 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoS: Analysis of Surface over Semantics in Multilingual Text-To-Image Generation
Jan 23, 2026Text-to-image (T2I) models are increasingly employed by users worldwide. However, prior research has pointed to the high sensitivity of T2I towards particular input languages - when faced with languages other than English (i.e., different surface forms of the same prompt), T2I models often produce culturally stereotypical depictions, prioritizing the surface over the prompt's semantics. Yet a comprehensive analysis of this behavior, which we dub Surface-over-Semantics (SoS), is missing. We present the first analysis of T2I models' SoS tendencies. To this end, we create a set of prompts covering 171 cultural identities, translated into 14 languages, and use it to prompt seven T2I models. To quantify SoS tendencies across models, languages, and cultures, we introduce a novel measure and analyze how the tendencies we identify manifest visually. We show that all but one model exhibit strong surface-level tendency in at least two languages, with this effect intensifying across the layers of T2I text encoders. Moreover, these surface tendencies frequently correlate with stereotypical visual depictions.
CollEX -- A Multimodal Agentic RAG System Enabling Interactive Exploration of Scientific Collections
Apr 10, 2025In this paper, we introduce CollEx, an innovative multimodal agentic Retrieval-Augmented Generation (RAG) system designed to enhance interactive exploration of extensive scientific collections. Given the overwhelming volume and inherent complexity of scientific collections, conventional search systems often lack necessary intuitiveness and interactivity, presenting substantial barriers for learners, educators, and researchers. CollEx addresses these limitations by employing state-of-the-art Large Vision-Language Models (LVLMs) as multimodal agents accessible through an intuitive chat interface. By abstracting complex interactions via specialized agents equipped with advanced tools, CollEx facilitates curiosity-driven exploration, significantly simplifying access to diverse scientific collections and records therein. Our system integrates textual and visual modalities, supporting educational scenarios that are helpful for teachers, pupils, students, and researchers by fostering independent exploration as well as scientific excitement and curiosity. Furthermore, CollEx serves the research community by discovering interdisciplinary connections and complementing visual data. We illustrate the effectiveness of our system through a proof-of-concept application containing over 64,000 unique records across 32 collections from a local scientific collection from a public university.
GIMMICK -- Globally Inclusive Multimodal Multitask Cultural Knowledge Benchmarking
Feb 19, 2025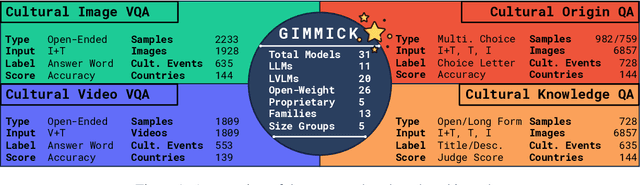


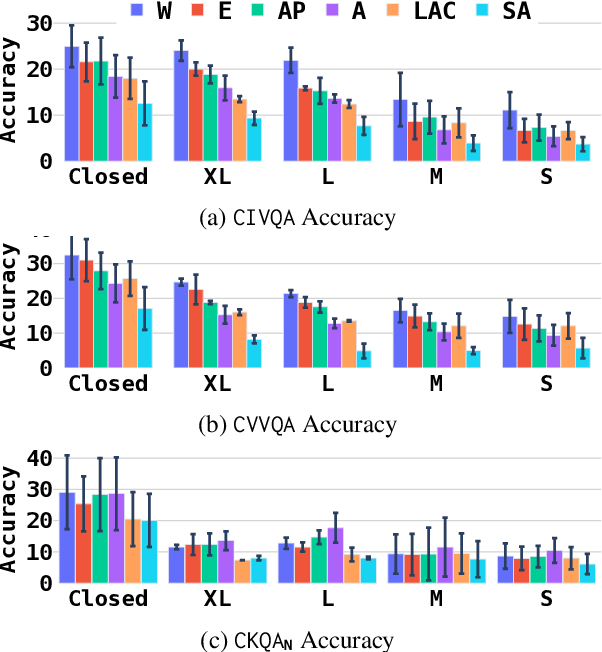
Large Vision-Language Models (LVLMs) have recently gained attention due to their distinctive performance and broad applicability. While it has been previously shown that their efficacy in usage scenarios involving non-Western contexts falls short, existing studies are limited in scope, covering just a narrow range of cultures, focusing exclusively on a small number of cultural aspects, or evaluating a limited selection of models on a single task only. Towards globally inclusive LVLM research, we introduce GIMMICK, an extensive multimodal benchmark designed to assess a broad spectrum of cultural knowledge across 144 countries representing six global macro-regions. GIMMICK comprises six tasks built upon three new datasets that span 728 unique cultural events or facets on which we evaluated 20 LVLMs and 11 LLMs, including five proprietary and 26 open-weight models of all sizes. We systematically examine (1) regional cultural biases, (2) the influence of model size, (3) input modalities, and (4) external cues. Our analyses reveal strong biases toward Western cultures across models and tasks and highlight strong correlations between model size and performance, as well as the effectiveness of multimodal input and external geographic cues. We further find that models have more knowledge of tangible than intangible aspects (e.g., food vs. rituals) and that they excel in recognizing broad cultural origins but struggle with a more nuanced understanding.
