 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenturio: On Drivers of Multilingual Ability of Large Vision-Language Model
Jan 09, 2025



Most Large Vision-Language Models (LVLMs) to date are trained predominantly on English data, which makes them struggle to understand non-English input and fail to generate output in the desired target language. Existing efforts mitigate these issues by adding multilingual training data, but do so in a largely ad-hoc manner, lacking insight into how different training mixes tip the scale for different groups of languages. In this work, we present a comprehensive investigation into the training strategies for massively multilingual LVLMs. First, we conduct a series of multi-stage experiments spanning 13 downstream vision-language tasks and 43 languages, systematically examining: (1) the number of training languages that can be included without degrading English performance and (2) optimal language distributions of pre-training as well as (3) instruction-tuning data. Further, we (4) investigate how to improve multilingual text-in-image understanding, and introduce a new benchmark for the task. Surprisingly, our analysis reveals that one can (i) include as many as 100 training languages simultaneously (ii) with as little as 25-50\% of non-English data, to greatly improve multilingual performance while retaining strong English performance. We further find that (iii) including non-English OCR data in pre-training and instruction-tuning is paramount for improving multilingual text-in-image understanding. Finally, we put all our findings together and train Centurio, a 100-language LVLM, offering state-of-the-art performance in an evaluation covering 14 tasks and 56 languages.
Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models?
Jun 20, 2024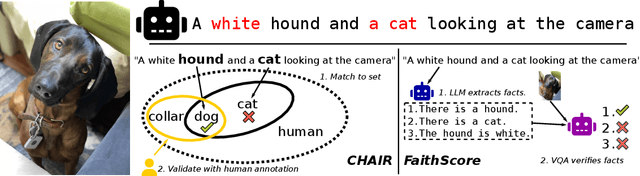



