 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Footprint Evaluation of Code Generation through LLM as a Service
Mar 30, 2025Due to increased computing use, data centers consume and emit a lot of energy and carbon. These contributions are expected to rise as big data analytics, digitization, and large AI models grow and become major components of daily working routines. To reduce the environmental impact of software development, green (sustainable) coding and claims that AI models can improve energy efficiency have grown in popularity. Furthermore, in the automotive industry, where software increasingly governs vehicle performance, safety, and user experience, the principles of green coding and AI-driven efficiency could significantly contribute to reducing the sector's environmental footprint. We present an overview of green coding and metrics to measure AI model sustainability awareness. This study introduces LLM as a service and uses a generative commercial AI language model, GitHub Copilot, to auto-generate code. Using sustainability metrics to quantify these AI models' sustainability awareness, we define the code's embodied and operational carbon.
Prompting-based Synthetic Data Generation for Few-Shot Question Answering
May 15, 2024Although language models (LMs) have boosted the performance of Question Answering, they still need plenty of data. Data annotation, in contrast, is a time-consuming process. This especially applies to Question Answering, where possibly large documents have to be parsed and annotated with questions and their corresponding answers. Furthermore, Question Answering models often only work well for the domain they were trained on. Since annotation is costly, we argue that domain-agnostic knowledge from LMs, such as linguistic understanding, is sufficient to create a well-curated dataset. With this motivation, we show that using large language models can improve Question Answering performance on various datasets in the few-shot setting compared to state-of-the-art approaches. For this, we perform data generation leveraging the Prompting framework, suggesting that language models contain valuable task-agnostic knowledge that can be used beyond the common pre-training/fine-tuning scheme. As a result, we consistently outperform previous approaches on few-shot Question Answering.
Smooth Deep Saliency
Apr 04, 2024In this work, we investigate methods to reduce the noise in deep saliency maps coming from convolutional downsampling, with the purpose of explaining how a deep learning model detects tumors in scanned histological tissue samples. Those methods make the investigated models more interpretable for gradient-based saliency maps, computed in hidden layers. We test our approach on different models trained for image classification on ImageNet1K, and models trained for tumor detection on Camelyon16 and in-house real-world digital pathology scans of stained tissue samples. Our results show that the checkerboard noise in the gradient gets reduced, resulting in smoother and therefore easier to interpret saliency maps.
Learn to Code Sustainably: An Empirical Study on LLM-based Green Code Generation
Mar 05, 2024The increasing use of information technology has led to a significant share of energy consumption and carbon emissions from data centers. These contributions are expected to rise with the growing demand for big data analytics, increasing digitization, and the development of large artificial intelligence (AI) models. The need to address the environmental impact of software development has led to increased interest in green (sustainable) coding and claims that the use of AI models can lead to energy efficiency gains. Here, we provide an empirical study on green code and an overview of green coding practices, as well as metrics used to quantify the sustainability awareness of AI models. In this framework, we evaluate the sustainability of auto-generated code. The auto-generate codes considered in this study are produced by generative commercial AI language models, GitHub Copilot, OpenAI ChatGPT-3, and Amazon CodeWhisperer. Within our methodology, in order to quantify the sustainability awareness of these AI models, we propose a definition of the code's "green capacity", based on certain sustainability metrics. We compare the performance and green capacity of human-generated code and code generated by the three AI language models in response to easy-to-hard problem statements. Our findings shed light on the current capacity of AI models to contribute to sustainable software development.
