 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Large Language Models to Evaluate and Amplify Creativity
Dec 08, 2024Although capable of generating creative text, Large Language Models (LLMs) are poor judges of what constitutes "creativity". In this work, we show that we can leverage this knowledge of how to write creatively in order to better judge what is creative. We take a mechanistic approach that extracts differences in the internal states of an LLM when prompted to respond "boringly" or "creatively" to provide a robust measure of creativity that corresponds strongly with human judgment. We also show these internal state differences can be applied to enhance the creativity of generated text at inference time.
KD-VLP: Improving End-to-End Vision-and-Language Pretraining with Object Knowledge Distillation
Sep 22, 2021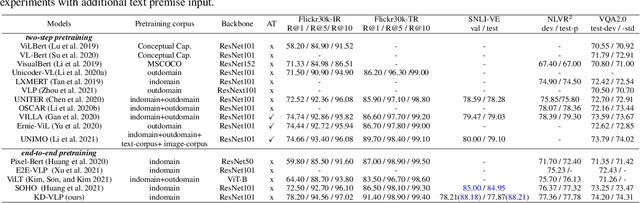



Self-supervised vision-and-language pretraining (VLP) aims to learn transferable multi-modal representations from large-scale image-text data and to achieve strong performances on a broad scope of vision-language tasks after finetuning. Previous mainstream VLP approaches typically adopt a two-step strategy relying on external object detectors to encode images in a multi-modal Transformer framework, which suffer from restrictive object concept space, limited image context and inefficient computation. In this paper, we propose an object-aware end-to-end VLP framework, which directly feeds image grid features from CNNs into the Transformer and learns the multi-modal representations jointly. More importantly, we propose to perform object knowledge distillation to facilitate learning cross-modal alignment at different semantic levels. To achieve that, we design two novel pretext tasks by taking object features and their semantic labels from external detectors as supervision: 1.) Object-guided masked vision modeling task focuses on enforcing object-aware representation learning in the multi-modal Transformer; 2.) Phrase-region alignment task aims to improve cross-modal alignment by utilizing the similarities between noun phrases and object labels in the linguistic space. Extensive experiments on a wide range of vision-language tasks demonstrate the efficacy of our proposed framework, and we achieve competitive or superior performances over the existing pretraining strategies. The code is available in supplementary materials.