 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Reasoning Models Are Private Thinkers
Feb 27, 2026AI agents powered by reasoning models require access to sensitive user data. However, their reasoning traces are difficult to control, which can result in the unintended leakage of private information to external parties. We propose training models to follow instructions not only in the final answer, but also in reasoning traces, potentially under different constraints. We hypothesize that improving their instruction following abilities in the reasoning traces can improve their privacy-preservation skills. To demonstrate this, we fine-tune models on a new instruction-following dataset with explicit restrictions on reasoning traces. We further introduce a generation strategy that decouples reasoning and answer generation using separate LoRA adapters. We evaluate our approach on six models from two model families, ranging from 1.7B to 14B parameters, across two instruction-following benchmarks and two privacy benchmarks. Our method yields substantial improvements, achieving gains of up to 20.9 points in instruction-following performance and up to 51.9 percentage points on privacy benchmarks. These improvements, however, can come at the cost of task utility, due to the trade-off between reasoning performance and instruction-following abilities. Overall, our results show that improving instruction-following behavior in reasoning models can significantly enhance privacy, suggesting a promising direction for the development of future privacy-aware agents. Our code and data are available at https://github.com/UKPLab/arxiv2026-controllable-reasoning-models
Leaky Thoughts: Large Reasoning Models Are Not Private Thinkers
Jun 18, 2025We study privacy leakage in the reasoning traces of large reasoning models used as personal agents. Unlike final outputs, reasoning traces are often assumed to be internal and safe. We challenge this assumption by showing that reasoning traces frequently contain sensitive user data, which can be extracted via prompt injections or accidentally leak into outputs. Through probing and agentic evaluations, we demonstrate that test-time compute approaches, particularly increased reasoning steps, amplify such leakage. While increasing the budget of those test-time compute approaches makes models more cautious in their final answers, it also leads them to reason more verbosely and leak more in their own thinking. This reveals a core tension: reasoning improves utility but enlarges the privacy attack surface. We argue that safety efforts must extend to the model's internal thinking, not just its outputs.
Scaling Up Membership Inference: When and How Attacks Succeed on Large Language Models
Oct 31, 2024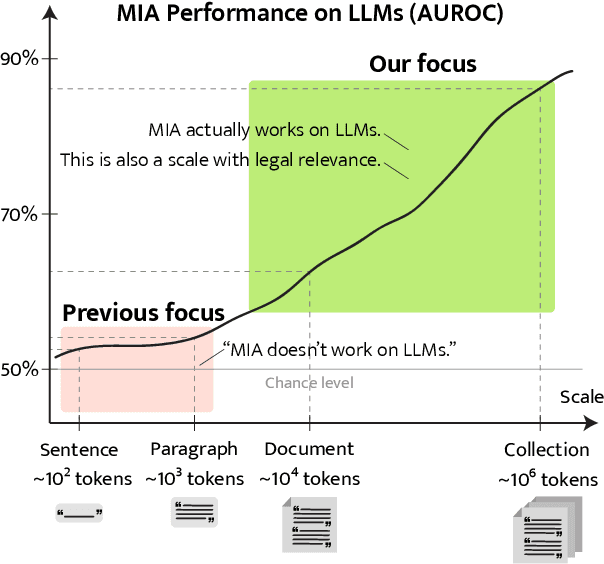
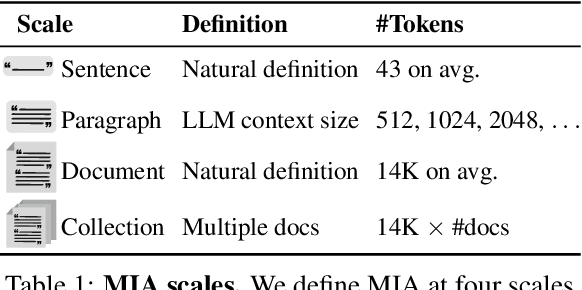
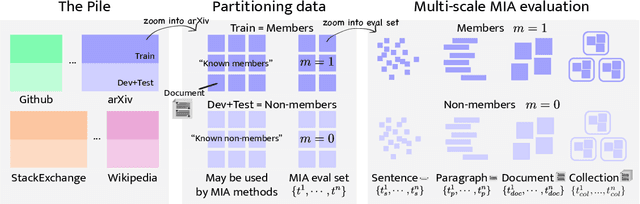
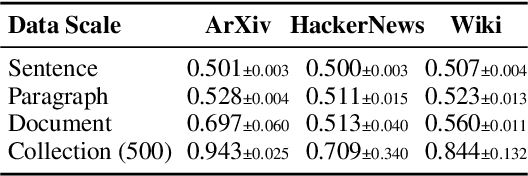
Membership inference attacks (MIA) attempt to verify the membership of a given data sample in the training set for a model. MIA has become relevant in recent years, following the rapid development of large language models (LLM). Many are concerned about the usage of copyrighted materials for training them and call for methods for detecting such usage. However, recent research has largely concluded that current MIA methods do not work on LLMs. Even when they seem to work, it is usually because of the ill-designed experimental setup where other shortcut features enable "cheating." In this work, we argue that MIA still works on LLMs, but only when multiple documents are presented for testing. We construct new benchmarks that measure the MIA performances at a continuous scale of data samples, from sentences (n-grams) to a collection of documents (multiple chunks of tokens). To validate the efficacy of current MIA approaches at greater scales, we adapt a recent work on Dataset Inference (DI) for the task of binary membership detection that aggregates paragraph-level MIA features to enable MIA at document and collection of documents level. This baseline achieves the first successful MIA on pre-trained and fine-tuned LLMs.
Fine-Tuning with Divergent Chains of Thought Boosts Reasoning Through Self-Correction in Language Models
Jul 03, 2024