MVL-SIB: A Massively Multilingual Vision-Language Benchmark for Cross-Modal Topical Matching
Feb 18, 2025Existing multilingual vision-language (VL) benchmarks often only cover a handful of languages. Consequently, evaluations of large vision-language models (LVLMs) predominantly target high-resource languages, underscoring the need for evaluation data for low-resource languages. To address this limitation, we introduce MVL-SIB, a massively multilingual vision-language benchmark that evaluates both cross-modal and text-only topical matching across 205 languages -- over 100 more than the most multilingual existing VL benchmarks encompass. We then benchmark a range of of open-weight LVLMs together with GPT-4o(-mini) on MVL-SIB. Our results reveal that LVLMs struggle in cross-modal topic matching in lower-resource languages, performing no better than chance on languages like N'Koo. Our analysis further reveals that VL support in LVLMs declines disproportionately relative to textual support for lower-resource languages, as evidenced by comparison of cross-modal and text-only topical matching performance. We further observe that open-weight LVLMs do not benefit from representing a topic with more than one image, suggesting that these models are not yet fully effective at handling multi-image tasks. By correlating performance on MVL-SIB with other multilingual VL benchmarks, we highlight that MVL-SIB serves as a comprehensive probe of multilingual VL understanding in LVLMs.
Centurio: On Drivers of Multilingual Ability of Large Vision-Language Model
Jan 09, 2025



Most Large Vision-Language Models (LVLMs) to date are trained predominantly on English data, which makes them struggle to understand non-English input and fail to generate output in the desired target language. Existing efforts mitigate these issues by adding multilingual training data, but do so in a largely ad-hoc manner, lacking insight into how different training mixes tip the scale for different groups of languages. In this work, we present a comprehensive investigation into the training strategies for massively multilingual LVLMs. First, we conduct a series of multi-stage experiments spanning 13 downstream vision-language tasks and 43 languages, systematically examining: (1) the number of training languages that can be included without degrading English performance and (2) optimal language distributions of pre-training as well as (3) instruction-tuning data. Further, we (4) investigate how to improve multilingual text-in-image understanding, and introduce a new benchmark for the task. Surprisingly, our analysis reveals that one can (i) include as many as 100 training languages simultaneously (ii) with as little as 25-50\% of non-English data, to greatly improve multilingual performance while retaining strong English performance. We further find that (iii) including non-English OCR data in pre-training and instruction-tuning is paramount for improving multilingual text-in-image understanding. Finally, we put all our findings together and train Centurio, a 100-language LVLM, offering state-of-the-art performance in an evaluation covering 14 tasks and 56 languages.
Multilingual and Explainable Text Detoxification with Parallel Corpora
Dec 16, 2024Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
M$\mathbf5$ -- A Diverse Benchmark to Assess the Performance of Large Multimodal Models Across Multilingual and Multicultural Vision-Language Tasks
Jul 04, 2024



Since the release of ChatGPT, the field of Natural Language Processing has experienced rapid advancements, particularly in Large Language Models (LLMs) and their multimodal counterparts, Large Multimodal Models (LMMs). Despite their impressive capabilities, LLMs often exhibit significant performance disparities across different languages and cultural contexts, as demonstrated by various text-only benchmarks. However, current research lacks such benchmarks for multimodal visio-linguistic settings. This work fills this gap by introducing M5, the first comprehensive benchmark designed to evaluate LMMs on diverse vision-language tasks within a multilingual and multicultural context. M5 includes eight datasets covering five tasks and $41$ languages, with a focus on underrepresented languages and culturally diverse images. Furthermore, we introduce two novel datasets, M5-VGR and M5-VLOD, including a new Visio-Linguistic Outlier Detection task, in which all evaluated open-source models fail to significantly surpass the random baseline. Through extensive evaluation and analyses, we highlight substantial task-agnostic performance disparities between high- and low-resource languages. Moreover, we show that larger models do not necessarily outperform smaller ones in a multilingual setting.
