 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Zero-Shot approach to the Conversational Tree Search Task
Oct 08, 2024



In sensitive domains, such as legal or medial domains, the correctness of information given to users is critical. To address this, the recently introduced task Conversational Tree Search (CTS) provides a graph-based framework for controllable task-oriented dialog in sensitive domains. However, a big drawback of state-of-the-art CTS agents is their long training time, which is especially problematic as a new agent must be trained every time the associated domain graph is updated. The goal of this paper is to eliminate the need for training CTS agents altogether. To achieve this, we implement a novel LLM-based method for zero-shot, controllable CTS agents. We show that these agents significantly outperform state-of-the-art CTS agents (p<0.0001; Barnard Exact test) in simulation. This generalizes to all available CTS domains. Finally, we perform user evaluation to test the agent performance in the wild, showing that our policy significantly (p<0.05; Barnard Exact) improves task-success compared to the state-of-the-art Reinforcement Learning-based CTS agent.
Investigating the effect of Mental Models in User Interaction with an Adaptive Dialog Agent
Aug 26, 2024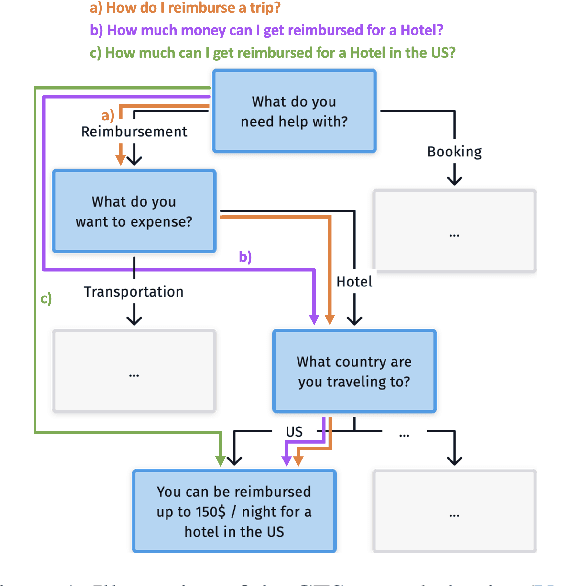
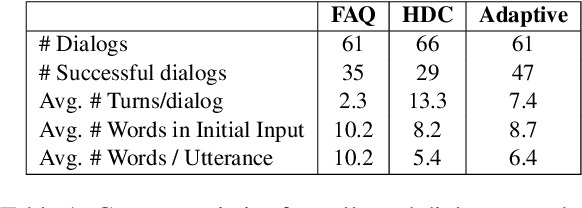
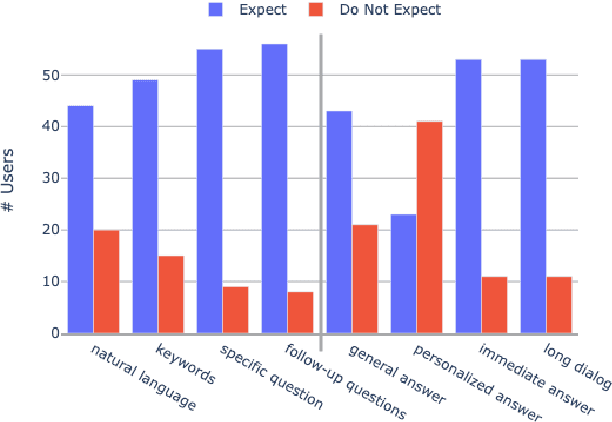

