 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Text Embeddings and Text Similarity Explanation: A Primer
Feb 20, 2025


Text embeddings and text embedding models are a backbone of many AI and NLP systems, particularly those involving search. However, interpretability challenges persist, especially in explaining obtained similarity scores, which is crucial for applications requiring transparency. In this paper, we give a structured overview of interpretability methods specializing in explaining those similarity scores, an emerging research area. We study the methods' individual ideas and techniques, evaluating their potential for improving interpretability of text embeddings and explaining predicted similarities.
Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions
Aug 26, 2024



Dual encoder architectures like CLIP models map two types of inputs into a shared embedding space and learn similarities between them. However, it is not understood how such models compare two inputs. Here, we address this research gap with two contributions. First, we derive a method to attribute predictions of any differentiable dual encoder onto feature-pair interactions between its inputs. Second, we apply our method to CLIP-type models and show that they learn fine-grained correspondences between parts of captions and regions in images. They match objects across input modes and also account for mismatches. However, this visual-linguistic grounding ability heavily varies between object classes, depends on the training data distribution, and largely improves after in-domain training. Using our method we can identify knowledge gaps about specific object classes in individual models and can monitor their improvement upon fine-tuning.
Approximate Attributions for Off-the-Shelf Siamese Transformers
Feb 05, 2024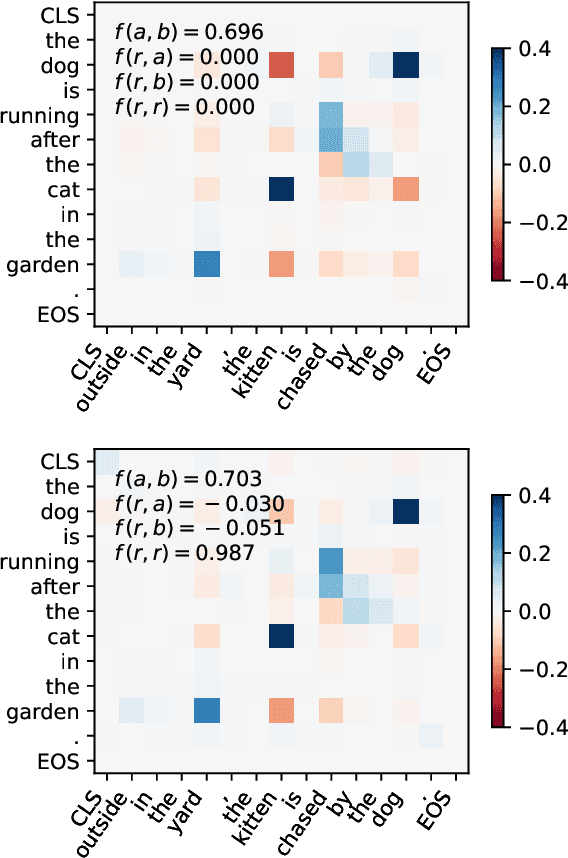
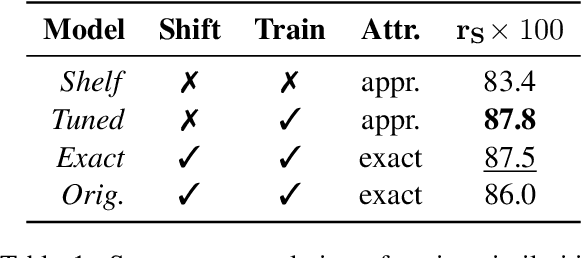
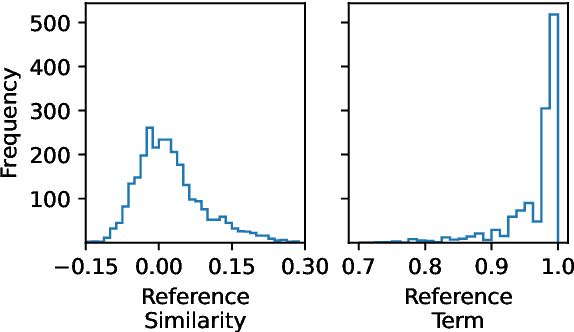

Siamese encoders such as sentence transformers are among the least understood deep models. Established attribution methods cannot tackle this model class since it compares two inputs rather than processing a single one. To address this gap, we have recently proposed an attribution method specifically for Siamese encoders (M\"oller et al., 2023). However, it requires models to be adjusted and fine-tuned and therefore cannot be directly applied to off-the-shelf models. In this work, we reassess these restrictions and propose (i) a model with exact attribution ability that retains the original model's predictive performance and (ii) a way to compute approximate attributions for off-the-shelf models. We extensively compare approximate and exact attributions and use them to analyze the models' attendance to different linguistic aspects. We gain insights into which syntactic roles Siamese transformers attend to, confirm that they mostly ignore negation, explore how they judge semantically opposite adjectives, and find that they exhibit lexical bias.
An Attribution Method for Siamese Encoders
Oct 23, 2023