Why do LLaVA Vision-Language Models Reply to Images in English?
Jul 02, 2024
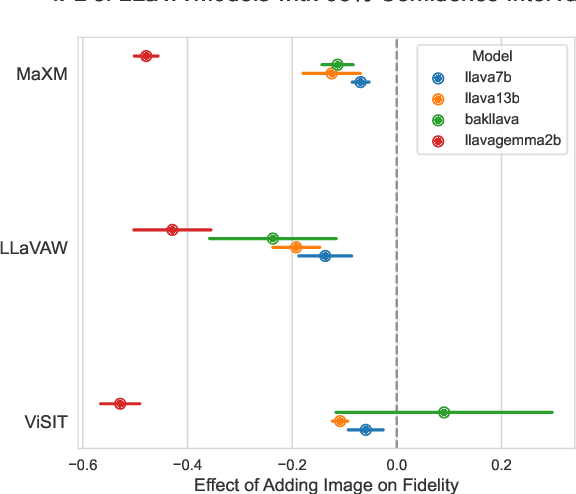
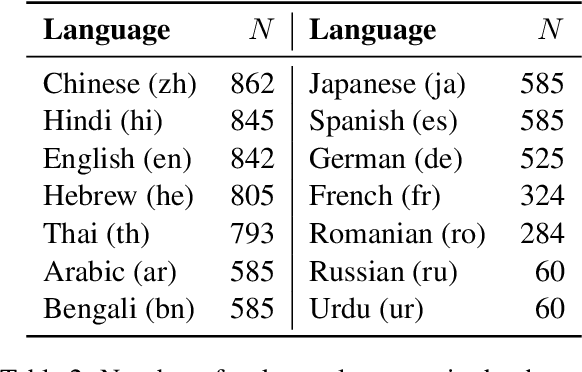
We uncover a surprising multilingual bias occurring in a popular class of multimodal vision-language models (VLMs). Including an image in the query to a LLaVA-style VLM significantly increases the likelihood of the model returning an English response, regardless of the language of the query. This paper investigates the causes of this loss with a two-pronged approach that combines extensive ablation of the design space with a mechanistic analysis of the models' internal representations of image and text inputs. Both approaches indicate that the issue stems in the language modelling component of the LLaVA model. Statistically, we find that switching the language backbone for a bilingual language model has the strongest effect on reducing this error. Mechanistically, we provide compelling evidence that visual inputs are not mapped to a similar space as text ones, and that intervening on intermediary attention layers can reduce this bias. Our findings provide important insights to researchers and engineers seeking to understand the crossover between multimodal and multilingual spaces, and contribute to the goal of developing capable and inclusive VLMs for non-English contexts.
Learn to Code Sustainably: An Empirical Study on LLM-based Green Code Generation
Mar 05, 2024The increasing use of information technology has led to a significant share of energy consumption and carbon emissions from data centers. These contributions are expected to rise with the growing demand for big data analytics, increasing digitization, and the development of large artificial intelligence (AI) models. The need to address the environmental impact of software development has led to increased interest in green (sustainable) coding and claims that the use of AI models can lead to energy efficiency gains. Here, we provide an empirical study on green code and an overview of green coding practices, as well as metrics used to quantify the sustainability awareness of AI models. In this framework, we evaluate the sustainability of auto-generated code. The auto-generate codes considered in this study are produced by generative commercial AI language models, GitHub Copilot, OpenAI ChatGPT-3, and Amazon CodeWhisperer. Within our methodology, in order to quantify the sustainability awareness of these AI models, we propose a definition of the code's "green capacity", based on certain sustainability metrics. We compare the performance and green capacity of human-generated code and code generated by the three AI language models in response to easy-to-hard problem statements. Our findings shed light on the current capacity of AI models to contribute to sustainable software development.