 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaven: A Multimodal Foundation Model for Supernova Science
Aug 29, 2024



A common setting in astronomy is the availability of a small number of high-quality observations, and larger amounts of either lower-quality observations or synthetic data from simplified models. Time-domain astrophysics is a canonical example of this imbalance, with the number of supernovae observed photometrically outpacing the number observed spectroscopically by multiple orders of magnitude. At the same time, no data-driven models exist to understand these photometric and spectroscopic observables in a common context. Contrastive learning objectives, which have grown in popularity for aligning distinct data modalities in a shared embedding space, provide a potential solution to extract information from these modalities. We present Maven, the first foundation model for supernova science. To construct Maven, we first pre-train our model to align photometry and spectroscopy from 0.5M synthetic supernovae using a constrastive objective. We then fine-tune the model on 4,702 observed supernovae from the Zwicky Transient Facility. Maven reaches state-of-the-art performance on both classification and redshift estimation, despite the embeddings not being explicitly optimized for these tasks. Through ablation studies, we show that pre-training with synthetic data improves overall performance. In the upcoming era of the Vera C. Rubin Observatory, Maven serves as a Rosetta Stone for leveraging large, unlabeled and multimodal time-domain datasets.
Machine Learning and Cosmology
Mar 15, 2022Methods based on machine learning have recently made substantial inroads in many corners of cosmology. Through this process, new computational tools, new perspectives on data collection, model development, analysis, and discovery, as well as new communities and educational pathways have emerged. Despite rapid progress, substantial potential at the intersection of cosmology and machine learning remains untapped. In this white paper, we summarize current and ongoing developments relating to the application of machine learning within cosmology and provide a set of recommendations aimed at maximizing the scientific impact of these burgeoning tools over the coming decade through both technical development as well as the fostering of emerging communities.
A Deep Learning Approach for Active Anomaly Detection of Extragalactic Transients
Mar 22, 2021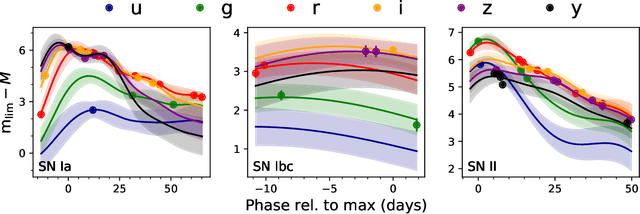