Requiring a Large Language Model to generate intermediary reasoning steps has been shown to be an effective way of boosting performance. In fact, it has been found that instruction tuning on these intermediary reasoning steps improves model performance. In this work, we present a novel method of further improving performance by requiring models to compare multiple reasoning chains before generating a solution in a single inference step. We call this method Divergent CoT (DCoT). We find that instruction tuning on DCoT datasets boosts the performance of even smaller, and therefore more accessible, LLMs. Through a rigorous set of experiments spanning a wide range of tasks that require various reasoning types, we show that fine-tuning on DCoT consistently improves performance over the CoT baseline across model families and scales (1.3B to 70B). Through a combination of empirical and manual evaluation, we additionally show that these performance gains stem from models generating multiple divergent reasoning chains in a single inference step, indicative of the enabling of self-correction in language models. Our code and data are publicly available at https://github.com/UKPLab/arxiv2024-divergent-cot.
Code Prompting Elicits Conditional Reasoning Abilities in Text+Code LLMs
Jan 18, 2024



Reasoning is a fundamental component for achieving language understanding. Among the multiple types of reasoning, conditional reasoning, the ability to draw different conclusions depending on some condition, has been understudied in large language models (LLMs). Recent prompting methods, such as chain of thought, have significantly improved LLMs on reasoning tasks. Nevertheless, there is still little understanding of what triggers reasoning abilities in LLMs. We hypothesize that code prompts can trigger conditional reasoning in LLMs trained on text and code. We propose a chain of prompts that transforms a natural language problem into code and prompts the LLM with the generated code. Our experiments find that code prompts exhibit a performance boost between 2.6 and 7.7 points on GPT 3.5 across multiple datasets requiring conditional reasoning. We then conduct experiments to discover how code prompts elicit conditional reasoning abilities and through which features. We observe that prompts need to contain natural language text accompanied by high-quality code that closely represents the semantics of the instance text. Furthermore, we show that code prompts are more efficient, requiring fewer demonstrations, and that they trigger superior state tracking of variables or key entities.
Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023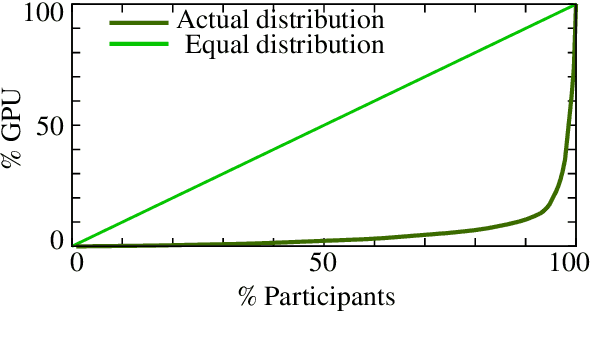