Model Stitching and Visualization How GAN Generators can Invert Networks in Real-Time
Feb 04, 2023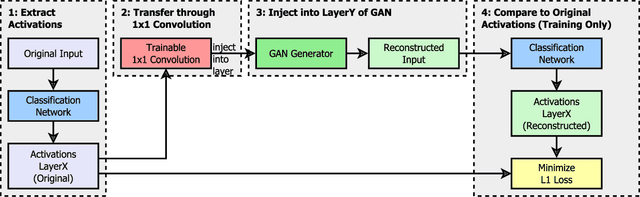
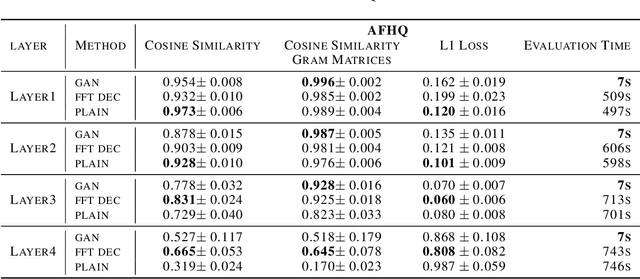
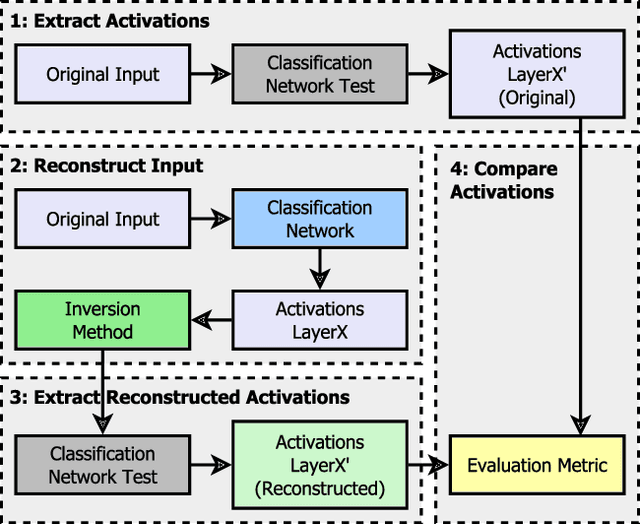

Critical applications, such as in the medical field, require the rapid provision of additional information to interpret decisions made by deep learning methods. In this work, we propose a fast and accurate method to visualize activations of classification and semantic segmentation networks by stitching them with a GAN generator utilizing convolutions. We test our approach on images of animals from the AFHQ wild dataset and real-world digital pathology scans of stained tissue samples. Our method provides comparable results to established gradient descent methods on these datasets while running about two orders of magnitude faster.
Improving Low-Resource Question Answering using Active Learning in Multiple Stages
Nov 27, 2022



Neural approaches have become very popular in the domain of Question Answering, however they require a large amount of annotated data. Furthermore, they often yield very good performance but only in the domain they were trained on. In this work we propose a novel approach that combines data augmentation via question-answer generation with Active Learning to improve performance in low resource settings, where the target domains are diverse in terms of difficulty and similarity to the source domain. We also investigate Active Learning for question answering in different stages, overall reducing the annotation effort of humans. For this purpose, we consider target domains in realistic settings, with an extremely low amount of annotated samples but with many unlabeled documents, which we assume can be obtained with little effort. Additionally, we assume sufficient amount of labeled data from the source domain is available. We perform extensive experiments to find the best setup for incorporating domain experts. Our findings show that our novel approach, where humans are incorporated as early as possible in the process, boosts performance in the low-resource, domain-specific setting, allowing for low-labeling-effort question answering systems in new, specialized domains. They further demonstrate how human annotation affects the performance of QA depending on the stage it is performed.
Is Deep Image Prior in Need of a Good Education?
