 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Guards the Guardians? The Challenges of Evaluating Identifiability of Learned Representations
Feb 27, 2026Identifiability in representation learning is commonly evaluated using standard metrics (e.g., MCC, DCI, R^2) on synthetic benchmarks with known ground-truth factors. These metrics are assumed to reflect recovery up to the equivalence class guaranteed by identifiability theory. We show that this assumption holds only under specific structural conditions: each metric implicitly encodes assumptions about both the data-generating process (DGP) and the encoder. When these assumptions are violated, metrics become misspecified and can produce systematic false positives and false negatives. Such failures occur both within classical identifiability regimes and in post-hoc settings where identifiability is most needed. We introduce a taxonomy separating DGP assumptions from encoder geometry, use it to characterise the validity domains of existing metrics, and release an evaluation suite for reproducible stress testing and comparison.
The Landscape of Causal Discovery Data: Grounding Causal Discovery in Real-World Applications
Dec 02, 2024

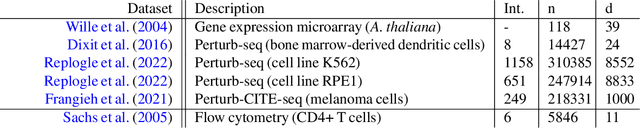

Causal discovery aims to automatically uncover causal relationships from data, a capability with significant potential across many scientific disciplines. However, its real-world applications remain limited. Current methods often rely on unrealistic assumptions and are evaluated only on simple synthetic toy datasets, often with inadequate evaluation metrics. In this paper, we substantiate these claims by performing a systematic review of the recent causal discovery literature. We present applications in biology, neuroscience, and Earth sciences - fields where causal discovery holds promise for addressing key challenges. We highlight available simulated and real-world datasets from these domains and discuss common assumption violations that have spurred the development of new methods. Our goal is to encourage the community to adopt better evaluation practices by utilizing realistic datasets and more adequate metrics.
Causal Representation Learning in Temporal Data via Single-Parent Decoding
Oct 09, 2024



Scientific research often seeks to understand the causal structure underlying high-level variables in a system. For example, climate scientists study how phenomena, such as El Ni\~no, affect other climate processes at remote locations across the globe. However, scientists typically collect low-level measurements, such as geographically distributed temperature readings. From these, one needs to learn both a mapping to causally-relevant latent variables, such as a high-level representation of the El Ni\~no phenomenon and other processes, as well as the causal model over them. The challenge is that this task, called causal representation learning, is highly underdetermined from observational data alone, requiring other constraints during learning to resolve the indeterminacies. In this work, we consider a temporal model with a sparsity assumption, namely single-parent decoding: each observed low-level variable is only affected by a single latent variable. Such an assumption is reasonable in many scientific applications that require finding groups of low-level variables, such as extracting regions from geographically gridded measurement data in climate research or capturing brain regions from neural activity data. We demonstrate the identifiability of the resulting model and propose a differentiable method, Causal Discovery with Single-parent Decoding (CDSD), that simultaneously learns the underlying latents and a causal graph over them. We assess the validity of our theoretical results using simulated data and showcase the practical validity of our method in an application to real-world data from the climate science field.
Towards Causal Representations of Climate Model Data
Dec 06, 2023

Climate models, such as Earth system models (ESMs), are crucial for simulating future climate change based on projected Shared Socioeconomic Pathways (SSP) greenhouse gas emissions scenarios. While ESMs are sophisticated and invaluable, machine learning-based emulators trained on existing simulation data can project additional climate scenarios much faster and are computationally efficient. However, they often lack generalizability and interpretability. This work delves into the potential of causal representation learning, specifically the \emph{Causal Discovery with Single-parent Decoding} (CDSD) method, which could render climate model emulation efficient \textit{and} interpretable. We evaluate CDSD on multiple climate datasets, focusing on emissions, temperature, and precipitation. Our findings shed light on the challenges, limitations, and promise of using CDSD as a stepping stone towards more interpretable and robust climate model emulation.
