 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVD-DIP: Overcoming the Overfitting Problem in DIP-based CT Reconstruction
Mar 28, 2023



The deep image prior (DIP) is a well-established unsupervised deep learning method for image reconstruction; yet it is far from being flawless. The DIP overfits to noise if not early stopped, or optimized via a regularized objective. We build on the regularized fine-tuning of a pretrained DIP, by adopting a novel strategy that restricts the learning to the adaptation of singular values. The proposed SVD-DIP uses ad hoc convolutional layers whose pretrained parameters are decomposed via the singular value decomposition. Optimizing the DIP then solely consists in the fine-tuning of the singular values, while keeping the left and right singular vectors fixed. We thoroughly validate the proposed method on real-measured $\mu$CT data of a lotus root as well as two medical datasets (LoDoPaB and Mayo). We report significantly improved stability of the DIP optimization, by overcoming the overfitting to noise.
Fast and Painless Image Reconstruction in Deep Image Prior Subspaces
Feb 20, 2023



The deep image prior (DIP) is a state-of-the-art unsupervised approach for solving linear inverse problems in imaging. We address two key issues that have held back practical deployment of the DIP: the long computing time needed to train a separate deep network per reconstruction, and the susceptibility to overfitting due to a lack of robust early stopping strategies in the unsupervised setting. To this end, we restrict DIP optimisation to a sparse linear subspace of the full parameter space. We construct the subspace from the principal eigenspace of a set of parameter vectors sampled at equally spaced intervals during DIP pre-training on synthetic task-agnostic data. The low-dimensionality of the resulting subspace reduces DIP's capacity to fit noise and allows the use of fast second order optimisation methods, e.g., natural gradient descent or L-BFGS. Experiments across tomographic tasks of different geometry, ill-posedness and stopping criteria consistently show that second order optimisation in a subspace is Pareto-optimal in terms of optimisation time to reconstruction fidelity trade-off.
Bayesian Experimental Design for Computed Tomography with the Linearised Deep Image Prior
Jul 11, 2022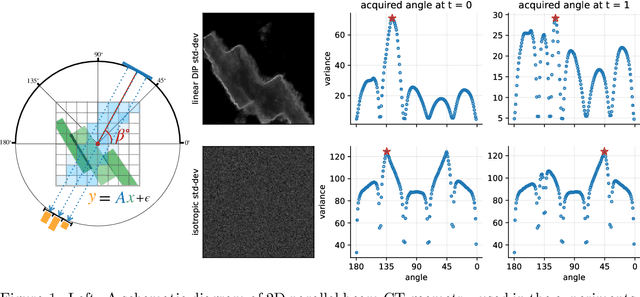

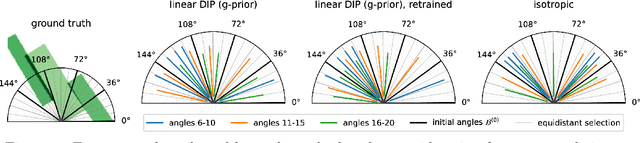

We investigate adaptive design based on a single sparse pilot scan for generating effective scanning strategies for computed tomography reconstruction. We propose a novel approach using the linearised deep image prior. It allows incorporating information from the pilot measurements into the angle selection criteria, while maintaining the tractability of a conjugate Gaussian-linear model. On a synthetically generated dataset with preferential directions, linearised DIP design allows reducing the number of scans by up to 30% relative to an equidistant angle baseline.
A Probabilistic Deep Image Prior for Computational Tomography
Feb 28, 2022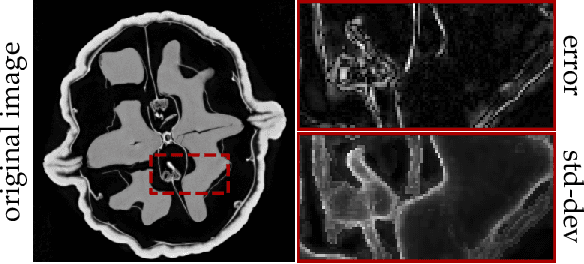
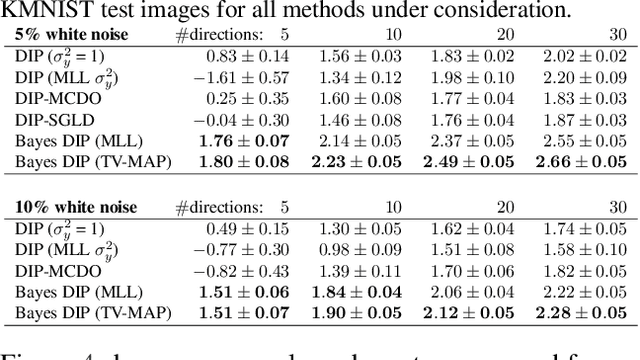

