 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023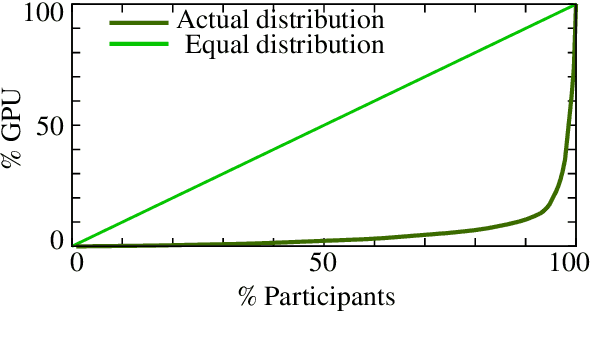

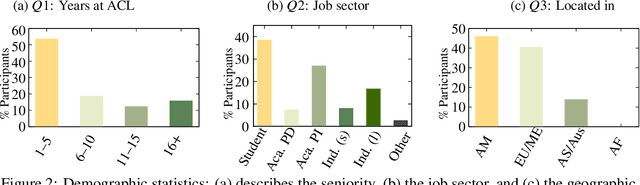
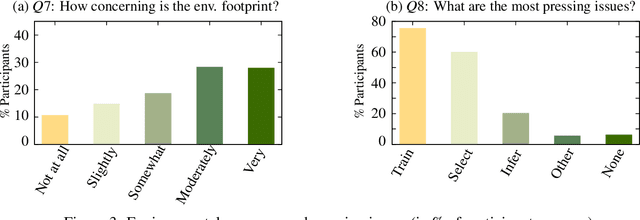
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Apr 28, 2021
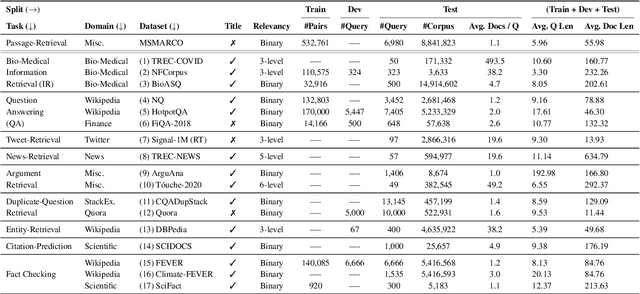


Neural IR models have often been studied in homogeneous and narrow settings, which has considerably limited insights into their generalization capabilities. To address this, and to allow researchers to more broadly establish the effectiveness of their models, we introduce BEIR (Benchmarking IR), a heterogeneous benchmark for information retrieval. We leverage a careful selection of 17 datasets for evaluation spanning diverse retrieval tasks including open-domain datasets as well as narrow expert domains. We study the effectiveness of nine state-of-the-art retrieval models in a zero-shot evaluation setup on BEIR, finding that performing well consistently across all datasets is challenging. Our results show BM25 is a robust baseline and Reranking-based models overall achieve the best zero-shot performances, however, at high computational costs. In contrast, Dense-retrieval models are computationally more efficient but often underperform other approaches, highlighting the considerable room for improvement in their generalization capabilities. In this work, we extensively analyze different retrieval models and provide several suggestions that we believe may be useful for future work. BEIR datasets and code are available at https://github.com/UKPLab/beir.