Nov 23, 2021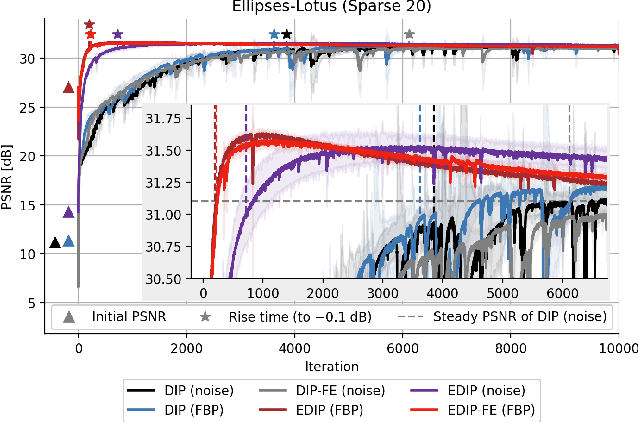
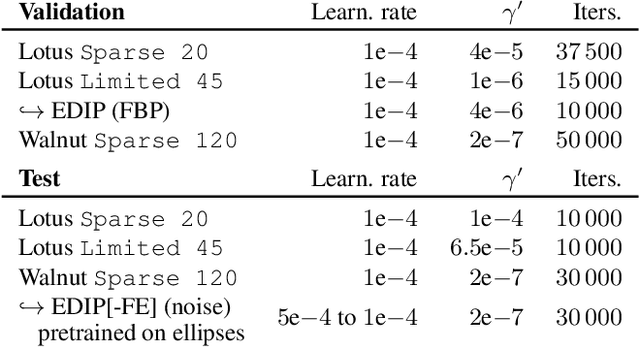
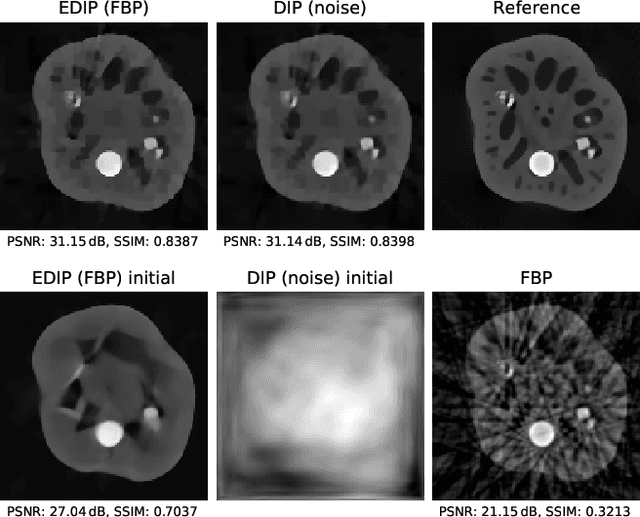

Deep image prior was recently introduced as an effective prior for image reconstruction. It represents the image to be recovered as the output of a deep convolutional neural network, and learns the network's parameters such that the output fits the corrupted observation. Despite its impressive reconstructive properties, the approach is slow when compared to learned or traditional reconstruction techniques. Our work develops a two-stage learning paradigm to address the computational challenge: (i) we perform a supervised pretraining of the network on a synthetic dataset; (ii) we fine-tune the network's parameters to adapt to the target reconstruction. We showcase that pretraining considerably speeds up the subsequent reconstruction from real-measured micro computed tomography data of biological specimens. The code and additional experimental materials are available at https://educateddip.github.io/docs.educated_deep_image_prior/.
Conditional Invertible Neural Networks for Medical Imaging
Oct 26, 2021

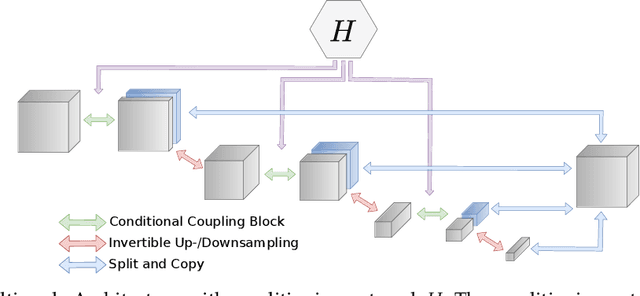
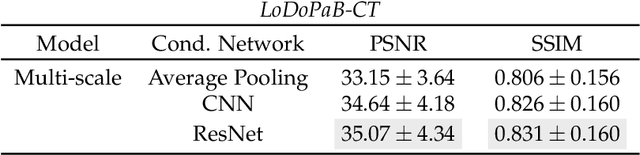
Over the last years, deep learning methods have become an increasingly popular choice to solve tasks from the field of inverse problems. Many of these new data-driven methods have produced impressive results, although most only give point estimates for the reconstruction. However, especially in the analysis of ill-posed inverse problems, the study of uncertainties is essential. In our work, we apply generative flow-based models based on invertible neural networks to two challenging medical imaging tasks, i.e. low-dose computed tomography and accelerated medical resonance imaging. We test different architectures of invertible neural networks and provide extensive ablation studies. In most applications, a standard Gaussian is used as the base distribution for a flow-based model. Our results show that the choice of a radial distribution can improve the quality of reconstructions.
