 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Reasoning in Language Models with Cognitive Tools
Jun 13, 2025The recent advent of reasoning models like OpenAI's o1 was met with excited speculation by the AI community about the mechanisms underlying these capabilities in closed models, followed by a rush of replication efforts, particularly from the open source community. These speculations were largely settled by the demonstration from DeepSeek-R1 that chains-of-thought and reinforcement learning (RL) can effectively replicate reasoning on top of base LLMs. However, it remains valuable to explore alternative methods for theoretically eliciting reasoning that could help elucidate the underlying mechanisms, as well as providing additional methods that may offer complementary benefits. Here, we build on the long-standing literature in cognitive psychology and cognitive architectures, which postulates that reasoning arises from the orchestrated, sequential execution of a set of modular, predetermined cognitive operations. Crucially, we implement this key idea within a modern agentic tool-calling framework. In particular, we endow an LLM with a small set of "cognitive tools" encapsulating specific reasoning operations, each executed by the LLM itself. Surprisingly, this simple strategy results in considerable gains in performance on standard mathematical reasoning benchmarks compared to base LLMs, for both closed and open-weight models. For instance, providing our "cognitive tools" to GPT-4.1 increases its pass@1 performance on AIME2024 from 26.7% to 43.3%, bringing it very close to the performance of o1-preview. In addition to its practical implications, this demonstration contributes to the debate regarding the role of post-training methods in eliciting reasoning in LLMs versus the role of inherent capabilities acquired during pre-training, and whether post-training merely uncovers these latent abilities.
VP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Show or Tell? Effectively prompting Vision-Language Models for semantic segmentation
Mar 25, 2025Large Vision-Language Models (VLMs) are increasingly being regarded as foundation models that can be instructed to solve diverse tasks by prompting, without task-specific training. We examine the seemingly obvious question: how to effectively prompt VLMs for semantic segmentation. To that end, we systematically evaluate the segmentation performance of several recent models guided by either text or visual prompts on the out-of-distribution MESS dataset collection. We introduce a scalable prompting scheme, few-shot prompted semantic segmentation, inspired by open-vocabulary segmentation and few-shot learning. It turns out that VLMs lag far behind specialist models trained for a specific segmentation task, by about 30% on average on the Intersection-over-Union metric. Moreover, we find that text prompts and visual prompts are complementary: each one of the two modes fails on many examples that the other one can solve. Our analysis suggests that being able to anticipate the most effective prompt modality can lead to a 11% improvement in performance. Motivated by our findings, we propose PromptMatcher, a remarkably simple training-free baseline that combines both text and visual prompts, achieving state-of-the-art results outperforming the best text-prompted VLM by 2.5%, and the top visual-prompted VLM by 3.5% on few-shot prompted semantic segmentation.
Prompting-based Synthetic Data Generation for Few-Shot Question Answering
May 15, 2024Although language models (LMs) have boosted the performance of Question Answering, they still need plenty of data. Data annotation, in contrast, is a time-consuming process. This especially applies to Question Answering, where possibly large documents have to be parsed and annotated with questions and their corresponding answers. Furthermore, Question Answering models often only work well for the domain they were trained on. Since annotation is costly, we argue that domain-agnostic knowledge from LMs, such as linguistic understanding, is sufficient to create a well-curated dataset. With this motivation, we show that using large language models can improve Question Answering performance on various datasets in the few-shot setting compared to state-of-the-art approaches. For this, we perform data generation leveraging the Prompting framework, suggesting that language models contain valuable task-agnostic knowledge that can be used beyond the common pre-training/fine-tuning scheme. As a result, we consistently outperform previous approaches on few-shot Question Answering.
