 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Climate Emulation with Bayesian Filtering
Jun 11, 2025Traditional models of climate change use complex systems of coupled equations to simulate physical processes across the Earth system. These simulations are highly computationally expensive, limiting our predictions of climate change and analyses of its causes and effects. Machine learning has the potential to quickly emulate data from climate models, but current approaches are not able to incorporate physics-informed causal relationships. Here, we develop an interpretable climate model emulator based on causal representation learning. We derive a physics-informed approach including a Bayesian filter for stable long-term autoregressive emulation. We demonstrate that our emulator learns accurate climate dynamics, and we show the importance of each one of its components on a realistic synthetic dataset and data from two widely deployed climate models.
Causal World Representation in the GPT Model
Dec 10, 2024Are generative pre-trained transformer (GPT) models only trained to predict the next token, or do they implicitly learn a world model from which a sequence is generated one token at a time? We examine this question by deriving a causal interpretation of the attention mechanism in GPT, and suggesting a causal world model that arises from this interpretation. Furthermore, we propose that GPT-models, at inference time, can be utilized for zero-shot causal structure learning for in-distribution sequences. Empirical evaluation is conducted in a controlled synthetic environment using the setup and rules of the Othello board game. A GPT, pre-trained on real-world games played with the intention of winning, is tested on synthetic data that only adheres to the game rules. We find that the GPT model tends to generate next moves that adhere to the game rules for sequences for which the attention mechanism encodes a causal structure with high confidence. In general, in cases for which the GPT model generates moves that do not adhere to the game rules, it also fails to capture any causal structure.
Causal Representation Learning in Temporal Data via Single-Parent Decoding
Oct 09, 2024



Scientific research often seeks to understand the causal structure underlying high-level variables in a system. For example, climate scientists study how phenomena, such as El Ni\~no, affect other climate processes at remote locations across the globe. However, scientists typically collect low-level measurements, such as geographically distributed temperature readings. From these, one needs to learn both a mapping to causally-relevant latent variables, such as a high-level representation of the El Ni\~no phenomenon and other processes, as well as the causal model over them. The challenge is that this task, called causal representation learning, is highly underdetermined from observational data alone, requiring other constraints during learning to resolve the indeterminacies. In this work, we consider a temporal model with a sparsity assumption, namely single-parent decoding: each observed low-level variable is only affected by a single latent variable. Such an assumption is reasonable in many scientific applications that require finding groups of low-level variables, such as extracting regions from geographically gridded measurement data in climate research or capturing brain regions from neural activity data. We demonstrate the identifiability of the resulting model and propose a differentiable method, Causal Discovery with Single-parent Decoding (CDSD), that simultaneously learns the underlying latents and a causal graph over them. We assess the validity of our theoretical results using simulated data and showcase the practical validity of our method in an application to real-world data from the climate science field.
LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
Apr 03, 2024



In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.
Towards Causal Representations of Climate Model Data
Dec 06, 2023

Climate models, such as Earth system models (ESMs), are crucial for simulating future climate change based on projected Shared Socioeconomic Pathways (SSP) greenhouse gas emissions scenarios. While ESMs are sophisticated and invaluable, machine learning-based emulators trained on existing simulation data can project additional climate scenarios much faster and are computationally efficient. However, they often lack generalizability and interpretability. This work delves into the potential of causal representation learning, specifically the \emph{Causal Discovery with Single-parent Decoding} (CDSD) method, which could render climate model emulation efficient \textit{and} interpretable. We evaluate CDSD on multiple climate datasets, focusing on emissions, temperature, and precipitation. Our findings shed light on the challenges, limitations, and promise of using CDSD as a stepping stone towards more interpretable and robust climate model emulation.
