testing and statistical analysis, and we present case studies on persuasion, aggressive playstyles, and performance across a range of models. We conduct a variety of experiments across many popular LLMs, finding the larger models perform the best, but the smaller models still play adequately. We also introduce Critical State Analysis: an experimental protocol for rapidly iterating and analyzing key moments in a game at depth. Our harness democratizes the evaluation of strategic reasoning in LLMs by eliminating the need for fine-tuning, and it provides insights into how these capabilities emerge naturally from widely used LLMs. Our code is available in the supplement and will be open sourced.
Analyzing Hierarchical Structure in Vision Models with Sparse Autoencoders
May 21, 2025The ImageNet hierarchy provides a structured taxonomy of object categories, offering a valuable lens through which to analyze the representations learned by deep vision models. In this work, we conduct a comprehensive analysis of how vision models encode the ImageNet hierarchy, leveraging Sparse Autoencoders (SAEs) to probe their internal representations. SAEs have been widely used as an explanation tool for large language models (LLMs), where they enable the discovery of semantically meaningful features. Here, we extend their use to vision models to investigate whether learned representations align with the ontological structure defined by the ImageNet taxonomy. Our results show that SAEs uncover hierarchical relationships in model activations, revealing an implicit encoding of taxonomic structure. We analyze the consistency of these representations across different layers of the popular vision foundation model DINOv2 and provide insights into how deep vision models internalize hierarchical category information by increasing information in the class token through each layer. Our study establishes a framework for systematic hierarchical analysis of vision model representations and highlights the potential of SAEs as a tool for probing semantic structure in deep networks.
Steering Large Language Models to Evaluate and Amplify Creativity
Dec 08, 2024Although capable of generating creative text, Large Language Models (LLMs) are poor judges of what constitutes "creativity". In this work, we show that we can leverage this knowledge of how to write creatively in order to better judge what is creative. We take a mechanistic approach that extracts differences in the internal states of an LLM when prompted to respond "boringly" or "creatively" to provide a robust measure of creativity that corresponds strongly with human judgment. We also show these internal state differences can be applied to enhance the creativity of generated text at inference time.
Debias your Large Multi-Modal Model at Test-Time with Non-Contrastive Visual Attribute Steering
Nov 15, 2024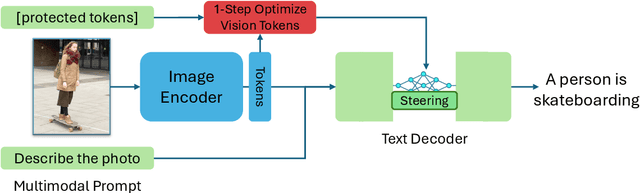
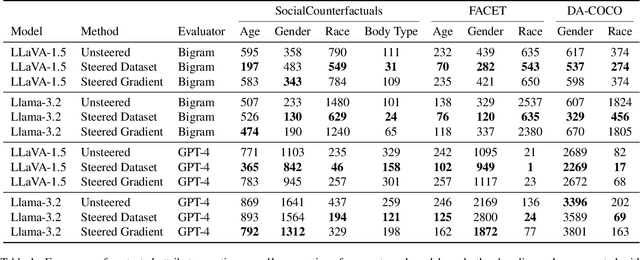
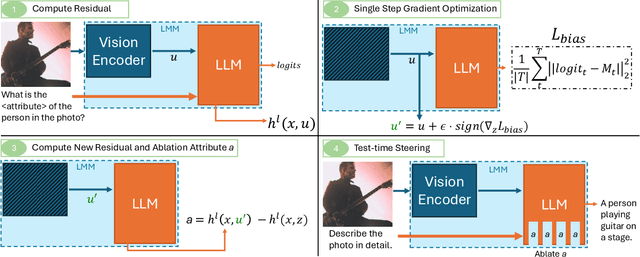
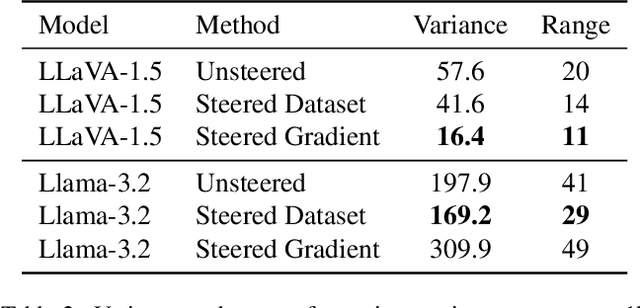