Learning to Reason for Text Generation from Scientific Tables
Apr 16, 2021
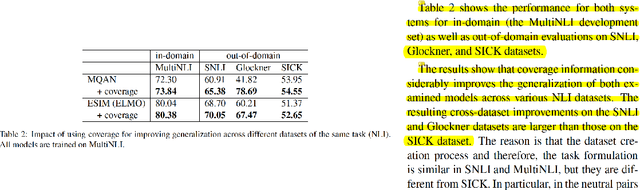


In this paper, we introduce SciGen, a new challenge dataset for the task of reasoning-aware data-to-text generation consisting of tables from scientific articles and their corresponding descriptions. Describing scientific tables goes beyond the surface realization of the table content and requires reasoning over table values. The unique properties of SciGen are that (1) tables mostly contain numerical values, and (2) the corresponding descriptions require arithmetic reasoning. SciGen is therefore the first dataset that assesses the arithmetic reasoning capabilities of generation models on complex input structures, i.e., tables from scientific articles. We study the effectiveness of state-of-the-art data-to-text generation models on SciGen and evaluate the results using common metrics as well as human evaluation. Our results and analyses show that (a) while humans like to reason for describing scientific tables, the ability of state-of-the-art models is severely limited on this task, (b) while adding more training data improves the results, it is not the solution for reasoning-aware text generation, and (c) one of the main bottlenecks for this task is the lack of proper automatic evaluation metrics. The data, code, and annotations for human evaluation will be available at https://github.com/UKPLab/SciGen. SciGen opens new avenues for future research in reasoning-aware text generation and evaluation.
What to Pre-Train on? Efficient Intermediate Task Selection
Apr 16, 2021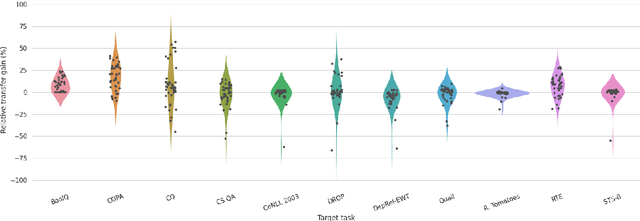
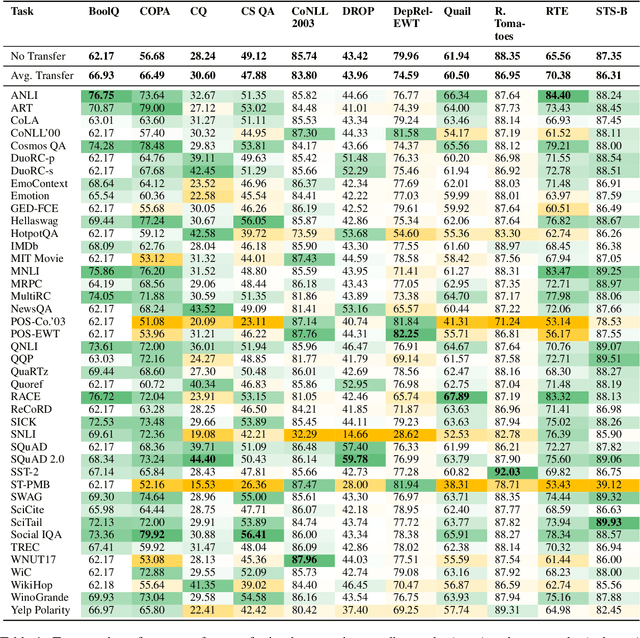
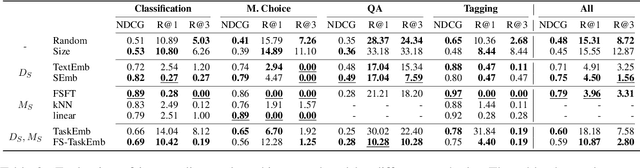
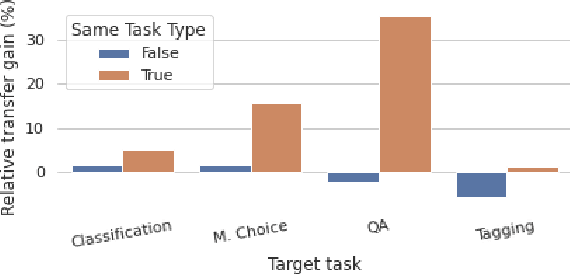
Intermediate task fine-tuning has been shown to culminate in large transfer gains across many NLP tasks. With an abundance of candidate datasets as well as pre-trained language models, it has become infeasible to run the cross-product of all combinations to find the best transfer setting. In this work we first establish that similar sequential fine-tuning gains can be achieved in adapter settings, and subsequently consolidate previously proposed methods that efficiently identify beneficial tasks for intermediate transfer learning. We experiment with a diverse set of 42 intermediate and 11 target English classification, multiple choice, question answering, and sequence tagging tasks. Our results show that efficient embedding based methods that rely solely on the respective datasets outperform computational expensive few-shot fine-tuning approaches. Our best methods achieve an average Regret@3 of less than 1% across all target tasks, demonstrating that we are able to efficiently identify the best datasets for intermediate training.