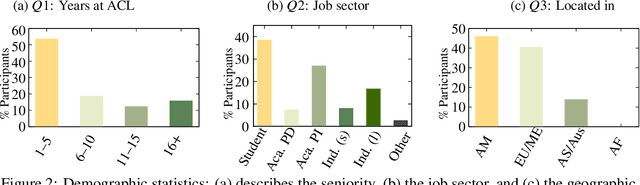
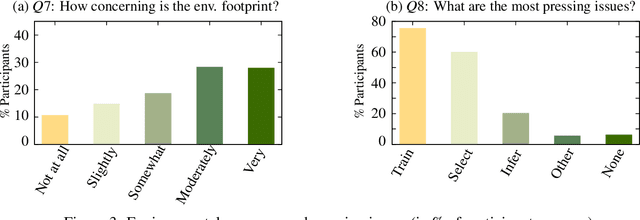
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
UKP-SQuARE: An Interactive Tool for Teaching Question Answering
Jun 02, 2023



The exponential growth of question answering (QA) has made it an indispensable topic in any Natural Language Processing (NLP) course. Additionally, the breadth of QA derived from this exponential growth makes it an ideal scenario for teaching related NLP topics such as information retrieval, explainability, and adversarial attacks among others. In this paper, we introduce UKP-SQuARE as a platform for QA education. This platform provides an interactive environment where students can run, compare, and analyze various QA models from different perspectives, such as general behavior, explainability, and robustness. Therefore, students can get a first-hand experience in different QA techniques during the class. Thanks to this, we propose a learner-centered approach for QA education in which students proactively learn theoretical concepts and acquire problem-solving skills through interactive exploration, experimentation, and practical assignments, rather than solely relying on traditional lectures. To evaluate the effectiveness of UKP-SQuARE in teaching scenarios, we adopted it in a postgraduate NLP course and surveyed the students after the course. Their positive feedback shows the platform's effectiveness in their course and invites a wider adoption.
UKP-SQuARE v3: A Platform for Multi-Agent QA Research
Mar 31, 2023



The continuous development of Question Answering (QA) datasets has drawn the research community's attention toward multi-domain models. A popular approach is to use multi-dataset models, which are models trained on multiple datasets to learn their regularities and prevent overfitting to a single dataset. However, with the proliferation of QA models in online repositories such as GitHub or Hugging Face, an alternative is becoming viable. Recent works have demonstrated that combining expert agents can yield large performance gains over multi-dataset models. To ease research in multi-agent models, we extend UKP-SQuARE, an online platform for QA research, to support three families of multi-agent systems: i) agent selection, ii) early-fusion of agents, and iii) late-fusion of agents. We conduct experiments to evaluate their inference speed and discuss the performance vs. speed trade-off compared to multi-dataset models. UKP-SQuARE is open-source and publicly available at http://square.ukp-lab.de.
UKP-SQuARE v2 Explainability and Adversarial Attacks for Trustworthy QA
Aug 23, 2022
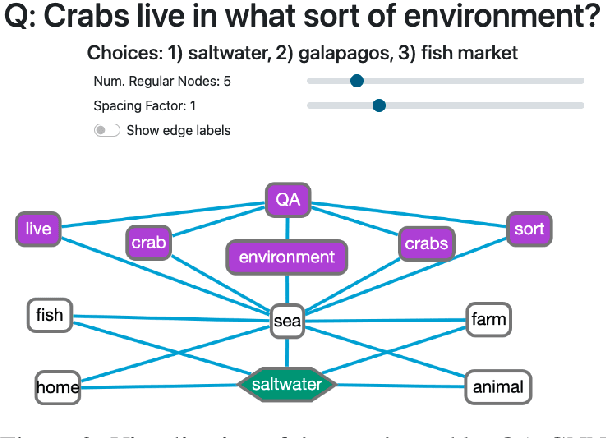
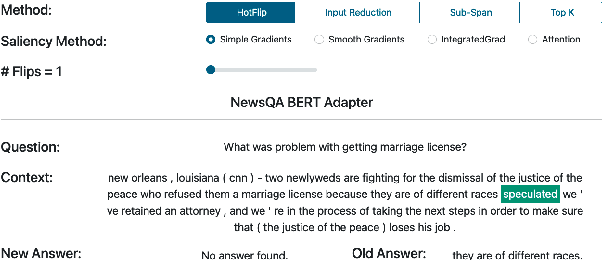