ClimateSet: A Large-Scale Climate Model Dataset for Machine Learning
Nov 07, 2023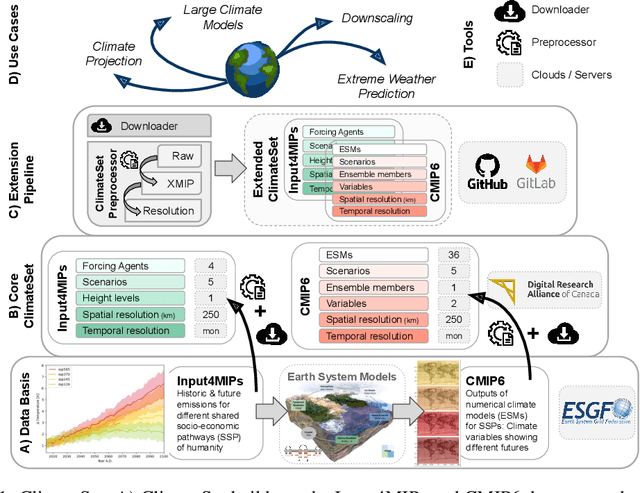
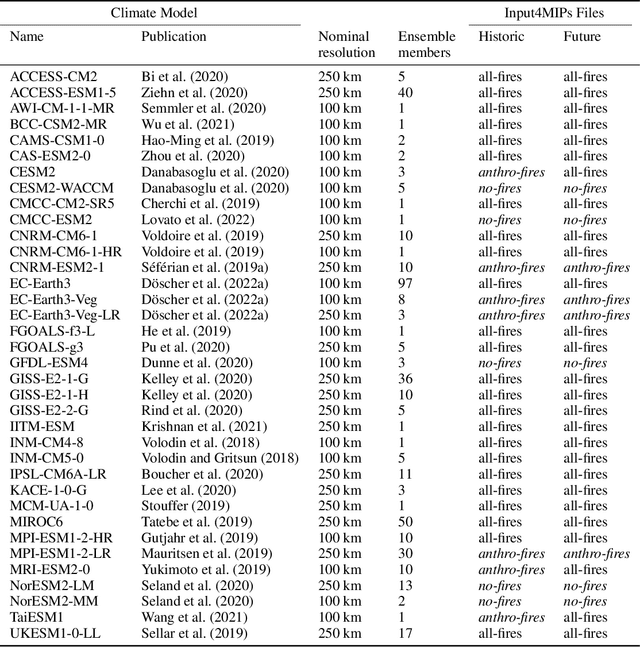
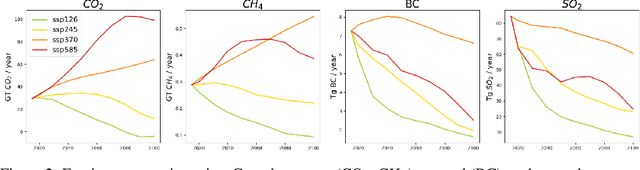
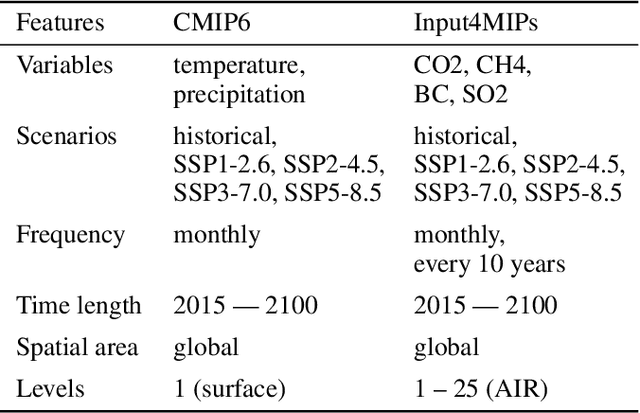
Climate models have been key for assessing the impact of climate change and simulating future climate scenarios. The machine learning (ML) community has taken an increased interest in supporting climate scientists' efforts on various tasks such as climate model emulation, downscaling, and prediction tasks. Many of those tasks have been addressed on datasets created with single climate models. However, both the climate science and ML communities have suggested that to address those tasks at scale, we need large, consistent, and ML-ready climate model datasets. Here, we introduce ClimateSet, a dataset containing the inputs and outputs of 36 climate models from the Input4MIPs and CMIP6 archives. In addition, we provide a modular dataset pipeline for retrieving and preprocessing additional climate models and scenarios. We showcase the potential of our dataset by using it as a benchmark for ML-based climate model emulation. We gain new insights about the performance and generalization capabilities of the different ML models by analyzing their performance across different climate models. Furthermore, the dataset can be used to train an ML emulator on several climate models instead of just one. Such a "super emulator" can quickly project new climate change scenarios, complementing existing scenarios already provided to policymakers. We believe ClimateSet will create the basis needed for the ML community to tackle climate-related tasks at scale.
