Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexico-acoustic Neural-based Models for Dialog Act Classification
Paper and Code
Mar 02, 2018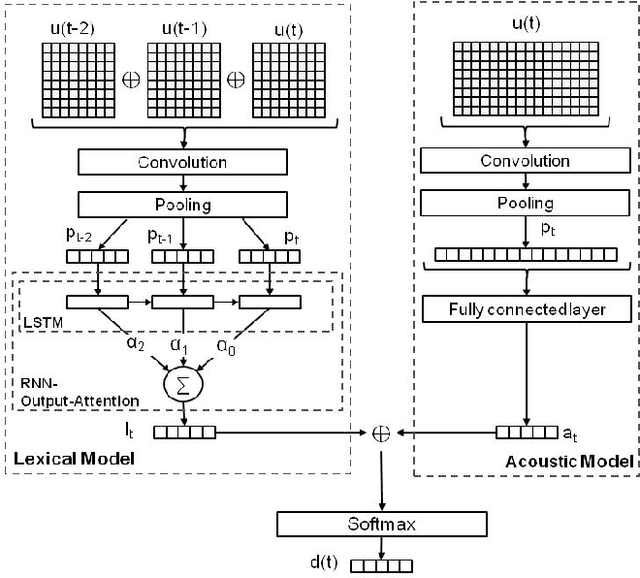

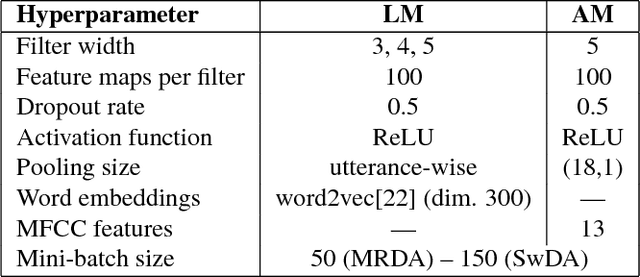

Recent works have proposed neural models for dialog act classification in spoken dialogs. However, they have not explored the role and the usefulness of acoustic information. We propose a neural model that processes both lexical and acoustic features for classification. Our results on two benchmark datasets reveal that acoustic features are helpful in improving the overall accuracy. Finally, a deeper analysis shows that acoustic features are valuable in three cases: when a dialog act has sufficient data, when lexical information is limited and when strong lexical cues are not present.
* 5 pages, 1 figure, 2018 International Conference on Acoustics,
Speech, and Signal Processing (ICASSP 2018)
View paper on