 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Subgraph Sampling for Interpretable Graph based Visual Question Answering
Dec 11, 2024Explainable artificial intelligence (XAI) aims to make machine learning models more transparent. While many approaches focus on generating explanations post-hoc, interpretable approaches, which generate the explanations intrinsically alongside the predictions, are relatively rare. In this work, we integrate different discrete subset sampling methods into a graph-based visual question answering system to compare their effectiveness in generating interpretable explanatory subgraphs intrinsically. We evaluate the methods on the GQA dataset and show that the integrated methods effectively mitigate the performance trade-off between interpretability and answer accuracy, while also achieving strong co-occurrences between answer and question tokens. Furthermore, we conduct a human evaluation to assess the interpretability of the generated subgraphs using a comparative setting with the extended Bradley-Terry model, showing that the answer and question token co-occurrence metrics strongly correlate with human preferences. Our source code is publicly available.
Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions
Aug 26, 2024



Dual encoder architectures like CLIP models map two types of inputs into a shared embedding space and learn similarities between them. However, it is not understood how such models compare two inputs. Here, we address this research gap with two contributions. First, we derive a method to attribute predictions of any differentiable dual encoder onto feature-pair interactions between its inputs. Second, we apply our method to CLIP-type models and show that they learn fine-grained correspondences between parts of captions and regions in images. They match objects across input modes and also account for mismatches. However, this visual-linguistic grounding ability heavily varies between object classes, depends on the training data distribution, and largely improves after in-domain training. Using our method we can identify knowledge gaps about specific object classes in individual models and can monitor their improvement upon fine-tuning.
Intrinsic Subgraph Generation for Interpretable Graph based Visual Question Answering
Mar 27, 2024The large success of deep learning based methods in Visual Question Answering (VQA) has concurrently increased the demand for explainable methods. Most methods in Explainable Artificial Intelligence (XAI) focus on generating post-hoc explanations rather than taking an intrinsic approach, the latter characterizing an interpretable model. In this work, we introduce an interpretable approach for graph-based VQA and demonstrate competitive performance on the GQA dataset. This approach bridges the gap between interpretability and performance. Our model is designed to intrinsically produce a subgraph during the question-answering process as its explanation, providing insight into the decision making. To evaluate the quality of these generated subgraphs, we compare them against established post-hoc explainability methods for graph neural networks, and perform a human evaluation. Moreover, we present quantitative metrics that correlate with the evaluations of human assessors, acting as automatic metrics for the generated explanatory subgraphs. Our implementation is available at https://github.com/DigitalPhonetics/Intrinsic-Subgraph-Generation-for-VQA.
Controllable Generation of Artificial Speaker Embeddings through Discovery of Principal Directions
Oct 26, 2023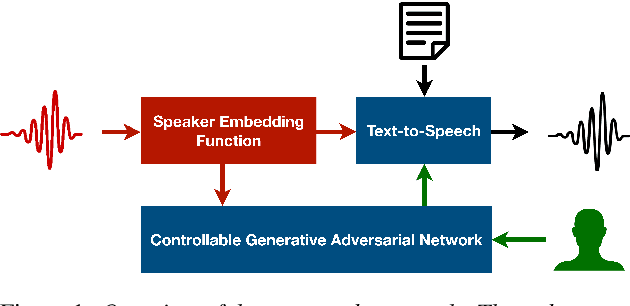
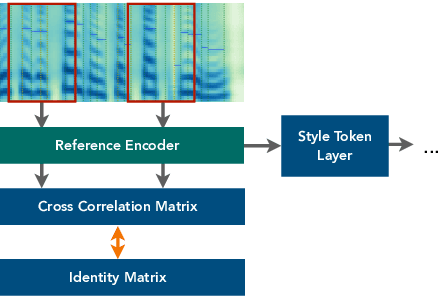