Typing assumptions improve identification in causal discovery
Jul 22, 2021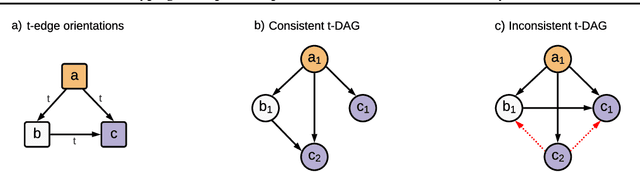
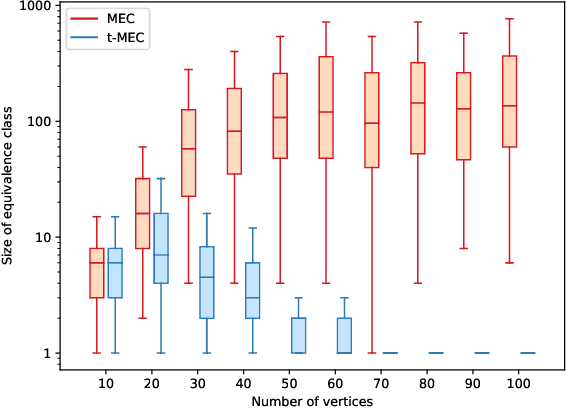
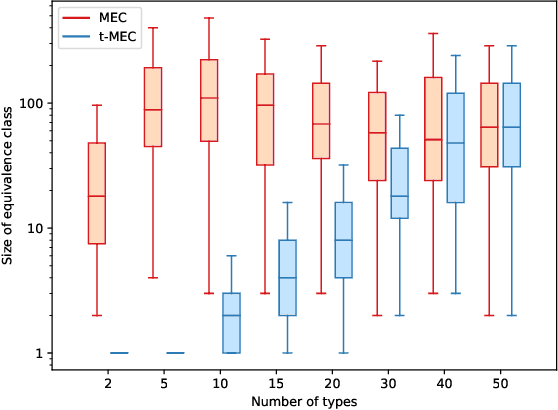
Causal discovery from observational data is a challenging task to which an exact solution cannot always be identified. Under assumptions about the data-generative process, the causal graph can often be identified up to an equivalence class. Proposing new realistic assumptions to circumscribe such equivalence classes is an active field of research. In this work, we propose a new set of assumptions that constrain possible causal relationships based on the nature of the variables. We thus introduce typed directed acyclic graphs, in which variable types are used to determine the validity of causal relationships. We demonstrate, both theoretically and empirically, that the proposed assumptions can result in significant gains in the identification of the causal graph.
Differentiable Causal Discovery from Interventional Data
Jul 03, 2020

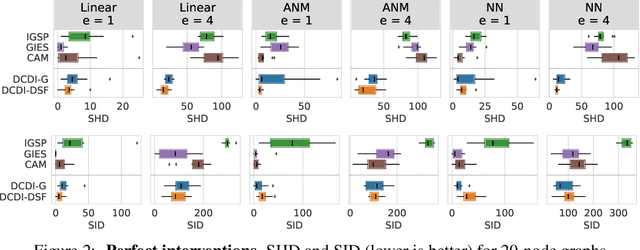

Discovering causal relationships in data is a challenging task that involves solving a combinatorial problem for which the solution is not always identifiable. A new line of work reformulates the combinatorial problem as a continuous constrained optimization one, enabling the use of different powerful optimization techniques. However, methods based on this idea do not yet make use of interventional data, which can significantly alleviate identifiability issues. In this work, we propose a neural network-based method for this task that can leverage interventional data. We illustrate the flexibility of the continuous-constrained framework by taking advantage of expressive neural architectures such as normalizing flows. We show that our approach compares favorably to the state of the art in a variety of settings, including perfect and imperfect interventions for which the targeted nodes may even be unknown.