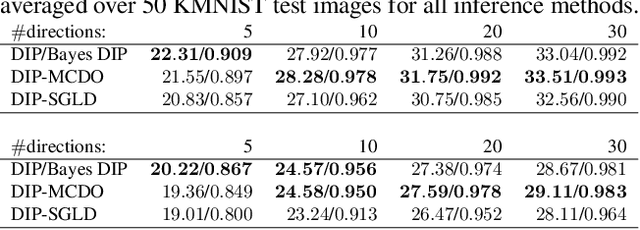
Existing deep-learning based tomographic image reconstruction methods do not provide accurate estimates of reconstruction uncertainty, hindering their real-world deployment. To address this limitation, we construct a Bayesian prior for tomographic reconstruction, which combines the classical total variation (TV) regulariser with the modern deep image prior (DIP). Specifically, we use a change of variables to connect our prior beliefs on the image TV semi-norm with the hyper-parameters of the DIP network. For the inference, we develop an approach based on the linearised Laplace method, which is scalable to high-dimensional settings. The resulting framework provides pixel-wise uncertainty estimates and a marginal likelihood objective for hyperparameter optimisation. We demonstrate the method on synthetic and real-measured high-resolution $\mu$CT data, and show that it provides superior calibration of uncertainty estimates relative to previous probabilistic formulations of the DIP.
Is Deep Image Prior in Need of a Good Education?
Nov 23, 2021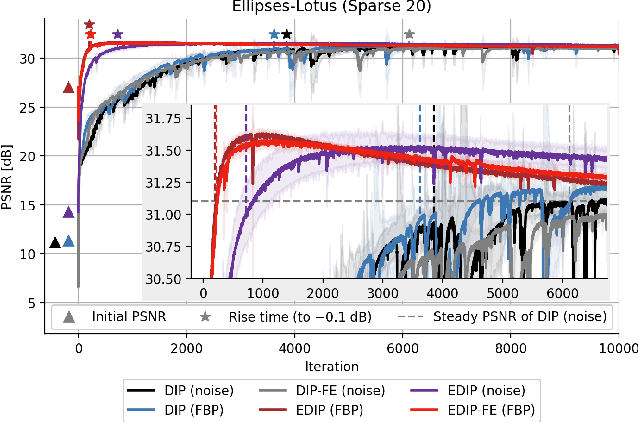
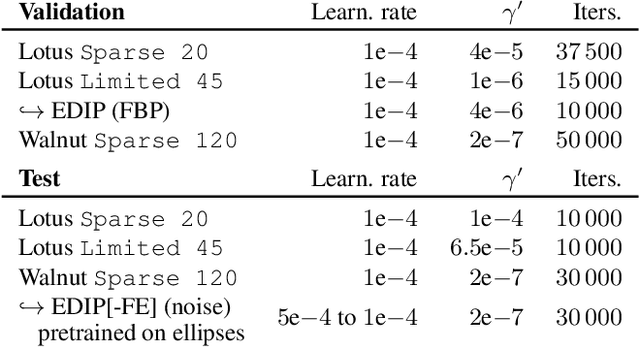
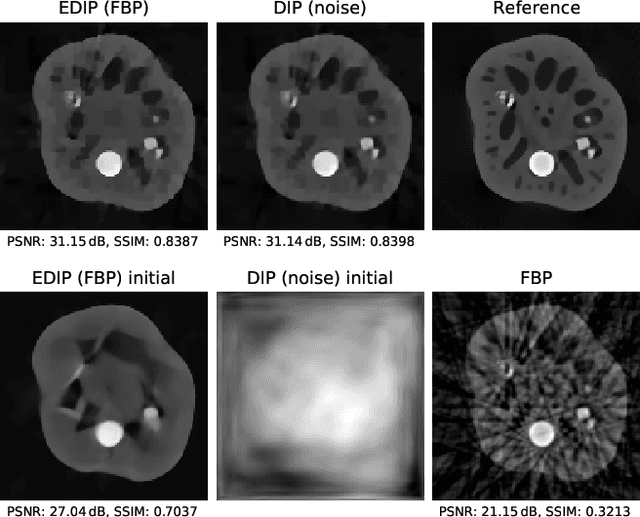