TWEAC: Transformer with Extendable QA Agent Classifiers
Apr 14, 2021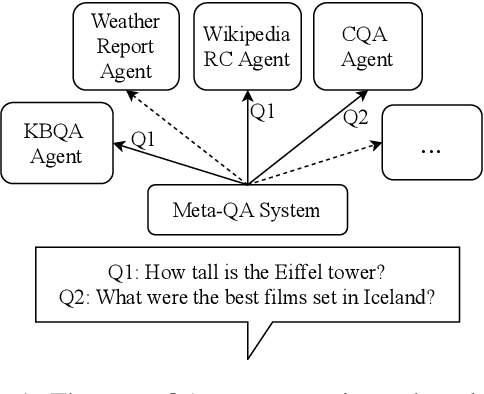

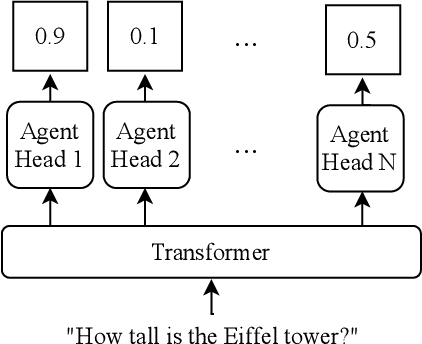

Question answering systems should help users to access knowledge on a broad range of topics and to answer a wide array of different questions. Most systems fall short of this expectation as they are only specialized in one particular setting, e.g., answering factual questions with Wikipedia data. To overcome this limitation, we propose composing multiple QA agents within a meta-QA system. We argue that there exist a wide range of specialized QA agents in literature. Thus, we address the central research question of how to effectively and efficiently identify suitable QA agents for any given question. We study both supervised and unsupervised approaches to address this challenge, showing that TWEAC - Transformer with Extendable Agent Classifiers - achieves the best performance overall with 94% accuracy. We provide extensive insights on the scalability of TWEAC, demonstrating that it scales robustly to over 100 QA agents with each providing just 1000 examples of questions they can answer.
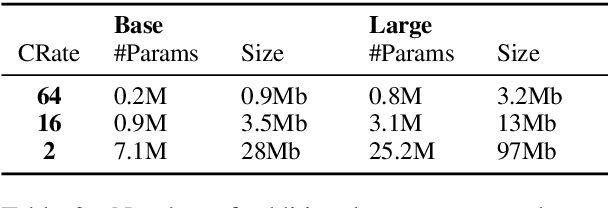
AdapterDrop: On the Efficiency of Adapters in Transformers
Oct 22, 2020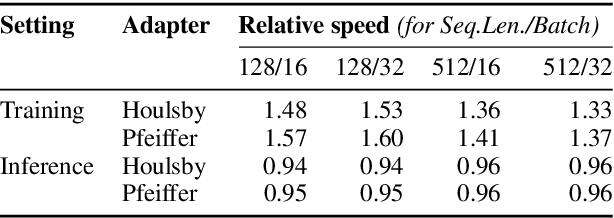
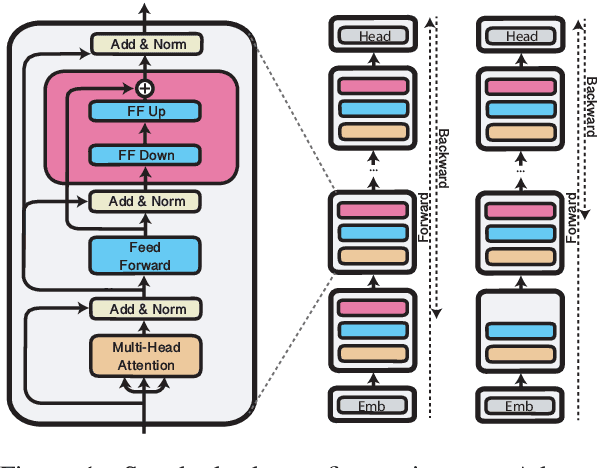

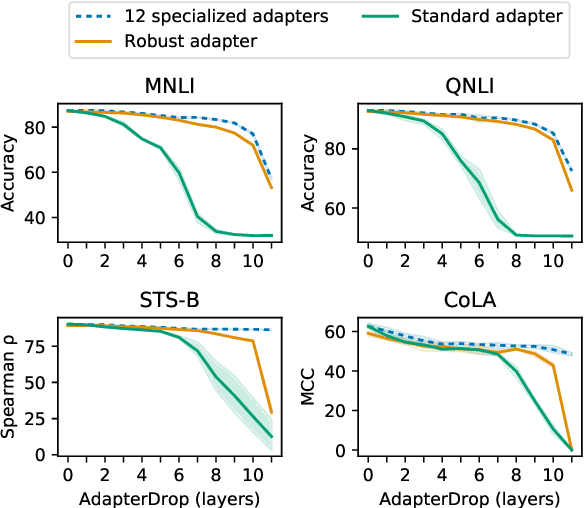
Massively pre-trained transformer models are computationally expensive to fine-tune, slow for inference, and have large storage requirements. Recent approaches tackle these shortcomings by training smaller models, dynamically reducing the model size, and by training light-weight adapters. In this paper, we propose AdapterDrop, removing adapters from lower transformer