Improving Low-Resource Question Answering using Active Learning in Multiple Stages
Nov 27, 2022



Neural approaches have become very popular in the domain of Question Answering, however they require a large amount of annotated data. Furthermore, they often yield very good performance but only in the domain they were trained on. In this work we propose a novel approach that combines data augmentation via question-answer generation with Active Learning to improve performance in low resource settings, where the target domains are diverse in terms of difficulty and similarity to the source domain. We also investigate Active Learning for question answering in different stages, overall reducing the annotation effort of humans. For this purpose, we consider target domains in realistic settings, with an extremely low amount of annotated samples but with many unlabeled documents, which we assume can be obtained with little effort. Additionally, we assume sufficient amount of labeled data from the source domain is available. We perform extensive experiments to find the best setup for incorporating domain experts. Our findings show that our novel approach, where humans are incorporated as early as possible in the process, boosts performance in the low-resource, domain-specific setting, allowing for low-labeling-effort question answering systems in new, specialized domains. They further demonstrate how human annotation affects the performance of QA depending on the stage it is performed.
Enabling Reproducibility and Meta-learning Through a Lifelong Database of Experiments (LDE)
Feb 23, 2022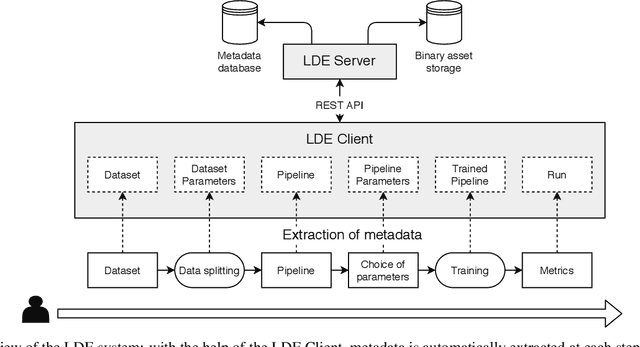
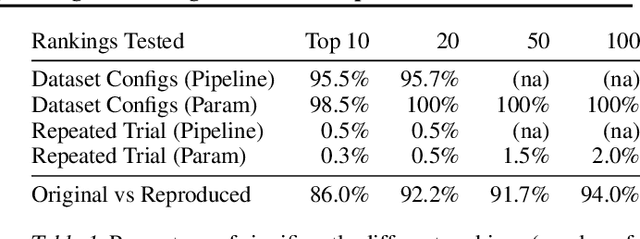
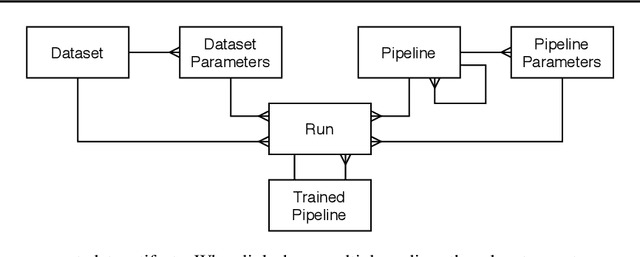

Artificial Intelligence (AI) development is inherently iterative and experimental. Over the course of normal development, especially with the advent of automated AI, hundreds or thousands of experiments are generated and are often lost or never examined again. There is a lost opportunity to document these experiments and learn from them at scale, but the complexity of tracking and reproducing these experiments is often prohibitive to data scientists. We present the Lifelong Database of Experiments (LDE) that automatically extracts and stores linked metadata from experiment artifacts and provides features to reproduce these artifacts and perform meta-learning across them. We store context from multiple stages of the AI development lifecycle including datasets, pipelines, how each is configured, and training runs with information about their runtime environment. The standardized nature of the stored metadata allows for querying and aggregation, especially in terms of ranking artifacts by performance metrics. We exhibit the capabilities of the LDE by reproducing an existing meta-learning study and storing the reproduced metadata in our system. Then, we perform two experiments on this metadata: 1) examining the reproducibility and variability of the performance metrics and 2) implementing a number of meta-learning algorithms on top of the data and examining how variability in experimental results impacts recommendation performance. The experimental results suggest significant variation in performance, especially depending on dataset configurations; this variation carries over when meta-learning is built on top of the results, with performance improving when using aggregated results. This suggests that a system that automatically collects and aggregates results such as the LDE not only assists in implementing meta-learning but may also improve its performance.