 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOh, Jeez! or Uh-huh? A Listener-aware Backchannel Predictor on ASR Transcriptions
Apr 10, 2023This paper presents our latest investigation on modeling backchannel in conversations. Motivated by a proactive backchanneling theory, we aim at developing a system which acts as a proactive listener by inserting backchannels, such as continuers and assessment, to influence speakers. Our model takes into account not only lexical and acoustic cues, but also introduces the simple and novel idea of using listener embeddings to mimic different backchanneling behaviours. Our experimental results on the Switchboard benchmark dataset reveal that acoustic cues are more important than lexical cues in this task and their combination with listener embeddings works best on both, manual transcriptions and automatically generated transcriptions.
Modeling Speaker-Listener Interaction for Backchannel Prediction
Apr 10, 2023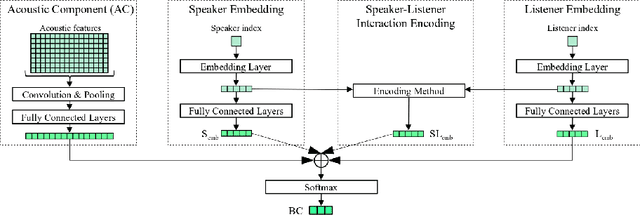



We present our latest findings on backchannel modeling novelly motivated by the canonical use of the minimal responses Yeah and Uh-huh in English and their correspondent tokens in German, and the effect of encoding the speaker-listener interaction. Backchanneling theories emphasize the active and continuous role of the listener in the course of the conversation, their effects on the speaker's subsequent talk, and the consequent dynamic speaker-listener interaction. Therefore, we propose a neural-based acoustic backchannel classifier on minimal responses by processing acoustic features from the speaker speech, capturing and imitating listeners' backchanneling behavior, and encoding speaker-listener interaction. Our experimental results on the Switchboard and GECO datasets reveal that in almost all tested scenarios the speaker or listener behavior embeddings help the model make more accurate backchannel predictions. More importantly, a proper interaction encoding strategy, i.e., combining the speaker and listener embeddings, leads to the best performance on both datasets in terms of F1-score.