Deep image prior was recently introduced as an effective prior for image reconstruction. It represents the image to be recovered as the output of a deep convolutional neural network, and learns the network's parameters such that the output fits the corrupted observation. Despite its impressive reconstructive properties, the approach is slow when compared to learned or traditional reconstruction techniques. Our work develops a two-stage learning paradigm to address the computational challenge: (i) we perform a supervised pretraining of the network on a synthetic dataset; (ii) we fine-tune the network's parameters to adapt to the target reconstruction. We showcase that pretraining considerably speeds up the subsequent reconstruction from real-measured micro computed tomography data of biological specimens. The code and additional experimental materials are available at https://educateddip.github.io/docs.educated_deep_image_prior/.
Conditional Invertible Neural Networks for Medical Imaging
Oct 26, 2021

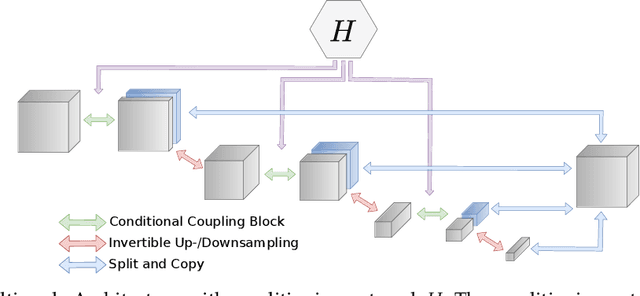
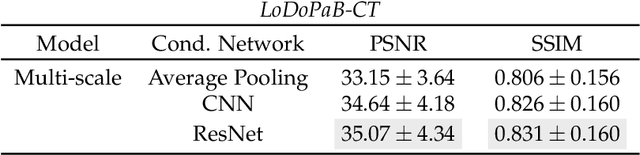
Over the last years, deep learning methods have become an increasingly popular choice to solve tasks from the field of inverse problems. Many of these new data-driven methods have produced impressive results, although most only give point estimates for the reconstruction. However, especially in the analysis of ill-posed inverse problems, the study of uncertainties is essential. In our work, we apply generative flow-based models based on invertible neural networks to two challenging medical imaging tasks, i.e. low-dose computed tomography and accelerated medical resonance imaging. We test different architectures of invertible neural networks and provide extensive ablation studies. In most applications, a standard Gaussian is used as the base distribution for a flow-based model. Our results show that the choice of a radial distribution can improve the quality of reconstructions.