Mental models play an important role in whether user interaction with intelligent systems, such as dialog systems is successful or not. Adaptive dialog systems present the opportunity to align a dialog agent's behavior with heterogeneous user expectations. However, there has been little research into what mental models users form when interacting with a task-oriented dialog system, how these models affect users' interactions, or what role system adaptation can play in this process, making it challenging to avoid damage to human-AI partnership. In this work, we collect a new publicly available dataset for exploring user mental models about information seeking dialog systems. We demonstrate that users have a variety of conflicting mental models about such systems, the validity of which directly impacts the success of their interactions and perceived usability of system. Furthermore, we show that adapting a dialog agent's behavior to better align with users' mental models, even when done implicitly, can improve perceived usability, dialog efficiency, and success. To this end, we argue that implicit adaptation can be a valid strategy for task-oriented dialog systems, so long as developers first have a solid understanding of users' mental models.
Towards a Zero-Data, Controllable, Adaptive Dialog System
Mar 26, 2024Conversational Tree Search (V\"ath et al., 2023) is a recent approach to controllable dialog systems, where domain experts shape the behavior of a Reinforcement Learning agent through a dialog tree. The agent learns to efficiently navigate this tree, while adapting to information needs, e.g., domain familiarity, of different users. However, the need for additional training data hinders deployment in new domains. To address this, we explore approaches to generate this data directly from dialog trees. We improve the original approach, and show that agents trained on synthetic data can achieve comparable dialog success to models trained on human data, both when using a commercial Large Language Model for generation, or when using a smaller open-source model, running on a single GPU. We further demonstrate the scalability of our approach by collecting and testing on two new datasets: ONBOARD, a new domain helping foreign residents moving to a new city, and the medical domain DIAGNOSE, a subset of Wikipedia articles related to scalp and head symptoms. Finally, we perform human testing, where no statistically significant differences were found in either objective or subjective measures between models trained on human and generated data.
Conversational Tree Search: A New Hybrid Dialog Task
Mar 17, 2023Conversational interfaces provide a flexible and easy way for users to seek information that may otherwise be difficult or inconvenient to obtain. However, existing interfaces generally fall into one of two categories: FAQs, where users must have a concrete question in order to retrieve a general answer, or dialogs, where users must follow a predefined path but may receive a personalized answer. In this paper, we introduce Conversational Tree Search (CTS) as a new task that bridges the gap between FAQ-style information retrieval and task-oriented dialog, allowing domain-experts to define dialog trees which can then be converted to an efficient dialog policy that learns only to ask the questions necessary to navigate a user to their goal. We collect a dataset for the travel reimbursement domain and demonstrate a baseline as well as a novel deep Reinforcement Learning architecture for this task. Our results show that the new architecture combines the positive aspects of both the FAQ and dialog system used in the baseline and achieves higher goal completion while skipping unnecessary questions.
Beyond Accuracy: A Consolidated Tool for Visual Question Answering Benchmarking
Oct 11, 2021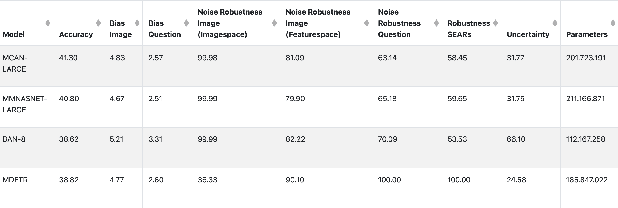
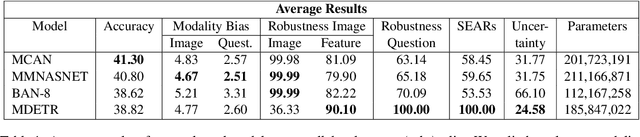
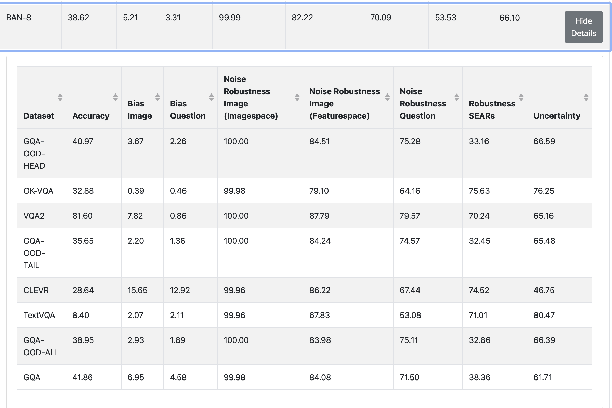

On the way towards general Visual Question Answering (VQA) systems that are able to answer arbitrary questions, the need arises for evaluation beyond single-metric leaderboards for specific datasets. To this end, we propose a browser-based benchmarking tool for researchers and challenge organizers, with an API for easy integration of new models and datasets to keep up with the fast-changing landscape of VQA. Our tool helps test generalization capabilities of models across multiple datasets, evaluating not just accuracy, but also performance in more realistic real-world scenarios such as robustness to input noise. Additionally, we include metrics that measure biases and uncertainty, to further explain model behavior. Interactive filtering facilitates discovery of problematic behavior, down to the data sample level. As proof of concept, we perform a case study on four models. We find that state-of-the-art VQA models are optimized for specific tasks or datasets, but fail to generalize even to other in-domain test sets, for example they cannot recognize text in images. Our metrics allow us to quantify which image and question embeddings provide most robustness to a model. All code is publicly available.
ADVISER: A Toolkit for Developing Multi-modal, Multi-domain and Socially-engaged Conversational Agents
May 04, 2020
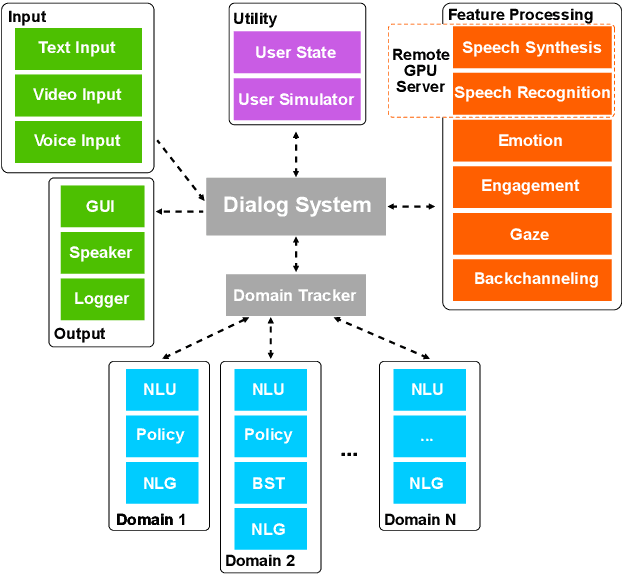
We present ADVISER - an open-source, multi-domain dialog system toolkit that enables the development of multi-modal (incorporating speech, text and vision), socially-engaged (e.g. emotion recognition, engagement level prediction and backchanneling) conversational agents. The final Python-based implementation of our toolkit is flexible, easy to use, and easy to extend not only for technically experienced users, such as machine learning researchers, but also for less technically experienced users, such as linguists or cognitive scientists, thereby providing a flexible platform for collaborative research. Link to open-source code: https://github.com/DigitalPhonetics/adviser