layers during training and inference, which incorporates concepts from all three directions. We show that AdapterDrop can dynamically reduce the computational overhead when performing inference over multiple tasks simultaneously, with minimal decrease in task performances. We further prune adapters from AdapterFusion, which improves the inference efficiency while maintaining the task performances entirely.
Improving QA Generalization by Concurrent Modeling of Multiple Biases
Oct 07, 2020
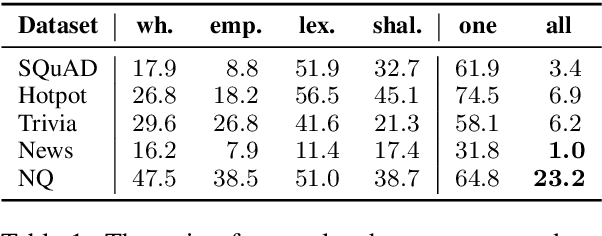
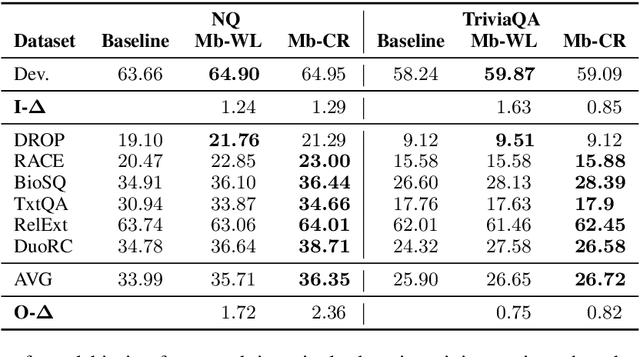
Existing NLP datasets contain various biases that models can easily exploit to achieve high performances on the corresponding evaluation sets. However, focusing on dataset-specific biases limits their ability to learn more generalizable knowledge about the task from more general data patterns. In this paper, we investigate the impact of debiasing methods for improving generalization and propose a general framework for improving the performance on both in-domain and out-of-domain datasets by concurrent modeling of multiple biases in the training data. Our framework weights each example based on the biases it contains and the strength of those biases in the training data. It then uses these weights in the training objective so that the model relies less on examples with high bias weights. We extensively evaluate our framework on extractive question answering with training data from various domains with multiple biases of different strengths. We perform the evaluations in two different settings, in which the model is trained on a single domain or multiple domains simultaneously, and show its effectiveness in both settings compared to state-of-the-art debiasing methods.
