 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJGU Mainz's Submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: MT and QA
Sep 26, 2025This paper presents the JGU Mainz submission to the WMT25 Shared Task on LLMs with Limited Resources for Slavic Languages: Machine Translation and Question Answering, focusing on Ukrainian, Upper Sorbian, and Lower Sorbian. For each language, we jointly fine-tune a Qwen2.5-3B-Instruct model for both tasks with parameter-efficient finetuning. Our pipeline integrates additional translation and multiple-choice question answering (QA) data. For Ukrainian QA, we further use retrieval-augmented generation. We also apply ensembling for QA in Upper and Lower Sorbian. Experiments show that our models outperform the baseline on both tasks.
UKP-SQuARE v2 Explainability and Adversarial Attacks for Trustworthy QA
Aug 23, 2022
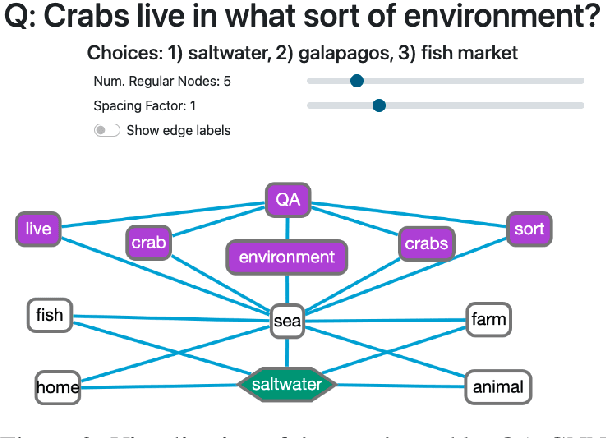
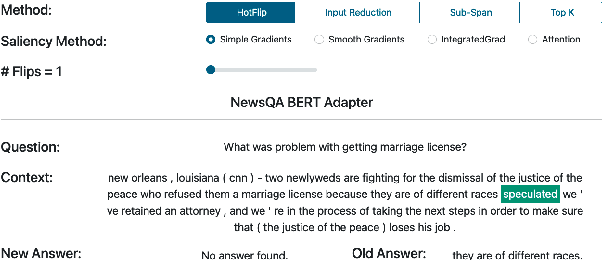

Question Answering (QA) systems are increasingly deployed in applications where they support real-world decisions. However, state-of-the-art models rely on deep neural networks, which are difficult to interpret by humans. Inherently interpretable models or post hoc explainability methods can help users to comprehend how a model arrives at its prediction and, if successful, increase their trust in the system. Furthermore, researchers can leverage these insights to develop new methods that are more accurate and less biased. In this paper, we introduce SQuARE v2, the new version of SQuARE, to provide an explainability infrastructure for comparing models based on methods such as saliency maps and graph-based explanations. While saliency maps are useful to inspect the importance of each input token for the model's prediction, graph-based explanations from external Knowledge Graphs enable the users to verify the reasoning behind the model prediction. In addition, we provide multiple adversarial attacks to compare the robustness of QA models. With these explainability methods and adversarial attacks, we aim to ease the research on trustworthy QA models. SQuARE is available on https://square.ukp-lab.de.