ClimateSet: A Large-Scale Climate Model Dataset for Machine Learning
Nov 07, 2023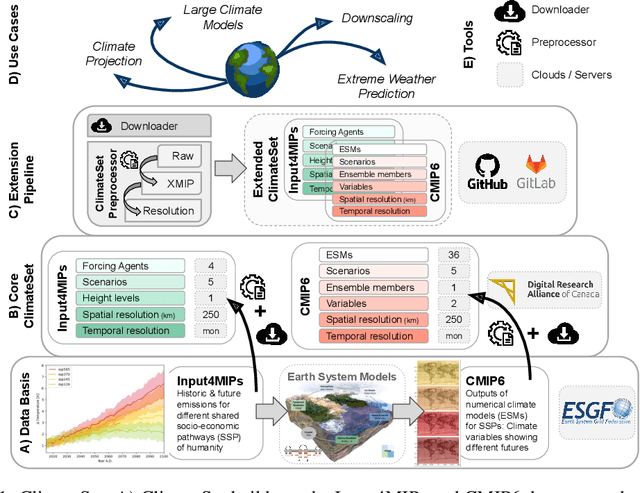
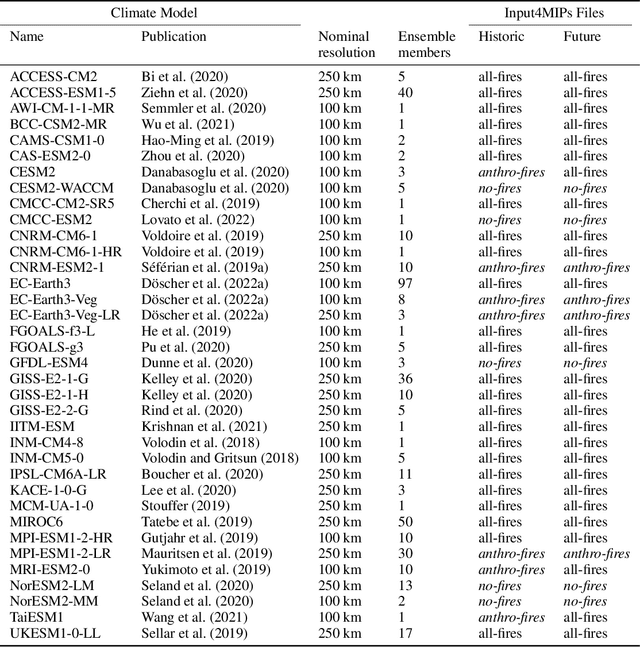
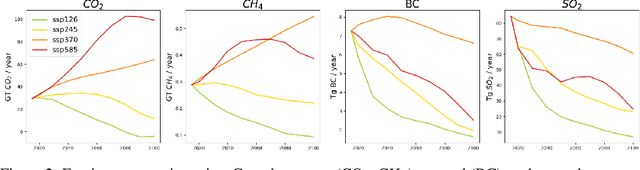
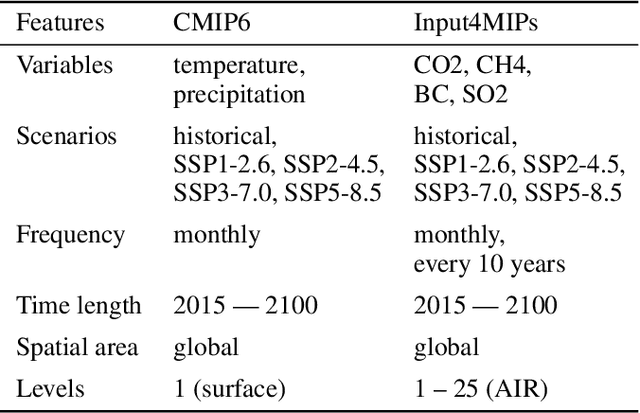
Climate models have been key for assessing the impact of climate change and simulating future climate scenarios. The machine learning (ML) community has taken an increased interest in supporting climate scientists' efforts on various tasks such as climate model emulation, downscaling, and prediction tasks. Many of those tasks have been addressed on datasets created with single climate models. However, both the climate science and ML communities have suggested that to address those tasks at scale, we need large, consistent, and ML-ready climate model datasets. Here, we introduce ClimateSet, a dataset containing the inputs and outputs of 36 climate models from the Input4MIPs and CMIP6 archives. In addition, we provide a modular dataset pipeline for retrieving and preprocessing additional climate models and scenarios. We showcase the potential of our dataset by using it as a benchmark for ML-based climate model emulation. We gain new insights about the performance and generalization capabilities of the different ML models by analyzing their performance across different climate models. Furthermore, the dataset can be used to train an ML emulator on several climate models instead of just one. Such a "super emulator" can quickly project new climate change scenarios, complementing existing scenarios already provided to policymakers. We believe ClimateSet will create the basis needed for the ML community to tackle climate-related tasks at scale.
