 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTxT: Crossmodal End-to-End Learning with Transformers
Paper and Code
Sep 09, 2021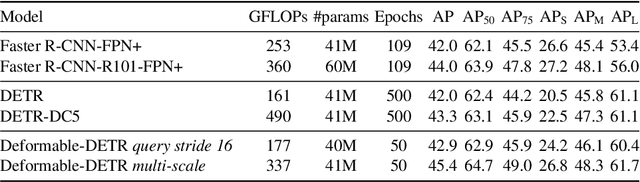
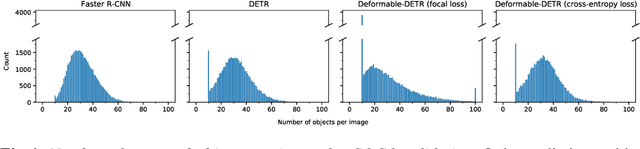
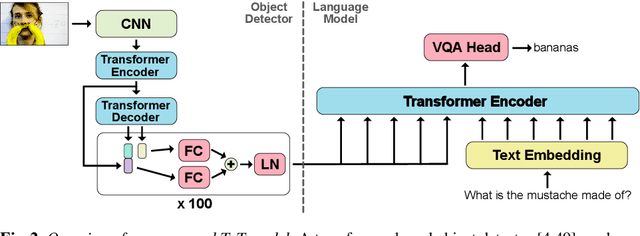

Reasoning over multiple modalities, e.g. in Visual Question Answering (VQA), requires an alignment of semantic concepts across domains. Despite the widespread success of end-to-end learning, today's multimodal pipelines by and large leverage pre-extracted, fixed features from object detectors, typically Faster R-CNN, as representations of the visual world. The obvious downside is that the visual representation is not specifically tuned to the multimodal task at hand. At the same time, while transformer-based object detectors have gained popularity, they have not been employed in today's multimodal pipelines. We address both shortcomings with TxT, a transformer-based crossmodal pipeline that enables fine-tuning both language and visual components on the downstream task in a fully end-to-end manner. We overcome existing limitations of transformer-based detectors for multimodal reasoning regarding the integration of global context and their scalability. Our transformer-based multimodal model achieves considerable gains from end-to-end learning for multimodal question answering.