Question Answering (QA) systems are increasingly deployed in applications where they support real-world decisions. However, state-of-the-art models rely on deep neural networks, which are difficult to interpret by humans. Inherently interpretable models or post hoc explainability methods can help users to comprehend how a model arrives at its prediction and, if successful, increase their trust in the system. Furthermore, researchers can leverage these insights to develop new methods that are more accurate and less biased. In this paper, we introduce SQuARE v2, the new version of SQuARE, to provide an explainability infrastructure for comparing models based on methods such as saliency maps and graph-based explanations. While saliency maps are useful to inspect the importance of each input token for the model's prediction, graph-based explanations from external Knowledge Graphs enable the users to verify the reasoning behind the model prediction. In addition, we provide multiple adversarial attacks to compare the robustness of QA models. With these explainability methods and adversarial attacks, we aim to ease the research on trustworthy QA models. SQuARE is available on https://square.ukp-lab.de.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022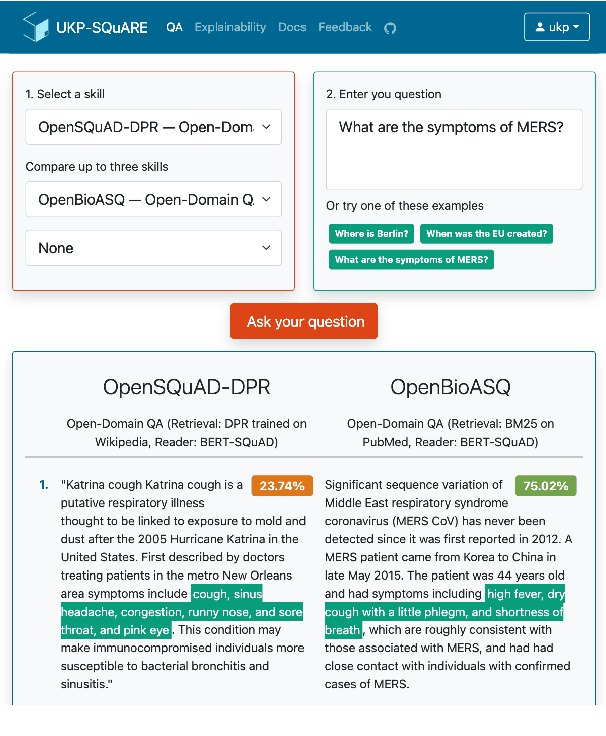

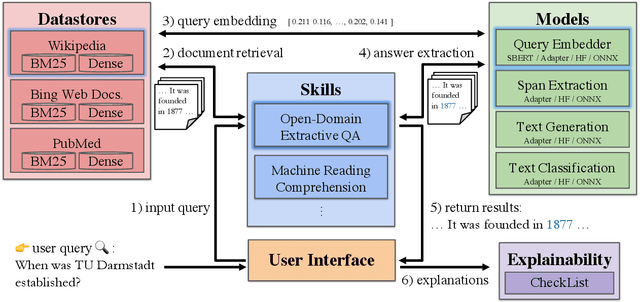
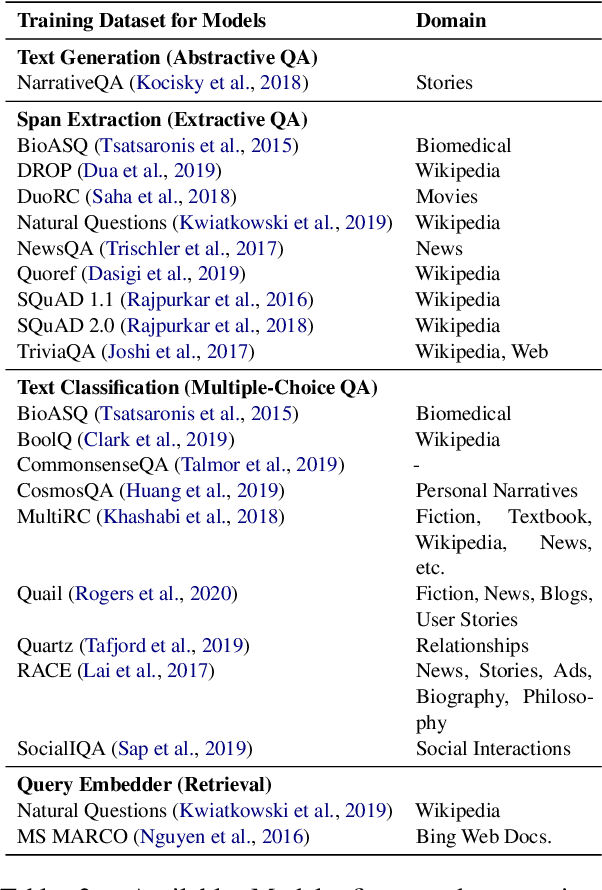
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.