Causal Interpretation of Self-Attention in Pre-Trained Transformers
Oct 31, 2023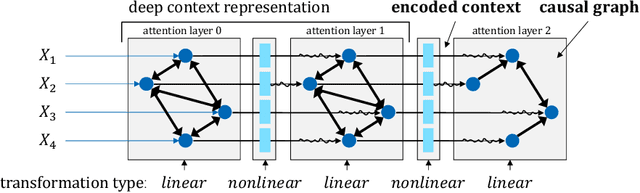
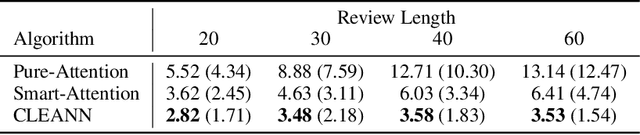


We propose a causal interpretation of self-attention in the Transformer neural network architecture. We interpret self-attention as a mechanism that estimates a structural equation model for a given input sequence of symbols (tokens). The structural equation model can be interpreted, in turn, as a causal structure over the input symbols under the specific context of the input sequence. Importantly, this interpretation remains valid in the presence of latent confounders. Following this interpretation, we estimate conditional independence relations between input symbols by calculating partial correlations between their corresponding representations in the deepest attention layer. This enables learning the causal structure over an input sequence using existing constraint-based algorithms. In this sense, existing pre-trained Transformers can be utilized for zero-shot causal-discovery. We demonstrate this method by providing causal explanations for the outcomes of Transformers in two tasks: sentiment classification (NLP) and recommendation.
From Temporal to Contemporaneous Iterative Causal Discovery in the Presence of Latent Confounders
Jun 01, 2023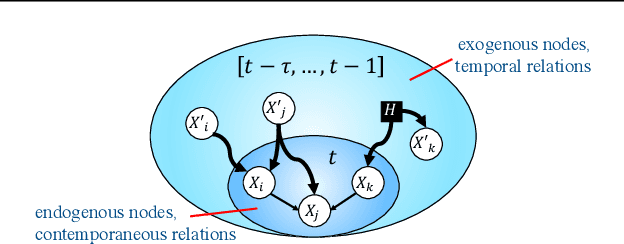
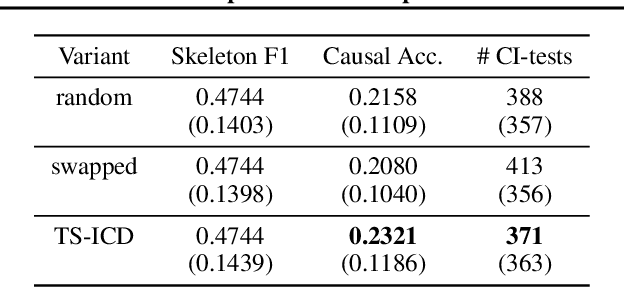
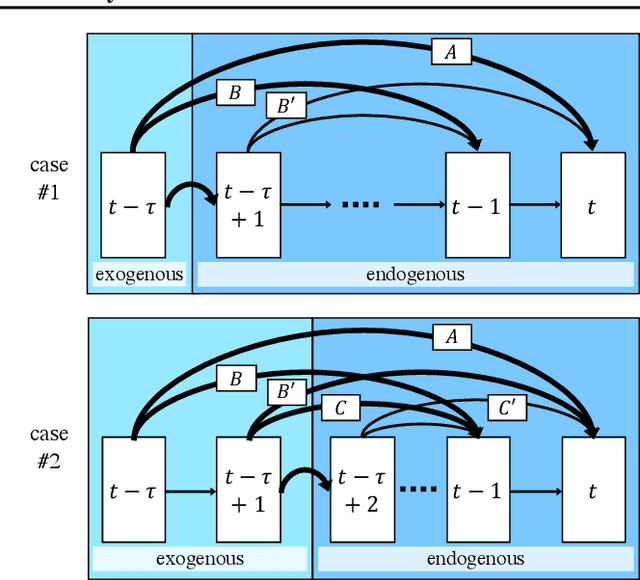
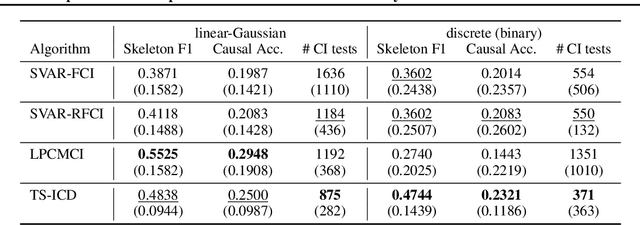
We present a constraint-based algorithm for learning causal structures from observational time-series data, in the presence of latent confounders. We assume a discrete-time, stationary structural vector autoregressive process, with both temporal and contemporaneous causal relations. One may ask if temporal and contemporaneous relations should be treated differently. The presented algorithm gradually refines a causal graph by learning long-term temporal relations before short-term ones, where contemporaneous relations are learned last. This ordering of causal relations to be learnt leads to a reduction in the required number of statistical tests. We validate this reduction empirically and demonstrate that it leads to higher accuracy for synthetic data and more plausible causal graphs for real-world data compared to state-of-the-art algorithms.
