 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Resolution without High-Resolution Labels for Black Hole Simulations
Nov 03, 2024
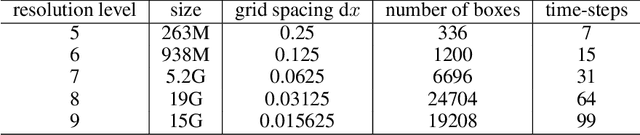

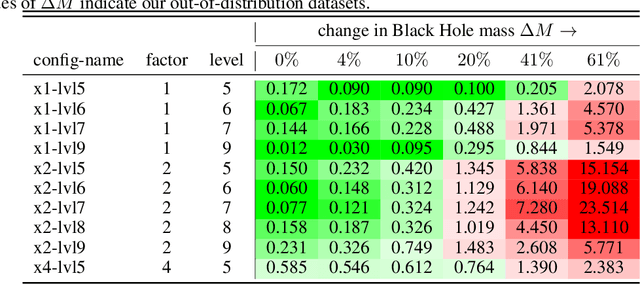
Generating high-resolution simulations is key for advancing our understanding of one of the universe's most violent events: Black Hole mergers. However, generating Black Hole simulations is limited by prohibitive computational costs and scalability issues, reducing the simulation's fidelity and resolution achievable within reasonable time frames and resources. In this work, we introduce a novel method that circumvents these limitations by applying a super-resolution technique without directly needing high-resolution labels, leveraging the Hamiltonian and momentum constraints-fundamental equations in general relativity that govern the dynamics of spacetime. We demonstrate that our method achieves a reduction in constraint violation by one to two orders of magnitude and generalizes effectively to out-of-distribution simulations.
Maven: A Multimodal Foundation Model for Supernova Science
Aug 29, 2024



A common setting in astronomy is the availability of a small number of high-quality observations, and larger amounts of either lower-quality observations or synthetic data from simplified models. Time-domain astrophysics is a canonical example of this imbalance, with the number of supernovae observed photometrically outpacing the number observed spectroscopically by multiple orders of magnitude. At the same time, no data-driven models exist to understand these photometric and spectroscopic observables in a common context. Contrastive learning objectives, which have grown in popularity for aligning distinct data modalities in a shared embedding space, provide a potential solution to extract information from these modalities. We present Maven, the first foundation model for supernova science. To construct Maven, we first pre-train our model to align photometry and spectroscopy from 0.5M synthetic supernovae using a constrastive objective. We then fine-tune the model on 4,702 observed supernovae from the Zwicky Transient Facility. Maven reaches state-of-the-art performance on both classification and redshift estimation, despite the embeddings not being explicitly optimized for these tasks. Through ablation studies, we show that pre-training with synthetic data improves overall performance. In the upcoming era of the Vera C. Rubin Observatory, Maven serves as a Rosetta Stone for leveraging large, unlabeled and multimodal time-domain datasets.