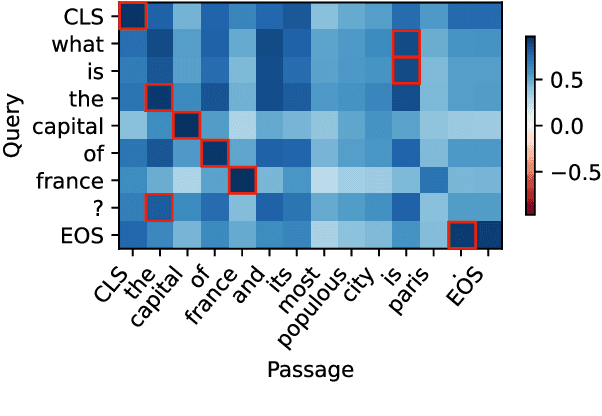
Despite the success of Siamese encoder models such as sentence transformers (ST), little is known about the aspects of inputs they pay attention to. A barrier is that their predictions cannot be attributed to individual features, as they compare two inputs rather than processing a single one. This paper derives a local attribution method for Siamese encoders by generalizing the principle of integrated gradients to models with multiple inputs. The solution takes the form of feature-pair attributions, and can be reduced to a token-token matrix for STs. Our method involves the introduction of integrated Jacobians and inherits the advantageous formal properties of integrated gradients: it accounts for the model's full computation graph and is guaranteed to converge to the actual prediction. A pilot study shows that in an ST few token-pairs can often explain large fractions of predictions, and it focuses on nouns and verbs. For accurate predictions, it however needs to attend to the majority of tokens and parts of speech.
Understanding the Relation of User and News Representations in Content-Based Neural News Recommendation
Jul 29, 2022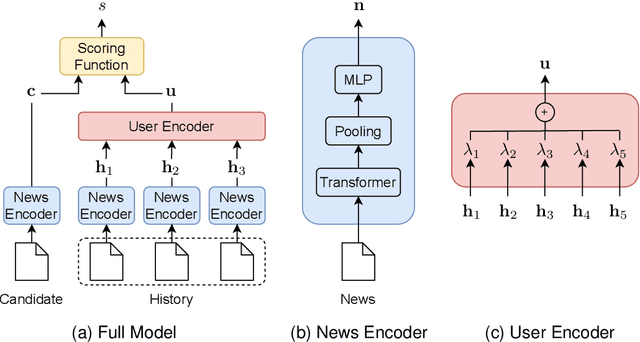
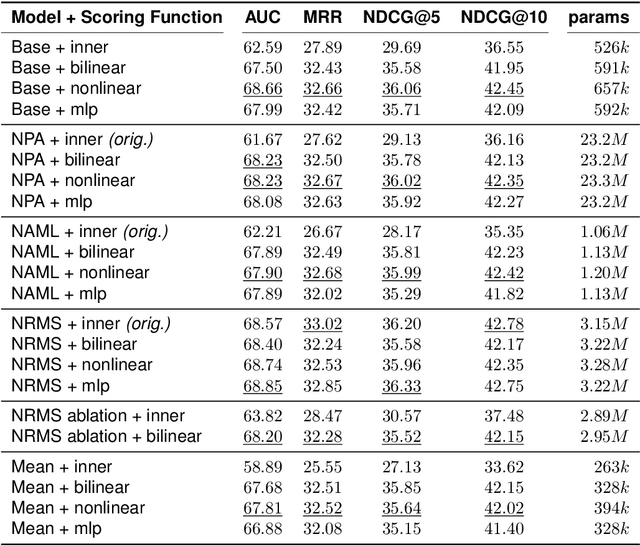
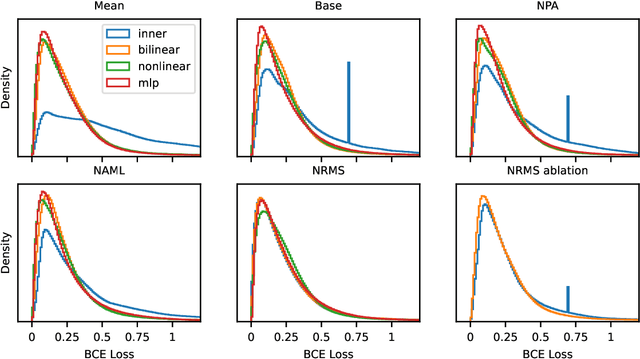
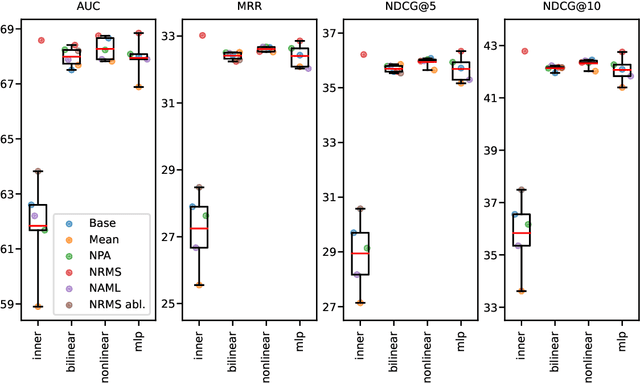
A number of models for neural content-based news recommendation have been proposed. However, there is limited understanding of the relative importances of the three main components of such systems (news encoder, user encoder, and scoring function) and the trade-offs involved. In this paper, we assess the hypothesis that the most widely used means of matching user and candidate news representations is not expressive enough. We allow our system to model more complex relations between the two by assessing more expressive scoring functions. Across a wide range of baseline and established systems this results in consistent improvements of around 6 points in AUC. Our results also indicate a trade-off between the complexity of news encoder and scoring function: A fairly simple baseline model scores well above 68% AUC on the MIND dataset and comes within 2 points of the published state-of-the-art, while requiring a fraction of the computational costs.