Large Multi-Modal Models (LMMs) have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input, such as an image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LMMs that directly removes biased representations during text generation to decrease outputs related to protected attributes, or even representing them internally. Our proposed method is training-free; given a single image and a list of target attributes, we can ablate the corresponding representations with just one step of gradient descent on the image itself. Our experiments show that not only can we can minimize the propensity of LMMs to generate text related to protected attributes, but we can improve sentiment and even simply use synthetic data to inform the ablation while retaining language modeling capabilities on real data such as COCO or FACET. Furthermore, we find the resulting generations from a debiased LMM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
Super-Resolution without High-Resolution Labels for Black Hole Simulations
Nov 03, 2024
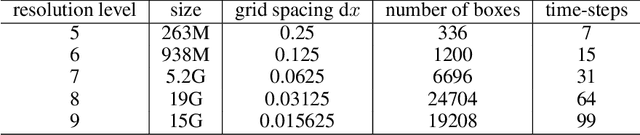

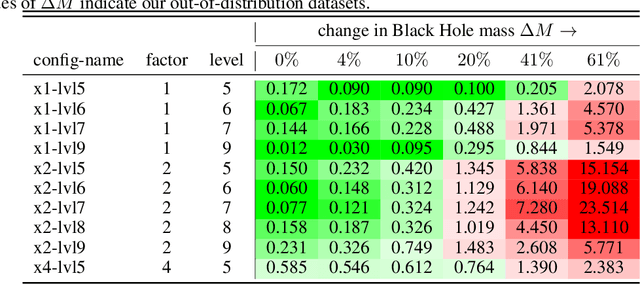
Generating high-resolution simulations is key for advancing our understanding of one of the universe's most violent events: Black Hole mergers. However, generating Black Hole simulations is limited by prohibitive computational costs and scalability issues, reducing the simulation's fidelity and resolution achievable within reasonable time frames and resources. In this work, we introduce a novel method that circumvents these limitations by applying a super-resolution technique without directly needing high-resolution labels, leveraging the Hamiltonian and momentum constraints-fundamental equations in general relativity that govern the dynamics of spacetime. We demonstrate that our method achieves a reduction in constraint violation by one to two orders of magnitude and generalizes effectively to out-of-distribution simulations.
Debiasing Large Vision-Language Models by Ablating Protected Attribute Representations
Oct 17, 2024



Large Vision Language Models (LVLMs) such as LLaVA have demonstrated impressive capabilities as general-purpose chatbots that can engage in conversations about a provided input image. However, their responses are influenced by societal biases present in their training datasets, leading to undesirable differences in how the model responds when presented with images depicting people of different demographics. In this work, we propose a novel debiasing framework for LVLMs by directly ablating biased attributes during text generation to avoid generating text related to protected attributes, or even representing them internally. Our method requires no training and a relatively small amount of representative biased outputs (~1000 samples). Our experiments show that not only can we can minimize the propensity of LVLMs to generate text related to protected attributes, but we can even use synthetic data to inform the ablation while retaining captioning performance on real data such as COCO. Furthermore, we find the resulting generations from a debiased LVLM exhibit similar accuracy as a baseline biased model, showing that debiasing effects can be achieved without sacrificing model performance.