Customizing voice and speaking style in a speech synthesis system with intuitive and fine-grained controls is challenging, given that little data with appropriate labels is available. Furthermore, editing an existing human's voice also comes with ethical concerns. In this paper, we propose a method to generate artificial speaker embeddings that cannot be linked to a real human while offering intuitive and fine-grained control over the voice and speaking style of the embeddings, without requiring any labels for speaker or style. The artificial and controllable embeddings can be fed to a speech synthesis system, conditioned on embeddings of real humans during training, without sacrificing privacy during inference.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022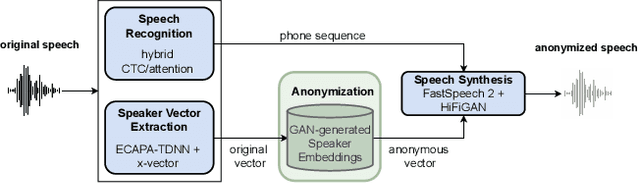
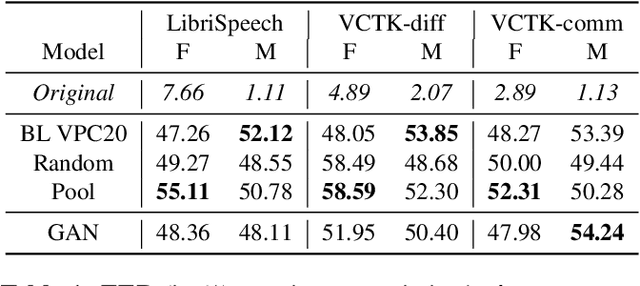
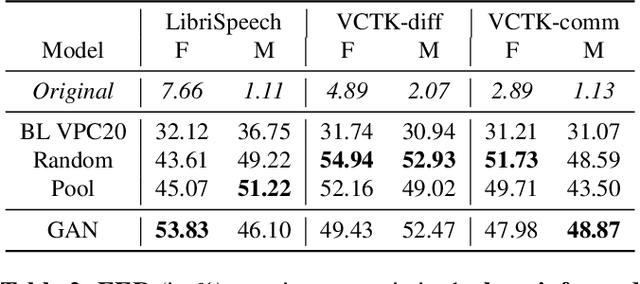
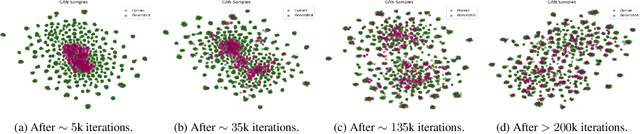
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022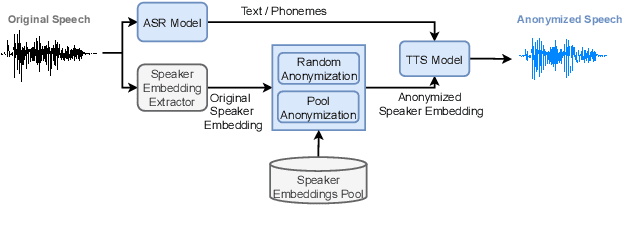
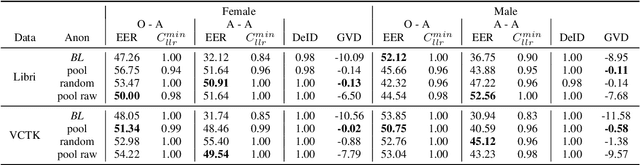
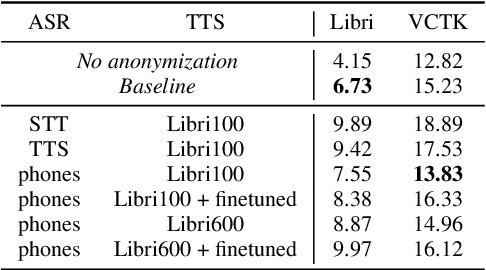

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Beyond Accuracy: A Consolidated Tool for Visual Question Answering Benchmarking
Oct 11, 2021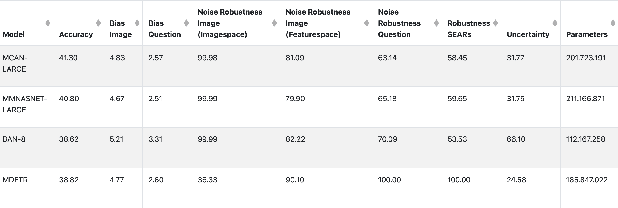
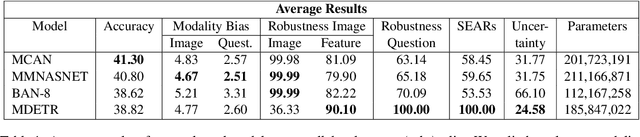
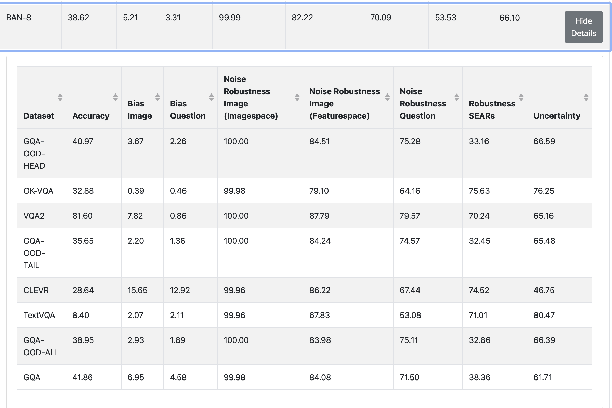

On the way towards general Visual Question Answering (VQA) systems that are able to answer arbitrary questions, the need arises for evaluation beyond single-metric leaderboards for specific datasets. To this end, we propose a browser-based benchmarking tool for researchers and challenge organizers, with an API for easy integration of new models and datasets to keep up with the fast-changing landscape of VQA. Our tool helps test generalization capabilities of models across multiple datasets, evaluating not just accuracy, but also performance in more realistic real-world scenarios such as robustness to input noise. Additionally, we include metrics that measure biases and uncertainty, to further explain model behavior. Interactive filtering facilitates discovery of problematic behavior, down to the data sample level. As proof of concept, we perform a case study on four models. We find that state-of-the-art VQA models are optimized for specific tasks or datasets, but fail to generalize even to other in-domain test sets, for example they cannot recognize text in images. Our metrics allow us to quantify which image and question embeddings provide most robustness to a model. All code is publicly available.