ADVISER: A Toolkit for Developing Multi-modal, Multi-domain and Socially-engaged Conversational Agents
May 04, 2020
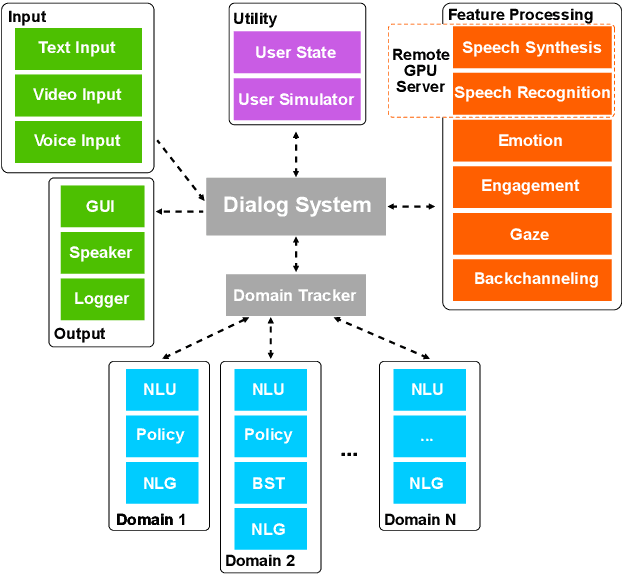
We present ADVISER - an open-source, multi-domain dialog system toolkit that enables the development of multi-modal (incorporating speech, text and vision), socially-engaged (e.g. emotion recognition, engagement level prediction and backchanneling) conversational agents. The final Python-based implementation of our toolkit is flexible, easy to use, and easy to extend not only for technically experienced users, such as machine learning researchers, but also for less technically experienced users, such as linguists or cognitive scientists, thereby providing a flexible platform for collaborative research. Link to open-source code: https://github.com/DigitalPhonetics/adviser
Context-aware Neural-based Dialog Act Classification on Automatically Generated Transcriptions
Feb 28, 2019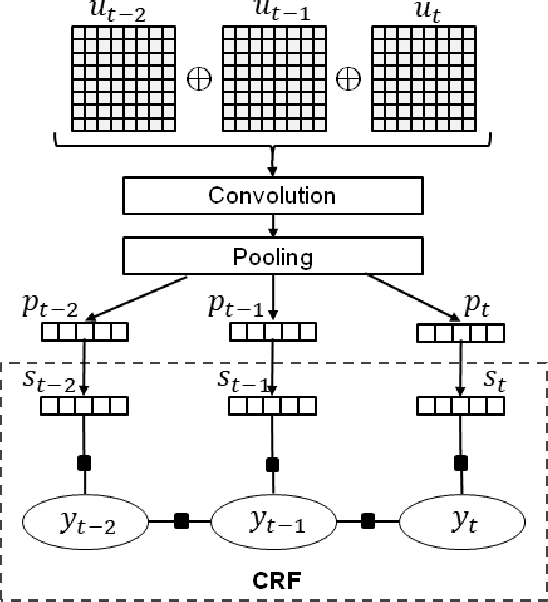
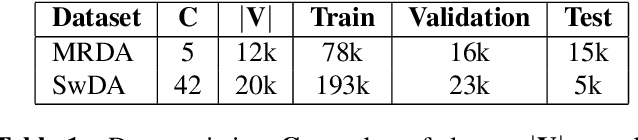
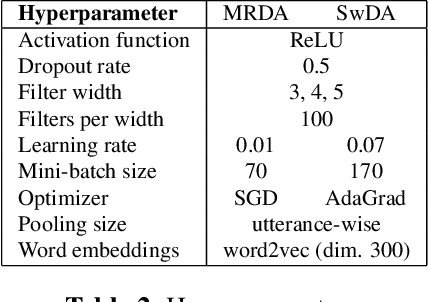
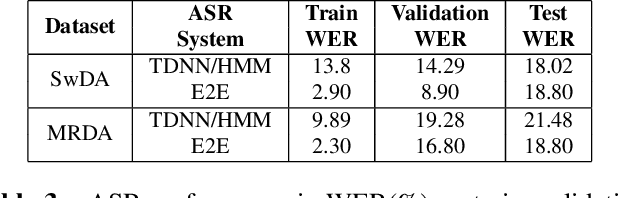
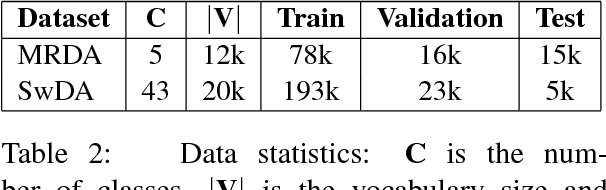
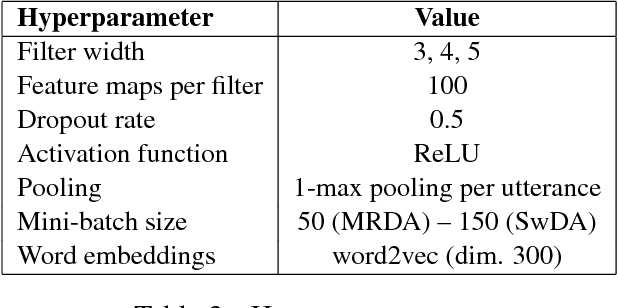
This paper presents our latest investigations on dialog act (DA) classification on automatically generated transcriptions. We propose a novel approach that combines convolutional neural networks (CNNs) and conditional random fields (CRFs) for context modeling in DA classification. We explore the impact of transcriptions generated from different automatic speech recognition systems such as hybrid TDNN/HMM and End-to-End systems on the final performance. Experimental results on two benchmark datasets (MRDA and SwDA) show that the combination CNN and CRF improves consistently the accuracy. Furthermore, they show that although the word error rates are comparable, End-to-End ASR system seems to be more suitable for DA classification.
