 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Reproducibility and Meta-learning Through a Lifelong Database of Experiments (LDE)
Paper and Code
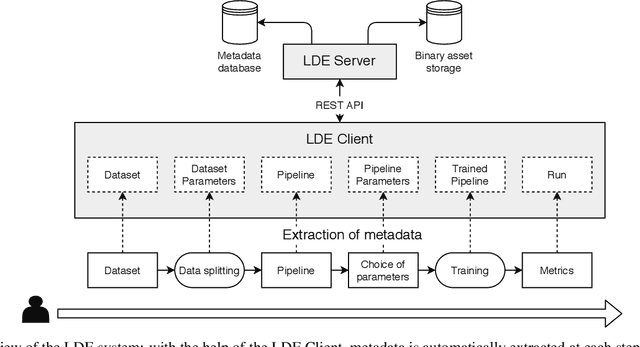
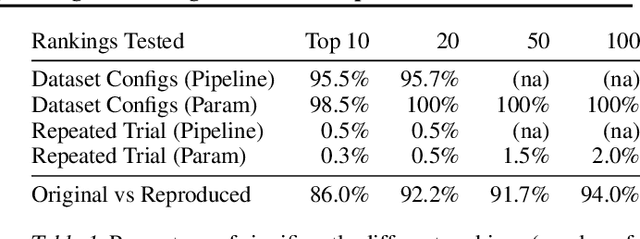
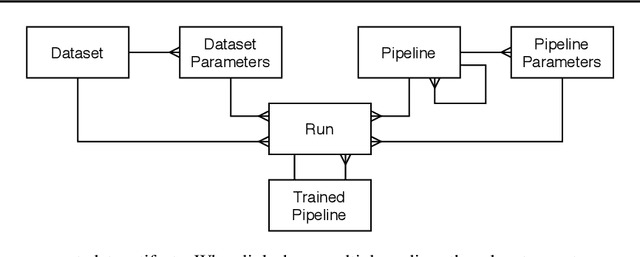

Artificial Intelligence (AI) development is inherently iterative and experimental. Over the course of normal development, especially with the advent of automated AI, hundreds or thousands of experiments are generated and are often lost or never examined again. There is a lost opportunity to document these experiments and learn from them at scale, but the complexity of tracking and reproducing these experiments is often prohibitive to data scientists. We present the Lifelong Database of Experiments (LDE) that automatically extracts and stores linked metadata from experiment artifacts and provides features to reproduce these artifacts and perform meta-learning across them. We store context from multiple stages of the AI development lifecycle including datasets, pipelines, how each is configured, and training runs with information about their runtime environment. The standardized nature of the stored metadata allows for querying and aggregation, especially in terms of ranking artifacts by performance metrics. We exhibit the capabilities of the LDE by reproducing an existing meta-learning study and storing the reproduced metadata in our system. Then, we perform two experiments on this metadata: 1) examining the reproducibility and variability of the performance metrics and 2) implementing a number of meta-learning algorithms on top of the data and examining how variability in experimental results impacts recommendation performance. The experimental results suggest significant variation in performance, especially depending on dataset configurations; this variation carries over when meta-learning is built on top of the results, with performance improving when using aggregated results. This suggests that a system that automatically collects and aggregates results such as the LDE not only assists in implementing meta-learning but may also improve its performance.