ClimDetect: A Benchmark Dataset for Climate Change Detection and Attribution
Aug 28, 2024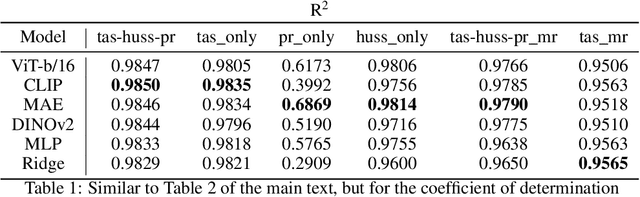
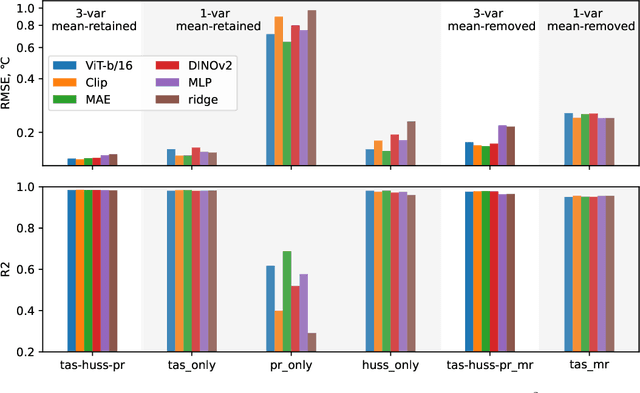
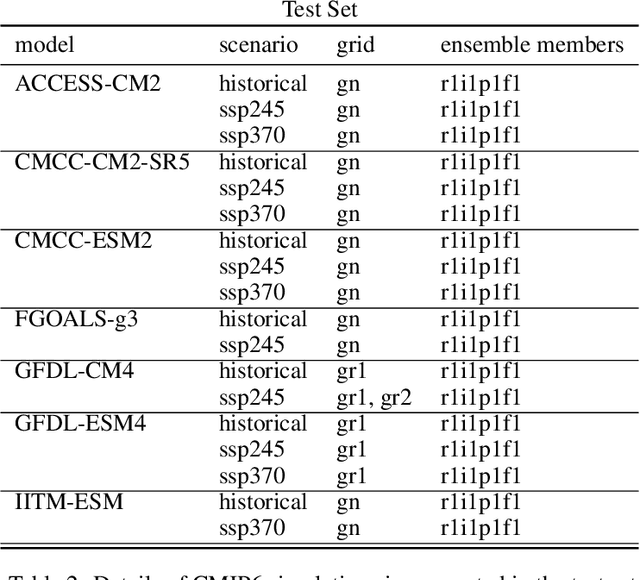
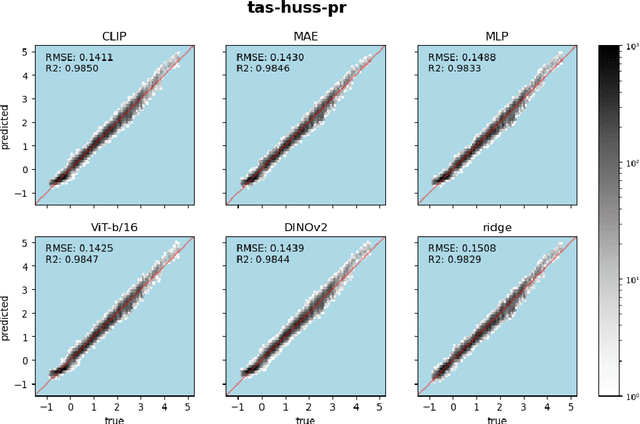
Detecting and attributing temperature increases due to climate change is crucial for understanding global warming and guiding adaptation strategies. The complexity of distinguishing human-induced climate signals from natural variability has challenged traditional detection and attribution (D&A) approaches, which seek to identify specific "fingerprints" in climate response variables. Deep learning offers potential for discerning these complex patterns in expansive spatial datasets. However, lack of standard protocols has hindered consistent comparisons across studies. We introduce ClimDetect, a standardized dataset of over 816k daily climate snapshots, designed to enhance model accuracy in identifying climate change signals. ClimDetect integrates various input and target variables used in past research, ensuring comparability and consistency. We also explore the application of vision transformers (ViT) to climate data, a novel and modernizing approach in this context. Our open-access data and code serve as a benchmark for advancing climate science through improved model evaluations. ClimDetect is publicly accessible via Huggingface dataet respository at: https://huggingface.co/datasets/ClimDetect/ClimDetect.
Why do LLaVA Vision-Language Models Reply to Images in English?
Jul 02, 2024
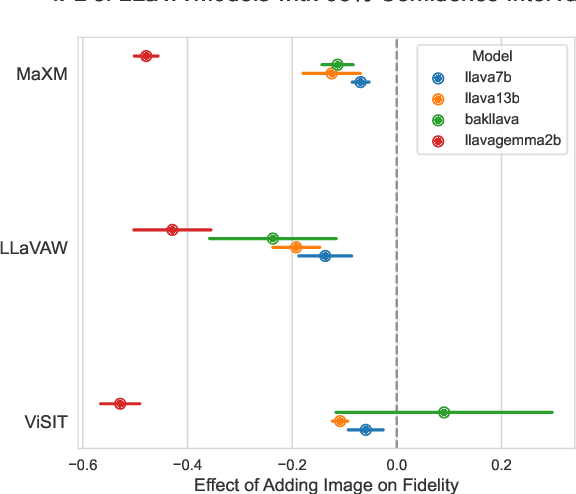
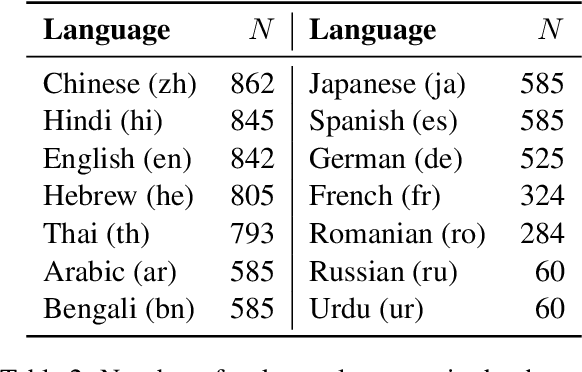
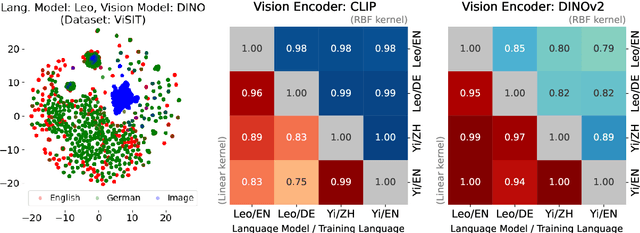
We uncover a surprising multilingual bias occurring in a popular class of multimodal vision-language models (VLMs). Including an image in the query to a LLaVA-style VLM significantly increases the likelihood of the model returning an English response, regardless of the language of the query. This paper investigates the causes of this loss with a two-pronged approach that combines extensive ablation of the design space with a mechanistic analysis of the models' internal representations of image and text inputs. Both approaches indicate that the issue stems in the language modelling component of the LLaVA model. Statistically, we find that switching the language backbone for a bilingual language model has the strongest effect on reducing this error. Mechanistically, we provide compelling evidence that visual inputs are not mapped to a similar space as text ones, and that intervening on intermediary attention layers can reduce this bias. Our findings provide important insights to researchers and engineers seeking to understand the crossover between multimodal and multilingual spaces, and contribute to the goal of developing capable and inclusive VLMs for non-English contexts.
LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
Apr 03, 2024



In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.