 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Show or Tell? Effectively prompting Vision-Language Models for semantic segmentation
Mar 25, 2025Large Vision-Language Models (VLMs) are increasingly being regarded as foundation models that can be instructed to solve diverse tasks by prompting, without task-specific training. We examine the seemingly obvious question: how to effectively prompt VLMs for semantic segmentation. To that end, we systematically evaluate the segmentation performance of several recent models guided by either text or visual prompts on the out-of-distribution MESS dataset collection. We introduce a scalable prompting scheme, few-shot prompted semantic segmentation, inspired by open-vocabulary segmentation and few-shot learning. It turns out that VLMs lag far behind specialist models trained for a specific segmentation task, by about 30% on average on the Intersection-over-Union metric. Moreover, we find that text prompts and visual prompts are complementary: each one of the two modes fails on many examples that the other one can solve. Our analysis suggests that being able to anticipate the most effective prompt modality can lead to a 11% improvement in performance. Motivated by our findings, we propose PromptMatcher, a remarkably simple training-free baseline that combines both text and visual prompts, achieving state-of-the-art results outperforming the best text-prompted VLM by 2.5%, and the top visual-prompted VLM by 3.5% on few-shot prompted semantic segmentation.
Active Learning for Imbalanced Civil Infrastructure Data
Oct 19, 2022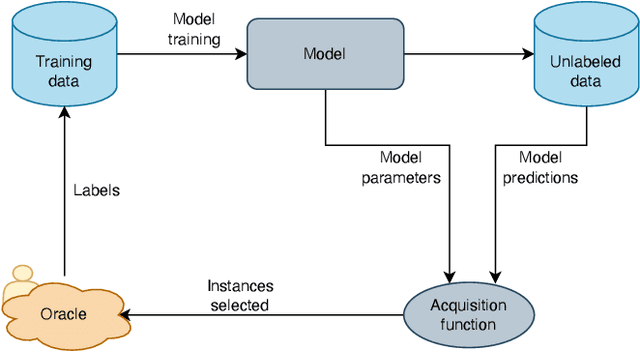


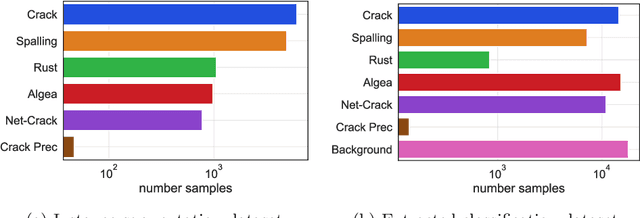
Aging civil infrastructures are closely monitored by engineers for damage and critical defects. As the manual inspection of such large structures is costly and time-consuming, we are working towards fully automating the visual inspections to support the prioritization of maintenance activities. To that end we combine recent advances in drone technology and deep learning. Unfortunately, annotation costs are incredibly high as our proprietary civil engineering dataset must be annotated by highly trained engineers. Active learning is, therefore, a valuable tool to optimize the trade-off between model performance and annotation costs. Our use-case differs from the classical active learning setting as our dataset suffers from heavy class imbalance and consists of a much larger already labeled data pool than other active learning research. We present a novel method capable of operating in this challenging setting by replacing the traditional active learning acquisition function with an auxiliary binary discriminator. We experimentally show that our novel method outperforms the best-performing traditional active learning method (BALD) by 5% and 38% accuracy on CIFAR-10 and our proprietary dataset respectively.