Large vision-language models (LVLMs) have recently dramatically pushed the state of the art in image captioning and many image understanding tasks (e.g., visual question answering). LVLMs, however, often \textit{hallucinate} and produce captions that mention concepts that cannot be found in the image. These hallucinations erode the trustworthiness of LVLMs and are arguably among the main obstacles to their ubiquitous adoption. Recent work suggests that addition of grounding objectives -- those that explicitly align image regions or objects to text spans -- reduces the amount of LVLM hallucination. Although intuitive, this claim is not empirically justified as the reduction effects have been established, we argue, with flawed evaluation protocols that (i) rely on data (i.e., MSCOCO) that has been extensively used in LVLM training and (ii) measure hallucination via question answering rather than open-ended caption generation. In this work, in contrast, we offer the first systematic analysis of the effect of fine-grained object grounding on LVLM hallucination under an evaluation protocol that more realistically captures LVLM hallucination in open generation. Our extensive experiments over three backbone LLMs reveal that grounding objectives have little to no effect on object hallucination in open caption generation.
African or European Swallow? Benchmarking Large Vision-Language Models for Fine-Grained Object Classification
Jun 20, 2024Recent Large Vision-Language Models (LVLMs) demonstrate impressive abilities on numerous image understanding and reasoning tasks. The task of fine-grained object classification (e.g., distinction between \textit{animal species}), however, has been probed insufficiently, despite its downstream importance. We fill this evaluation gap by creating \texttt{FOCI} (\textbf{F}ine-grained \textbf{O}bject \textbf{C}lass\textbf{I}fication), a difficult multiple-choice benchmark for fine-grained object classification, from existing object classification datasets: (1) multiple-choice avoids ambiguous answers associated with casting classification as open-ended QA task; (2) we retain classification difficulty by mining negative labels with a CLIP model. \texttt{FOCI}\xspace complements five popular classification datasets with four domain-specific subsets from ImageNet-21k. We benchmark 12 public LVLMs on \texttt{FOCI} and show that it tests for a \textit{complementary skill} to established image understanding and reasoning benchmarks. Crucially, CLIP models exhibit dramatically better performance than LVLMs. Since the image encoders of LVLMs come from these CLIP models, this points to inadequate alignment for fine-grained object distinction between the encoder and the LLM and warrants (pre)training data with more fine-grained annotation. We release our code at \url{https://github.com/gregor-ge/FOCI-Benchmark}.
High-Quality Image Restoration Following Human Instructions
Jan 31, 2024Image restoration is a fundamental problem that involves recovering a high-quality clean image from its degraded observation. All-In-One image restoration models can effectively restore images from various types and levels of degradation using degradation-specific information as prompts to guide the restoration model. In this work, we present the first approach that uses human-written instructions to guide the image restoration model. Given natural language prompts, our model can recover high-quality images from their degraded counterparts, considering multiple degradation types. Our method, InstructIR, achieves state-of-the-art results on several restoration tasks including image denoising, deraining, deblurring, dehazing, and (low-light) image enhancement. InstructIR improves +1dB over previous all-in-one restoration methods. Moreover, our dataset and results represent a novel benchmark for new research on text-guided image restoration and enhancement. Our code, datasets and models are available at: https://github.com/mv-lab/InstructIR
mBLIP: Efficient Bootstrapping of Multilingual Vision-LLMs
Jul 13, 2023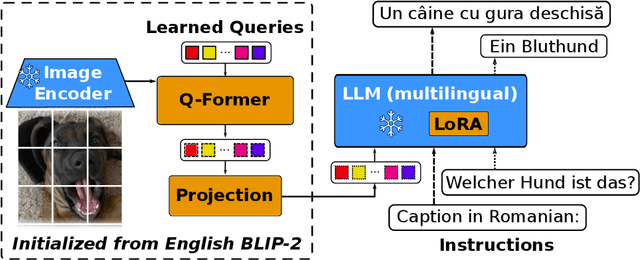
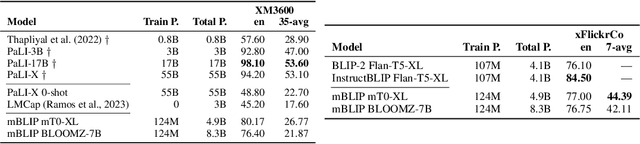
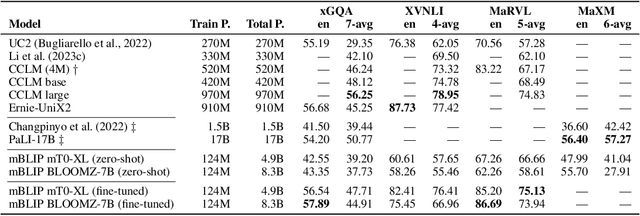
Modular vision-language models (Vision-LLMs) align pretrained image encoders with (pretrained) large language models (LLMs), representing a computationally much more efficient alternative to end-to-end training of large vision-language models from scratch, which is prohibitively expensive for most. Vision-LLMs instead post-hoc condition LLMs to `understand' the output of an image encoder. With the abundance of readily available high-quality English image-text data as well as monolingual English LLMs, the research focus has been on English-only Vision-LLMs. Multilingual vision-language models are still predominantly obtained via expensive end-to-end pretraining, resulting in comparatively smaller models, trained on limited multilingual image data supplemented with text-only multilingual corpora. In this work, we present mBLIP, the first multilingual Vision-LLM, which we obtain in a computationally efficient manner -- on consumer hardware using only a few million training examples -- by leveraging a pretrained multilingual LLM. To this end, we \textit{re-align} an image encoder previously tuned to an English LLM to a new, multilingual LLM -- for this, we leverage multilingual data from a mix of vision-and-language tasks, which we obtain by machine-translating high-quality English data to 95 languages. On the IGLUE benchmark, mBLIP yields results competitive with state-of-the-art models. Moreover, in image captioning on XM3600, mBLIP (zero-shot) even outperforms PaLI-X (a model with 55B parameters). Compared to these very large multilingual vision-language models trained from scratch, we obtain mBLIP by training orders of magnitude fewer parameters on magnitudes less data. We release our model and code at \url{https://github.com/gregor-ge/mBLIP}.
Babel-ImageNet: Massively Multilingual Evaluation of Vision-and-Language Representations
Jun 14, 2023