Iterative Causal Discovery in the Possible Presence of Latent Confounders and Selection Bias
Nov 07, 2021
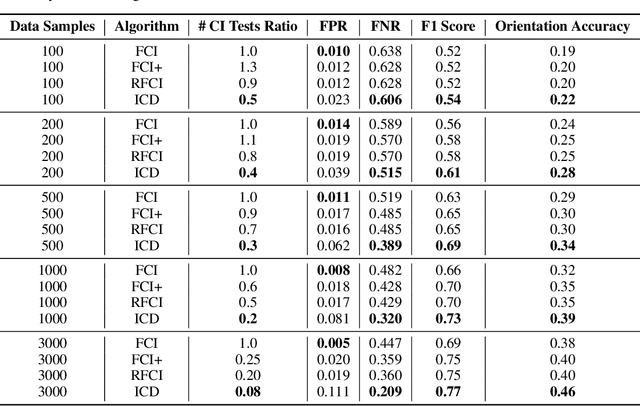
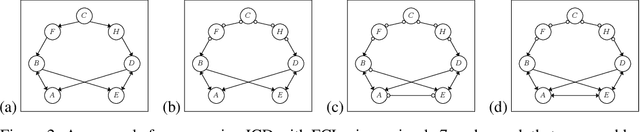
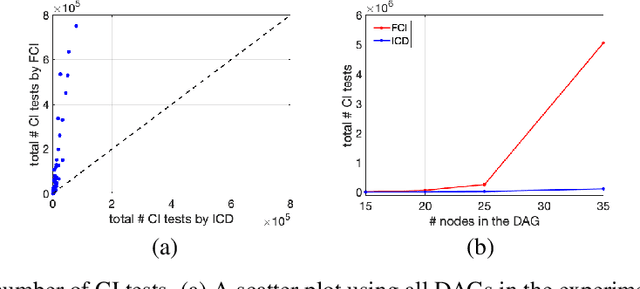
We present a sound and complete algorithm, called iterative causal discovery (ICD), for recovering causal graphs in the presence of latent confounders and selection bias. ICD relies on the causal Markov and faithfulness assumptions and recovers the equivalence class of the underlying causal graph. It starts with a complete graph, and consists of a single iterative stage that gradually refines this graph by identifying conditional independence (CI) between connected nodes. Independence and causal relations entailed after any iteration are correct, rendering ICD anytime. Essentially, we tie the size of the CI conditioning set to its distance on the graph from the tested nodes, and increase this value in the successive iteration. Thus, each iteration refines a graph that was recovered by previous iterations having smaller conditioning sets -- a higher statistical power -- which contributes to stability. We demonstrate empirically that ICD requires significantly fewer CI tests and learns more accurate causal graphs compared to FCI, FCI+, and RFCI algorithms.
