 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapters Strike Back
Jun 10, 2024



Adapters provide an efficient and lightweight mechanism for adapting trained transformer models to a variety of different tasks. However, they have often been found to be outperformed by other adaptation mechanisms, including low-rank adaptation. In this paper, we provide an in-depth study of adapters, their internal structure, as well as various implementation choices. We uncover pitfalls for using adapters and suggest a concrete, improved adapter architecture, called Adapter+, that not only outperforms previous adapter implementations but surpasses a number of other, more complex adaptation mechanisms in several challenging settings. Despite this, our suggested adapter is highly robust and, unlike previous work, requires little to no manual intervention when addressing a novel scenario. Adapter+ reaches state-of-the-art average accuracy on the VTAB benchmark, even without a per-task hyperparameter optimization.
xGQA: Cross-Lingual Visual Question Answering
Sep 13, 2021
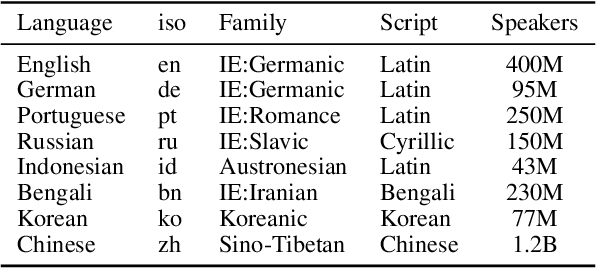

Recent advances in multimodal vision and language modeling have predominantly focused on the English language, mostly due to the lack of multilingual multimodal datasets to steer modeling efforts. In this work, we address this gap and provide xGQA, a new multilingual evaluation benchmark for the visual question answering task. We extend the established English GQA dataset to 7 typologically diverse languages, enabling us to detect and explore crucial challenges in cross-lingual visual question answering. We further propose new adapter-based approaches to adapt multimodal transformer-based models to become multilingual, and -- vice versa -- multilingual models to become multimodal. Our proposed methods outperform current state-of-the-art multilingual multimodal models (e.g., M3P) in zero-shot cross-lingual settings, but the accuracy remains low across the board; a performance drop of around 38 accuracy points in target languages showcases the difficulty of zero-shot cross-lingual transfer for this task. Our results suggest that simple cross-lingual transfer of multimodal models yields latent multilingual multimodal misalignment, calling for more sophisticated methods for vision and multilingual language modeling. The xGQA dataset is available online at: https://github.com/Adapter-Hub/xGQA.
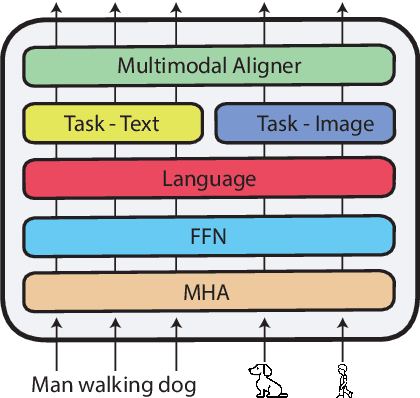
TxT: Crossmodal End-to-End Learning with Transformers
Sep 09, 2021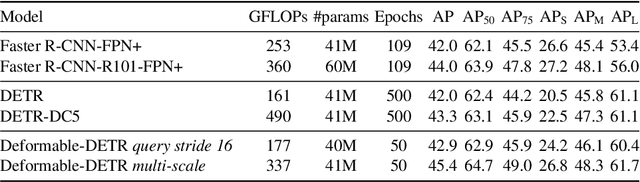
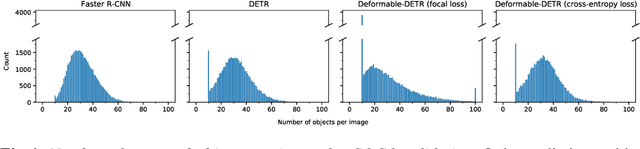
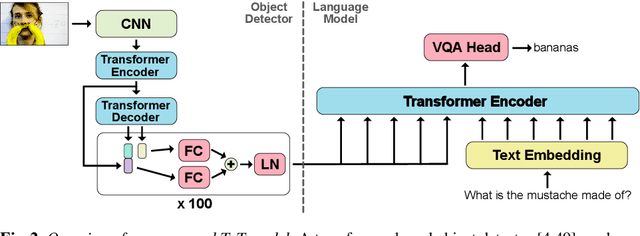

Reasoning over multiple modalities, e.g. in Visual Question Answering (VQA), requires an alignment of semantic concepts across domains. Despite the widespread success of end-to-end learning, today's multimodal pipelines by and large leverage pre-extracted, fixed features from object detectors, typically Faster R-CNN, as representations of the visual world. The obvious downside is that the visual representation is not specifically tuned to the multimodal task at hand. At the same time, while transformer-based object detectors have gained popularity, they have not been employed in today's multimodal pipelines. We address both shortcomings with TxT, a transformer-based crossmodal pipeline that enables fine-tuning both language and visual components on the downstream task in a fully end-to-end manner. We overcome existing limitations of transformer-based detectors for multimodal reasoning regarding the integration of global context and their scalability. Our transformer-based multimodal model achieves considerable gains from end-to-end learning for multimodal question answering.