Vision-and-language (VL) models with separate encoders for each modality (e.g., CLIP) have become the go-to models for zero-shot image classification and image-text retrieval. The bulk of the evaluation of these models is, however, performed with English text only: the costly creation of language-specific image-caption datasets has limited multilingual VL benchmarks to a handful of high-resource languages. In this work, we introduce Babel-ImageNet, a massively multilingual benchmark that offers (partial) translations of 1000 ImageNet labels to 92 languages, built without resorting to machine translation (MT) or requiring manual annotation. We instead automatically obtain reliable translations of ImageNext concepts by linking them -- via shared WordNet synsets -- to BabelNet, a massively multilingual lexico-semantic network. We evaluate 8 different publicly available multilingual CLIP models on zero-shot image classification (ZS-IC) for each of the 92 Babel-ImageNet languages, demonstrating a significant gap between English ImageNet performance and that of high-resource languages (e.g., German or Chinese), and an even bigger gap for low-resource languages (e.g., Sinhala or Lao). Crucially, we show that the models' ZS-IC performance on Babel-ImageNet highly correlates with their performance in image-text retrieval, validating that Babel-ImageNet is suitable for estimating the quality of the multilingual VL representation spaces for the vast majority of languages that lack gold image-text data. Finally, we show that the performance of multilingual CLIP for low-resource languages can be drastically improved via cheap, parameter-efficient language-specific training. We make our code and data publicly available: \url{https://github.com/gregor-ge/Babel-ImageNet}
One does not fit all! On the Complementarity of Vision Encoders for Vision and Language Tasks
Oct 12, 2022Current multimodal models, aimed at solving Vision and Language (V+L) tasks, predominantly repurpose Vision Encoders (VE) as feature extractors. While many VEs -- of different architectures, trained on different data and objectives -- are publicly available, they are not designed for the downstream V+L tasks. Nonetheless, most current work assumes that a \textit{single} pre-trained VE can serve as a general-purpose encoder. In this work, we evaluate whether the information stored within different VEs is complementary, i.e. if providing the model with features from multiple VEs can improve the performance on a target task. We exhaustively experiment with three popular VEs on six downstream V+L tasks and analyze the attention and VE-dropout patterns. Our results and analyses suggest that diverse VEs complement each other, resulting in improved downstream V+L task performance, where the improvements are not due to simple ensemble effects (i.e. the performance does not always improve when increasing the number of encoders). We demonstrate that future VEs, which are not \textit{repurposed}, but explicitly \textit{designed} for V+L tasks, have the potential of improving performance on the target V+L tasks.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022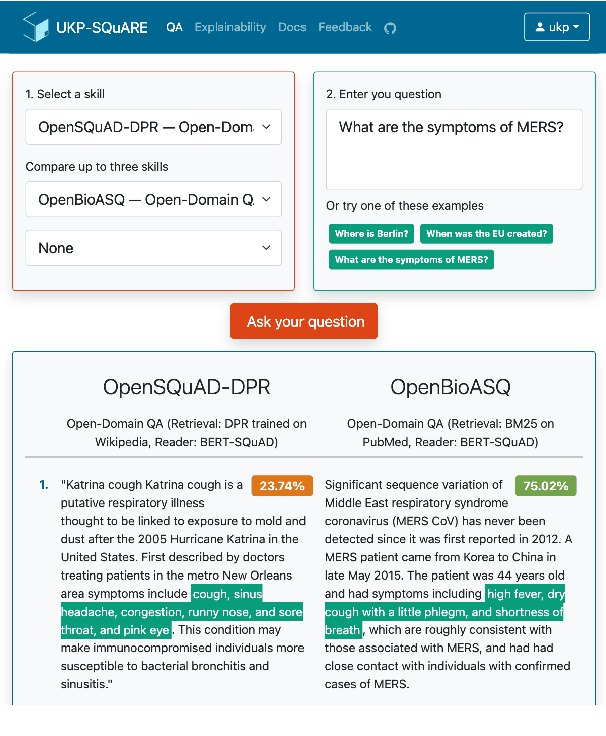

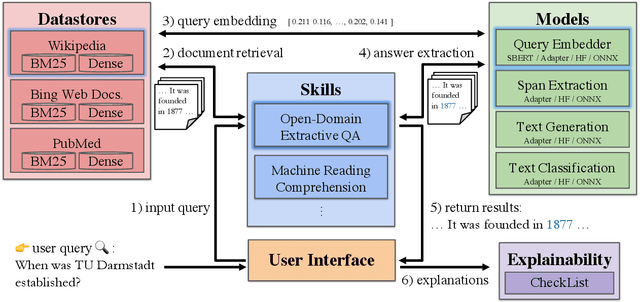
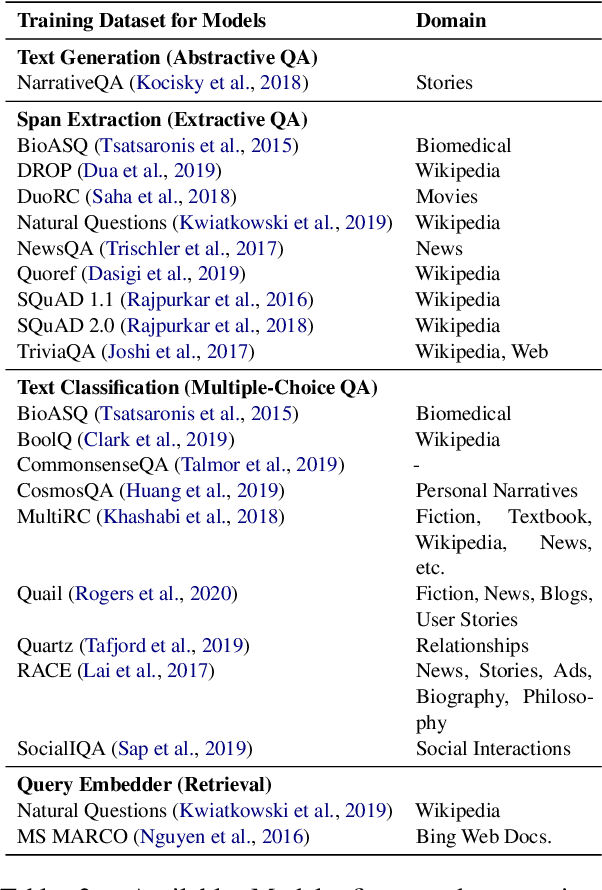
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
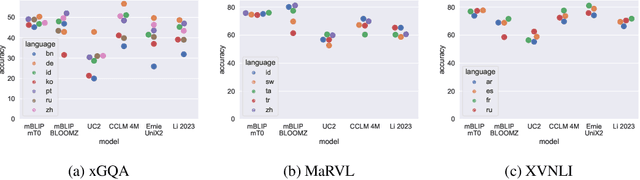
xGQA: Cross-Lingual Visual Question Answering
Sep 13, 2021
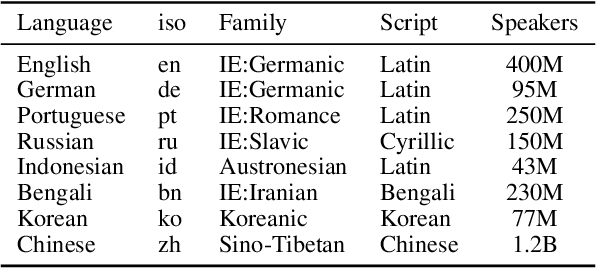