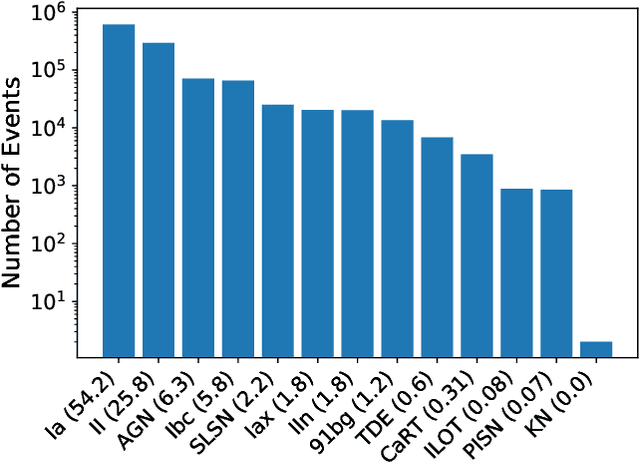
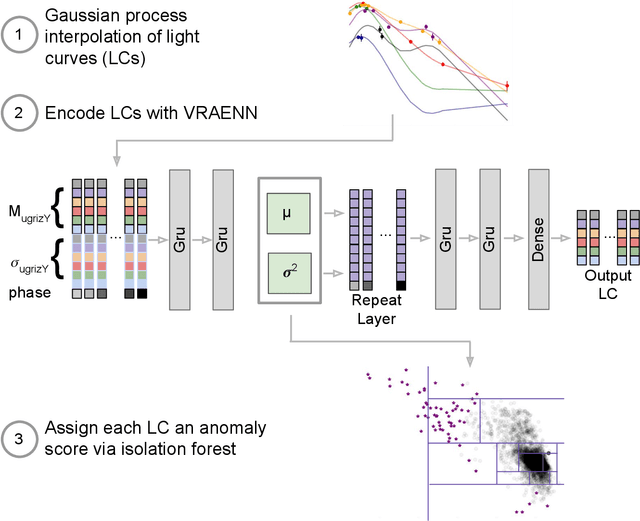
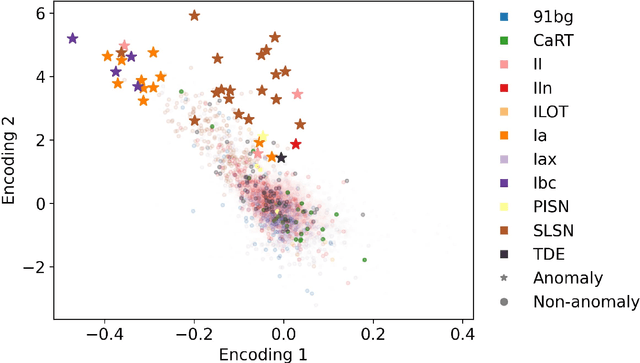
There is a shortage of multi-wavelength and spectroscopic followup capabilities given the number of transient and variable astrophysical events discovered through wide-field, optical surveys such as the upcoming Vera C. Rubin Observatory. From the haystack of potential science targets, astronomers must allocate scarce resources to study a selection of needles in real time. Here we present a variational recurrent autoencoder neural network to encode simulated Rubin Observatory extragalactic transient events using 1% of the PLAsTiCC dataset to train the autoencoder. Our unsupervised method uniquely works with unlabeled, real time, multivariate and aperiodic data. We rank 1,129,184 events based on an anomaly score estimated using an isolation forest. We find that our pipeline successfully ranks rarer classes of transients as more anomalous. Using simple cuts in anomaly score and uncertainty, we identify a pure (~95% pure) sample of rare transients (i.e., transients other than Type Ia, Type II and Type Ibc supernovae) including superluminous and pair-instability supernovae. Finally, our algorithm is able to identify these transients as anomalous well before peak, enabling real-time follow up studies in the era of the Rubin Observatory.
Anomaly Detection for Multivariate Time Series of Exotic Supernovae
Oct 21, 2020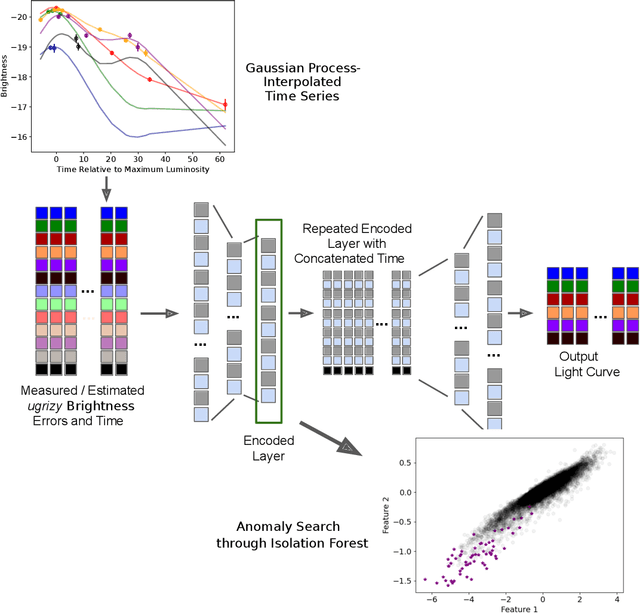
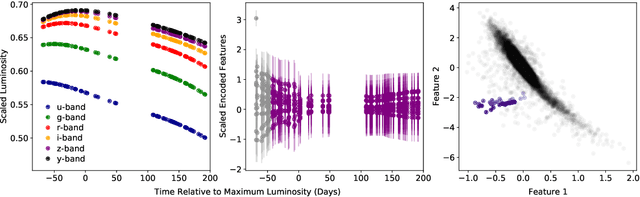
Supernovae mark the explosive deaths of stars and enrich the cosmos with heavy elements. Future telescopes will discover thousands of new supernovae nightly, creating a need to flag astrophysically interesting events rapidly for followup study. Ideally, such an anomaly detection pipeline would be independent of our current knowledge and be sensitive to unexpected phenomena. Here we present an unsupervised method to search for anomalous time series in real time for transient, multivariate, and aperiodic signals. We use a RNN-based variational autoencoder to encode supernova time series and an isolation forest to search for anomalous events in the learned encoded space. We apply this method to a simulated dataset of 12,159 supernovae, successfully discovering anomalous supernovae and objects with catastrophically incorrect redshift measurements. This work is the first anomaly detection pipeline for supernovae which works with online datastreams.