MultiCQA: Zero-Shot Transfer of Self-Supervised Text Matching Models on a Massive Scale
Oct 02, 2020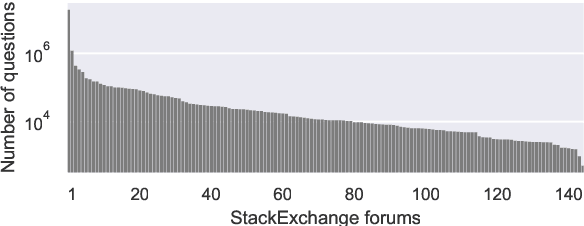
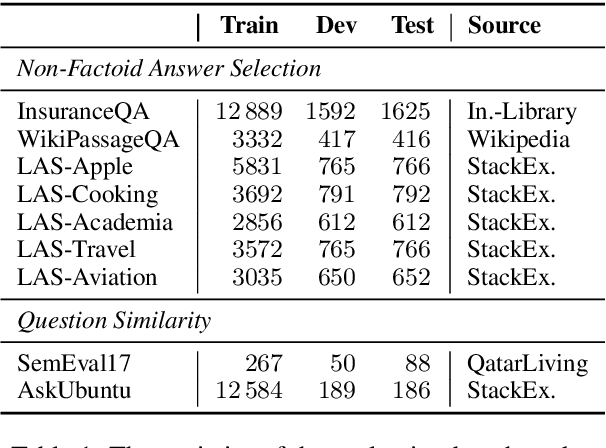
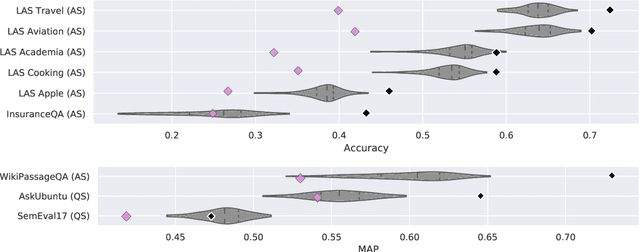
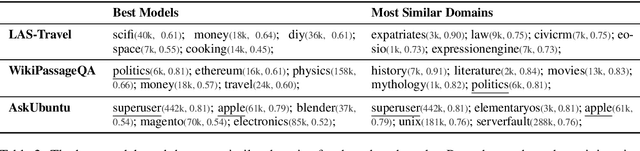
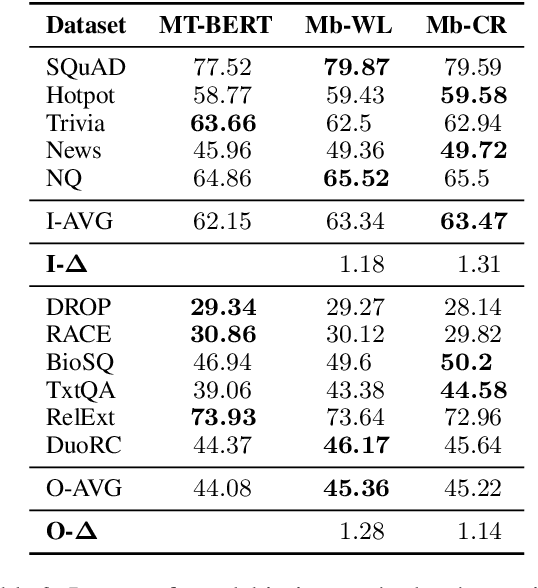
We study the zero-shot transfer capabilities of text matching models on a massive scale, by self-supervised training on 140 source domains from community question answering forums in English. We investigate the model performances on nine benchmarks of answer selection and question similarity tasks, and show that all 140 models transfer surprisingly well, where the large majority of models substantially outperforms common IR baselines. We also demonstrate that considering a broad selection of source domains is crucial for obtaining the best zero-shot transfer performances, which contrasts the standard procedure that merely relies on the largest and most similar domains. In addition, we extensively study how to best combine multiple source domains. We propose to incorporate self-supervised with supervised multi-task learning on all available source domains. Our best zero-shot transfer model considerably outperforms in-domain BERT and the previous state of the art on six benchmarks. Fine-tuning of our model with in-domain data results in additional large gains and achieves the new state of the art on all nine benchmarks.