Recent advances in multimodal vision and language modeling have predominantly focused on the English language, mostly due to the lack of multilingual multimodal datasets to steer modeling efforts. In this work, we address this gap and provide xGQA, a new multilingual evaluation benchmark for the visual question answering task. We extend the established English GQA dataset to 7 typologically diverse languages, enabling us to detect and explore crucial challenges in cross-lingual visual question answering. We further propose new adapter-based approaches to adapt multimodal transformer-based models to become multilingual, and -- vice versa -- multilingual models to become multimodal. Our proposed methods outperform current state-of-the-art multilingual multimodal models (e.g., M3P) in zero-shot cross-lingual settings, but the accuracy remains low across the board; a performance drop of around 38 accuracy points in target languages showcases the difficulty of zero-shot cross-lingual transfer for this task. Our results suggest that simple cross-lingual transfer of multimodal models yields latent multilingual multimodal misalignment, calling for more sophisticated methods for vision and multilingual language modeling. The xGQA dataset is available online at: https://github.com/Adapter-Hub/xGQA.
TWEAC: Transformer with Extendable QA Agent Classifiers
Apr 14, 2021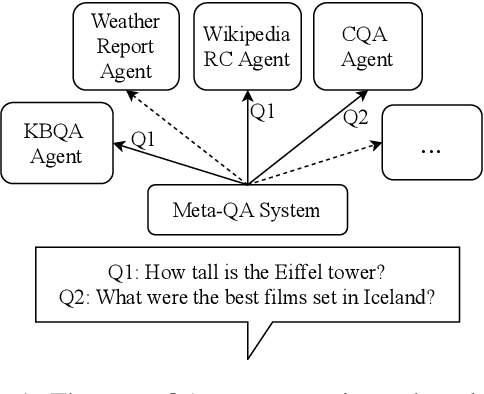

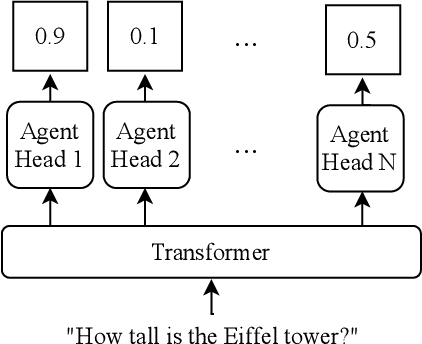

Question answering systems should help users to access knowledge on a broad range of topics and to answer a wide array of different questions. Most systems fall short of this expectation as they are only specialized in one particular setting, e.g., answering factual questions with Wikipedia data. To overcome this limitation, we propose composing multiple QA agents within a meta-QA system. We argue that there exist a wide range of specialized QA agents in literature. Thus, we address the central research question of how to effectively and efficiently identify suitable QA agents for any given question. We study both supervised and unsupervised approaches to address this challenge, showing that TWEAC - Transformer with Extendable Agent Classifiers - achieves the best performance overall with 94% accuracy. We provide extensive insights on the scalability of TWEAC, demonstrating that it scales robustly to over 100 QA agents with each providing just 1000 examples of questions they can answer.