Blind Source Separation in Polyphonic Music Recordings Using Deep Neural Networks Trained via Policy Gradients
Aug 09, 2021
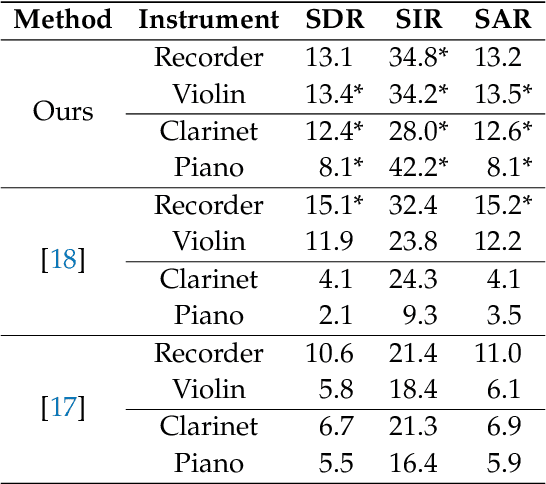
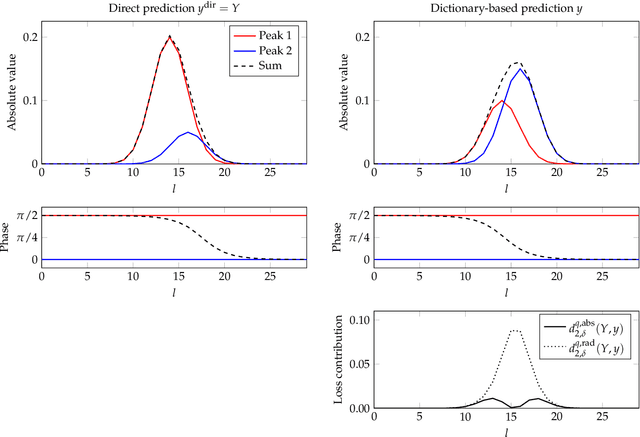
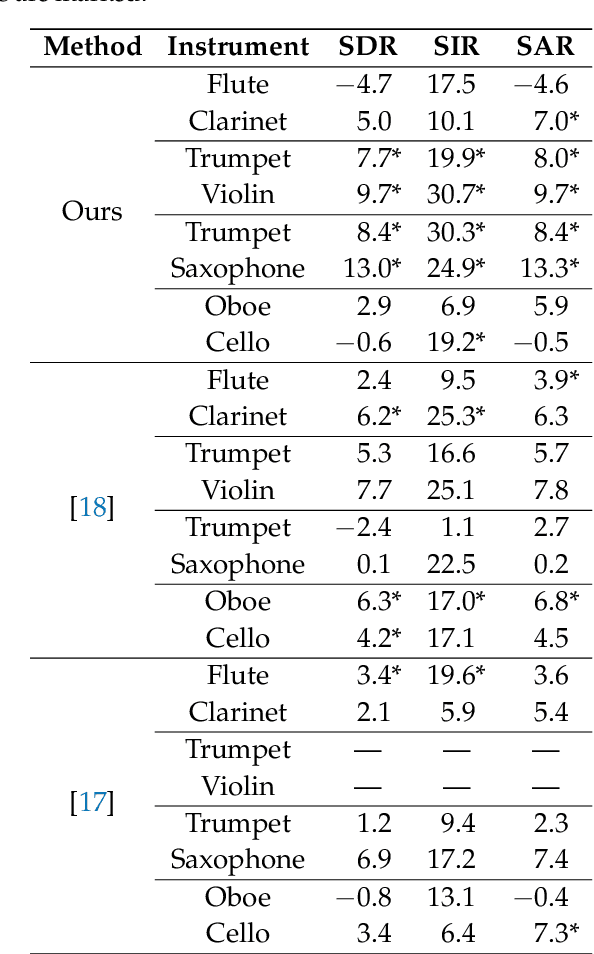
We propose a method for the blind separation of sounds of musical instruments in audio signals. We describe the individual tones via a parametric model, training a dictionary to capture the relative amplitudes of the harmonics. The model parameters are predicted via a U-Net, which is a type of deep neural network. The network is trained without ground truth information, based on the difference between the model prediction and the individual time frames of the short-time Fourier transform. Since some of the model parameters do not yield a useful backpropagation gradient, we model them stochastically and employ the policy gradient instead. To provide phase information and account for inaccuracies in the dictionary-based representation, we also let the network output a direct prediction, which we then use to resynthesize the audio signals for the individual instruments. Due to the flexibility of the neural network, inharmonicity can be incorporated seamlessly and no preprocessing of the input spectra is required. Our algorithm yields high-quality separation results with particularly low interference on a variety of different audio samples, both acoustic and synthetic, provided that the sample contains enough data for the training and that the spectral characteristics of the musical instruments are sufficiently stable to be approximated by the dictionary.
Computed Tomography Reconstruction Using Deep Image Prior and Learned Reconstruction Methods
Mar 12, 2020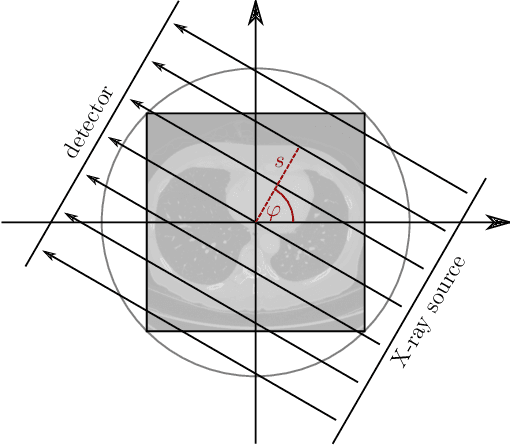
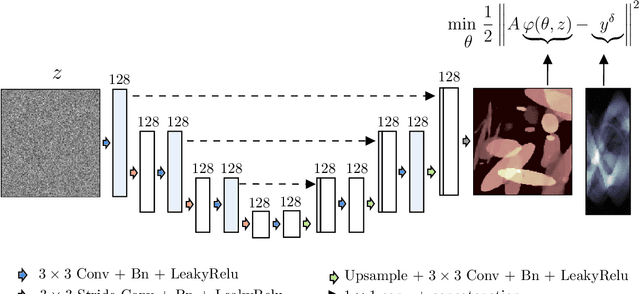