AdapterHub: A Framework for Adapting Transformers
Jul 15, 2020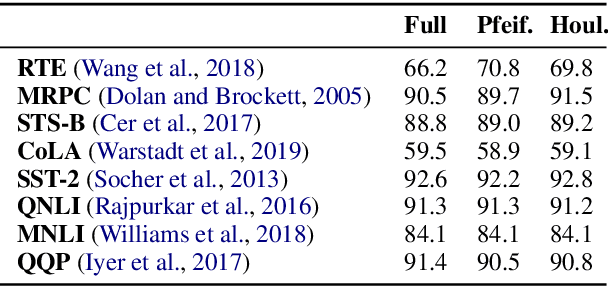
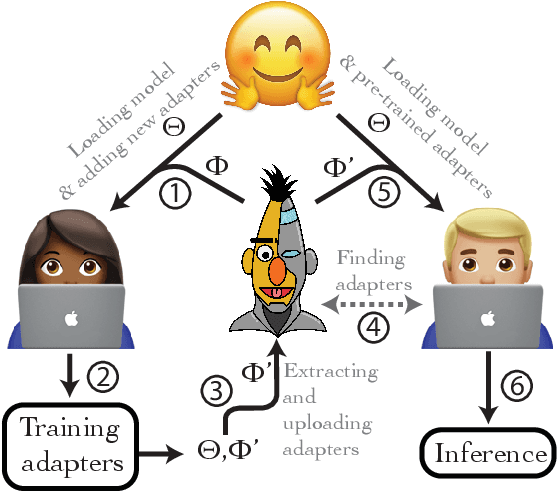

The current modus operandi in NLP involves downloading and fine-tuning pre-trained models consisting of millions or billions of parameters. Storing and sharing such large trained models is expensive, slow, and time-consuming, which impedes progress towards more general and versatile NLP methods that learn from and for many tasks. Adapters -- small learnt bottleneck layers inserted within each layer of a pre-trained model -- ameliorate this issue by avoiding full fine-tuning of the entire model. However, sharing and integrating adapter layers is not straightforward. We propose AdapterHub, a framework that allows dynamic "stitching-in" of pre-trained adapters for different tasks and languages. The framework, built on top of the popular HuggingFace Transformers library, enables extremely easy and quick adaptations of state-of-the-art pre-trained models (e.g., BERT, RoBERTa, XLM-R) across tasks and languages. Downloading, sharing, and training adapters is as seamless as possible using minimal changes to the training scripts and a specialized infrastructure. Our framework enables scalable and easy access to sharing of task-specific models, particularly in low-resource scenarios. AdapterHub includes all recent adapter architectures and can be found at https://AdapterHub.ml.
AdapterFusion: Non-Destructive Task Composition for Transfer Learning
May 01, 2020



Current approaches to solving classification tasks in NLP involve fine-tuning a pre-trained language model on a single target task. This paper focuses on sharing knowledge extracted not only from a pre-trained language model, but also from several source tasks in order to achieve better performance on the target task. Sequential fine-tuning and multi-task learning are two methods for sharing information, but suffer from problems such as catastrophic forgetting and difficulties in balancing multiple tasks. Additionally, multi-task learning requires simultaneous access to data used for each of the tasks, which does not allow for easy extensions to new tasks on the fly. We propose a new architecture as well as a two-stage learning algorithm that allows us to effectively share knowledge from multiple tasks while avoiding these crucial problems. In the first stage, we learn task specific parameters that encapsulate the knowledge from each task. We then combine these learned representations in a separate combination step, termed AdapterFusion. We show that by separating the two stages, i.e., knowledge extraction and knowledge combination, the classifier can effectively exploit the representations learned from multiple tasks in a non destructive manner. We empirically evaluate our transfer learning approach on 16 diverse NLP tasks, and show that it outperforms traditional strategies such as full fine-tuning of the model as well as multi-task learning.