Improving Efficiency and Accuracy of Causal Discovery Using a Hierarchical Wrapper
Jul 11, 2021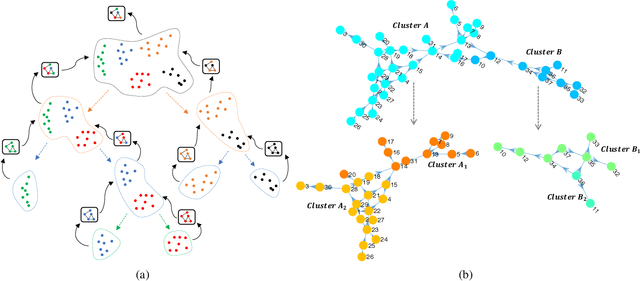
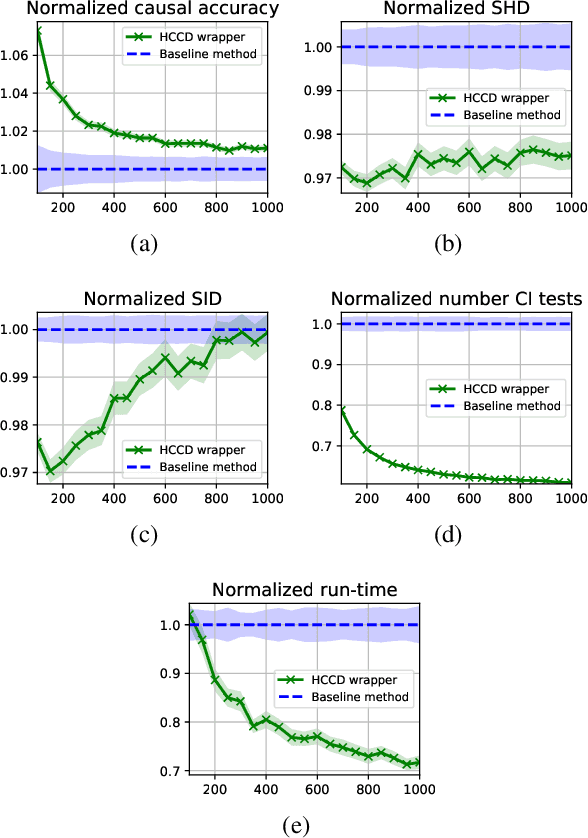
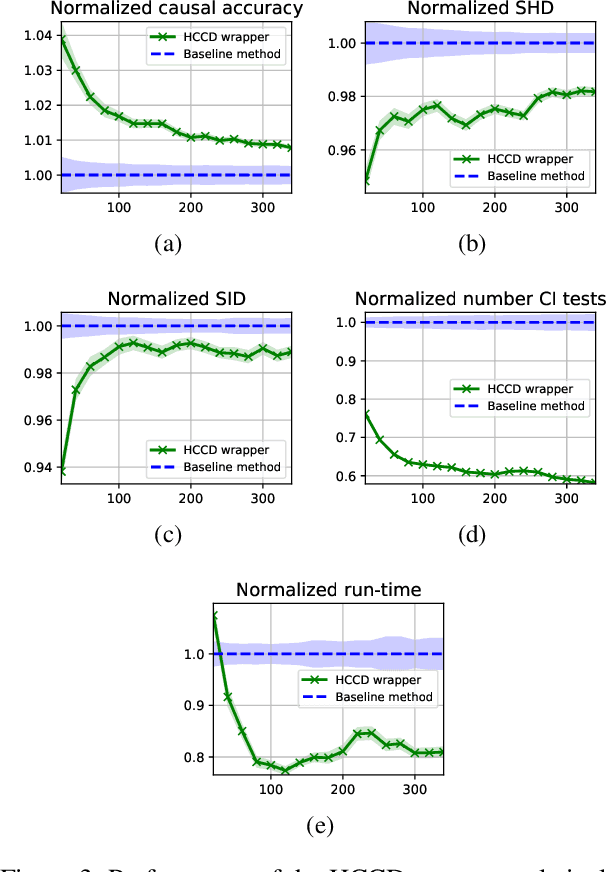
Causal discovery from observational data is an important tool in many branches of science. Under certain assumptions it allows scientists to explain phenomena, predict, and make decisions. In the large sample limit, sound and complete causal discovery algorithms have been previously introduced, where a directed acyclic graph (DAG), or its equivalence class, representing causal relations is searched. However, in real-world cases, only finite training data is available, which limits the power of statistical tests used by these algorithms, leading to errors in the inferred causal model. This is commonly addressed by devising a strategy for using as few as possible statistical tests. In this paper, we introduce such a strategy in the form of a recursive wrapper for existing constraint-based causal discovery algorithms, which preserves soundness and completeness. It recursively clusters the observed variables using the normalized min-cut criterion from the outset, and uses a baseline causal discovery algorithm during backtracking for learning local sub-graphs. It then combines them and ensures completeness. By an ablation study, using synthetic data, and by common real-world benchmarks, we demonstrate that our approach requires significantly fewer statistical tests, learns more accurate graphs, and requires shorter run-times than the baseline algorithm.