Evolving Neuronal Plasticity Rules using Cartesian Genetic Programming
Feb 08, 2021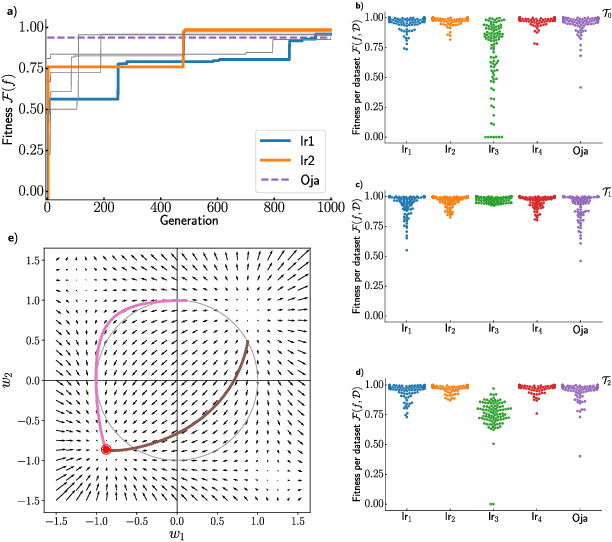
We formulate the search for phenomenological models of synaptic plasticity as an optimization problem. We employ Cartesian genetic programming to evolve biologically plausible human-interpretable plasticity rules that allow a given network to successfully solve tasks from specific task families. While our evolving-to-learn approach can be applied to various learning paradigms, here we illustrate its power by evolving plasticity rules that allow a network to efficiently determine the first principal component of its input distribution. We demonstrate that the evolved rules perform competitively with known hand-designed solutions. We explore how the statistical properties of the datasets used during the evolutionary search influences the form of the plasticity rules and discover new rules which are adapted to the structure of the corresponding datasets.
ADVISER: A Toolkit for Developing Multi-modal, Multi-domain and Socially-engaged Conversational Agents
May 04, 2020
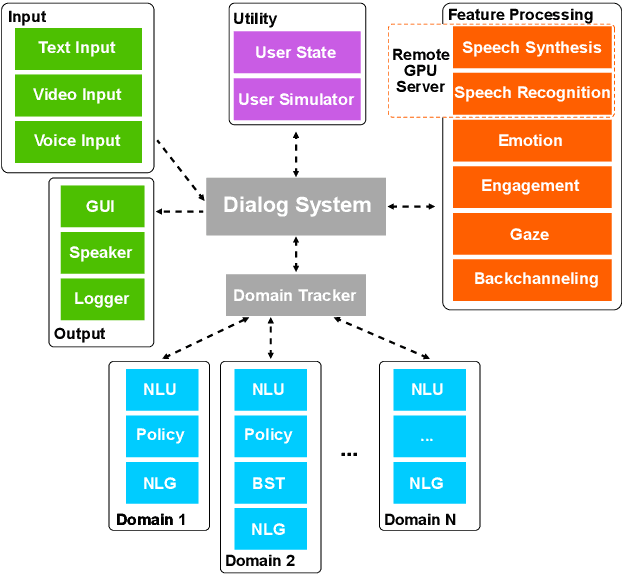
We present ADVISER - an open-source, multi-domain dialog system toolkit that enables the development of multi-modal (incorporating speech, text and vision), socially-engaged (e.g. emotion recognition, engagement level prediction and backchanneling) conversational agents. The final Python-based implementation of our toolkit is flexible, easy to use, and easy to extend not only for technically experienced users, such as machine learning researchers, but also for less technically experienced users, such as linguists or cognitive scientists, thereby providing a flexible platform for collaborative research. Link to open-source code: https://github.com/DigitalPhonetics/adviser