 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Speaker-Listener Interaction for Backchannel Prediction
Paper and Code
Apr 10, 2023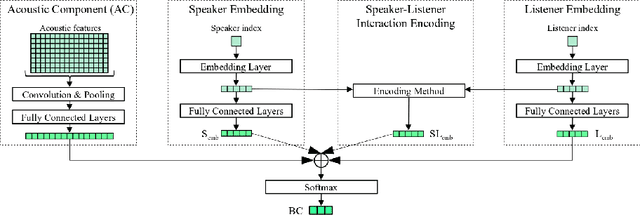



We present our latest findings on backchannel modeling novelly motivated by the canonical use of the minimal responses Yeah and Uh-huh in English and their correspondent tokens in German, and the effect of encoding the speaker-listener interaction. Backchanneling theories emphasize the active and continuous role of the listener in the course of the conversation, their effects on the speaker's subsequent talk, and the consequent dynamic speaker-listener interaction. Therefore, we propose a neural-based acoustic backchannel classifier on minimal responses by processing acoustic features from the speaker speech, capturing and imitating listeners' backchanneling behavior, and encoding speaker-listener interaction. Our experimental results on the Switchboard and GECO datasets reveal that in almost all tested scenarios the speaker or listener behavior embeddings help the model make more accurate backchannel predictions. More importantly, a proper interaction encoding strategy, i.e., combining the speaker and listener embeddings, leads to the best performance on both datasets in terms of F1-score.