Gradient-Based Neural DAG Learning
Jun 05, 2019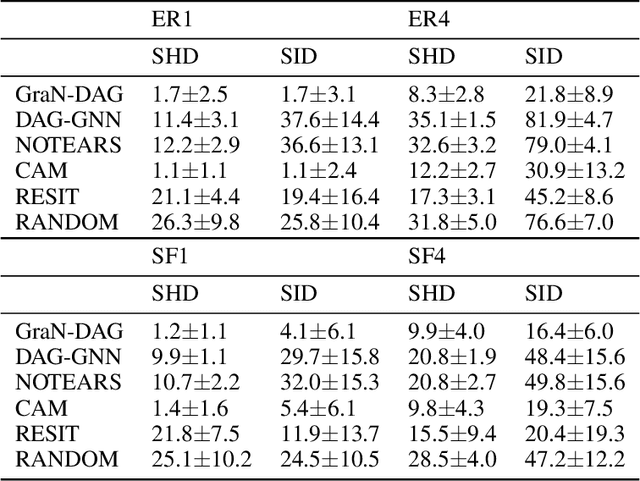
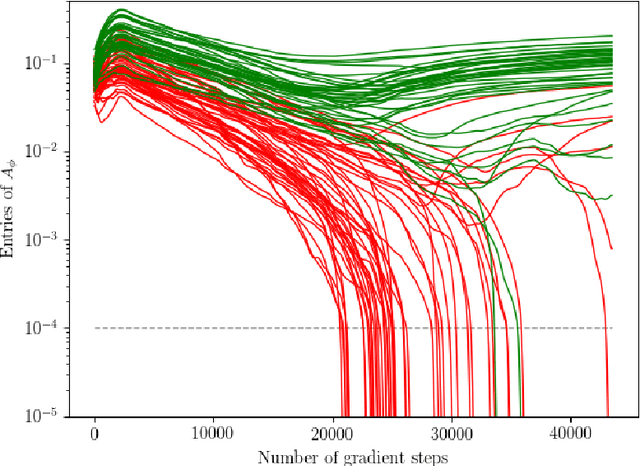
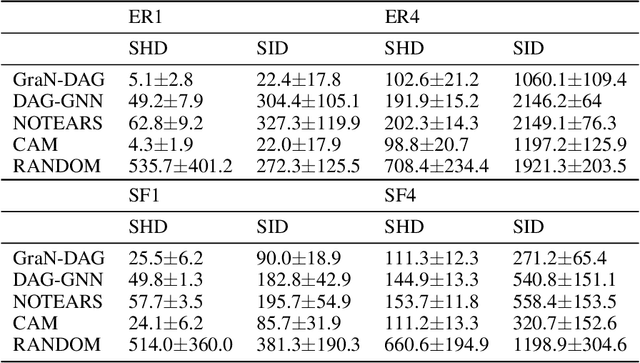
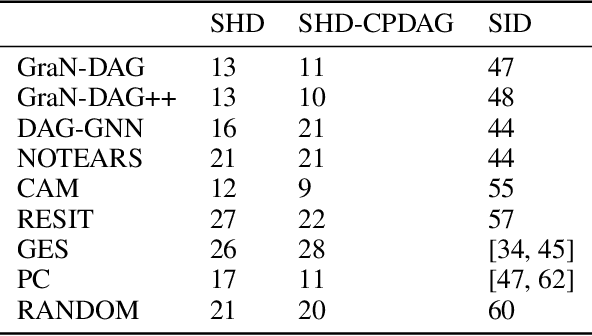
We propose a novel score-based approach to learning a directed acyclic graph (DAG) from observational data. We adapt a recently proposed continuous constrained optimization formulation to allow for nonlinear relationships between variables using neural networks. This extension allows to model complex interactions while being more global in its search compared to other greedy approaches. In addition to comparing our method to existing continuous optimization methods, we provide missing empirical comparisons to nonlinear greedy search methods. On both synthetic and real-world data sets, this new method outperforms current continuous methods on most tasks while being competitive with existing greedy search methods on important metrics for causal inference.