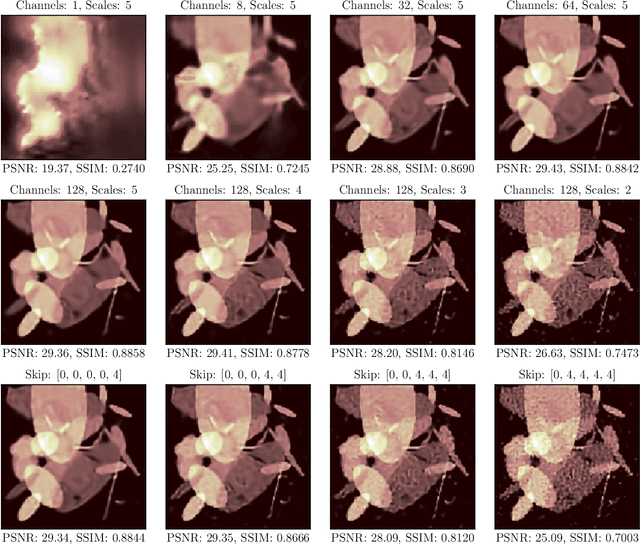
In this work, we investigate the application of deep learning methods for computed tomography in the context of having a low-data regime. As motivation, we review some of the existing approaches and obtain quantitative results after training them with different amounts of data. We find that the learned primal-dual has an outstanding performance in terms of reconstruction quality and data efficiency. However, in general, end-to-end learned methods have two issues: a) lack of classical guarantees in inverse problems and b) lack of generalization when not trained with enough data. To overcome these issues, we bring in the deep image prior approach in combination with classical regularization. The proposed methods improve the state-of-the-art results in the low data-regime.
The LoDoPaB-CT Dataset: A Benchmark Dataset for Low-Dose CT Reconstruction Methods
Oct 01, 2019

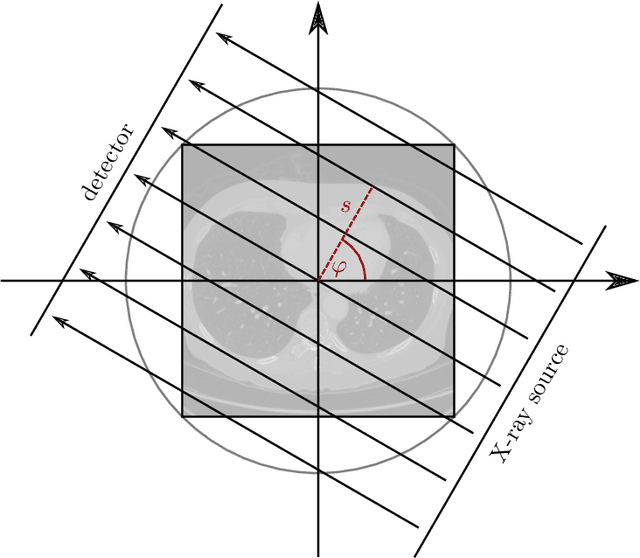
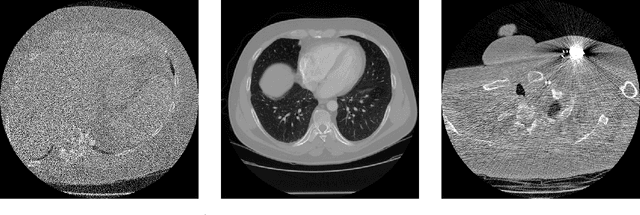
Deep Learning approaches for solving Inverse Problems in imaging have become very effective and are demonstrated to be quite competitive in the field. Comparing these approaches is a challenging task since they highly rely on the data and the setup that is used for training. We provide a public dataset of computed tomography images and simulated low-dose measurements suitable for training this kind of methods. With the LoDoPaB-CT Dataset we aim to create a benchmark that allows for a fair comparison. It contains over 40,000 scan slices from around 800 patients selected from the LIDC/IDRI Database. In this paper we describe how we processed the original slices and how we simulated the measurements. We also include first baseline results.