Lexico-acoustic Neural-based Models for Dialog Act Classification
Mar 02, 2018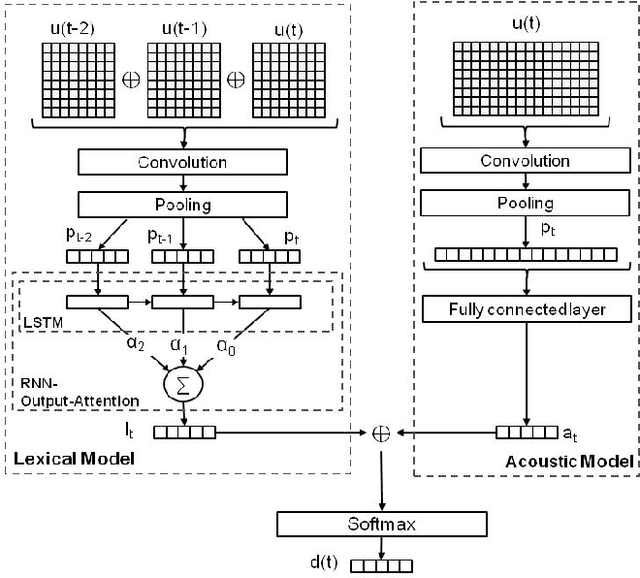

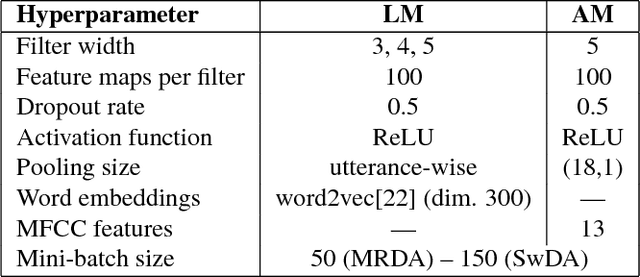

Recent works have proposed neural models for dialog act classification in spoken dialogs. However, they have not explored the role and the usefulness of acoustic information. We propose a neural model that processes both lexical and acoustic features for classification. Our results on two benchmark datasets reveal that acoustic features are helpful in improving the overall accuracy. Finally, a deeper analysis shows that acoustic features are valuable in three cases: when a dialog act has sufficient data, when lexical information is limited and when strong lexical cues are not present.
Neural-based Context Representation Learning for Dialog Act Classification
Aug 08, 2017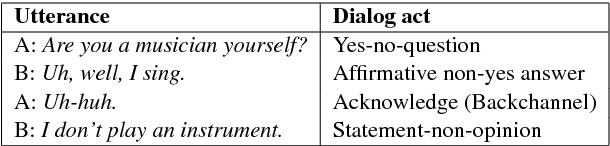
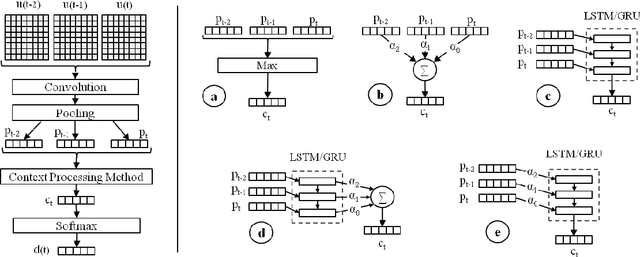
We explore context representation learning methods in neural-based models for dialog act classification. We propose and compare extensively different methods which combine recurrent neural network architectures and attention mechanisms (AMs) at different context levels. Our experimental results on two benchmark datasets show consistent improvements compared to the models without contextual information and reveal that the most suitable AM in the architecture depends on the nature of the dataset.