 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCoQA: Quality Assurance for Scientific Paper--Code Alignment
Jan 19, 2026We present SciCoQA, a dataset for detecting discrepancies between scientific publications and their codebases to ensure faithful implementations. We construct SciCoQA from GitHub issues and reproducibility papers, and to scale our dataset, we propose a synthetic data generation method for constructing paper-code discrepancies. We analyze the paper-code discrepancies in detail and propose discrepancy types and categories to better understand the occurring mismatches. In total, our dataset consists of 611 paper-code discrepancies (81 real, 530 synthetic), spanning diverse computational science disciplines, including AI, Physics, Quantitative Biology, and others. Our evaluation of 21 LLMs highlights the difficulty of SciCoQA, particularly for instances involving omitted paper details, long-context inputs, and data outside the models' pre-training corpus. The best performing model in our evaluation, GPT-5, can only detect 45.7\% of real-world paper-code discrepancies.
PeerQA: A Scientific Question Answering Dataset from Peer Reviews
Feb 19, 2025We present PeerQA, a real-world, scientific, document-level Question Answering (QA) dataset. PeerQA questions have been sourced from peer reviews, which contain questions that reviewers raised while thoroughly examining the scientific article. Answers have been annotated by the original authors of each paper. The dataset contains 579 QA pairs from 208 academic articles, with a majority from ML and NLP, as well as a subset of other scientific communities like Geoscience and Public Health. PeerQA supports three critical tasks for developing practical QA systems: Evidence retrieval, unanswerable question classification, and answer generation. We provide a detailed analysis of the collected dataset and conduct experiments establishing baseline systems for all three tasks. Our experiments and analyses reveal the need for decontextualization in document-level retrieval, where we find that even simple decontextualization approaches consistently improve retrieval performance across architectures. On answer generation, PeerQA serves as a challenging benchmark for long-context modeling, as the papers have an average size of 12k tokens. Our code and data is available at https://github.com/UKPLab/peerqa.
Scalable and Domain-General Abstractive Proposition Segmentation
Jun 28, 2024Segmenting text into fine-grained units of meaning is important to a wide range of NLP applications. The default approach of segmenting text into sentences is often insufficient, especially since sentences are usually complex enough to include multiple units of meaning that merit separate treatment in the downstream task. We focus on the task of abstractive proposition segmentation: transforming text into simple, self-contained, well-formed sentences. Several recent works have demonstrated the utility of proposition segmentation with few-shot prompted LLMs for downstream tasks such as retrieval-augmented grounding and fact verification. However, this approach does not scale to large amounts of text and may not always extract all the facts from the input text. In this paper, we first introduce evaluation metrics for the task to measure several dimensions of quality. We then propose a scalable, yet accurate, proposition segmentation model. We model proposition segmentation as a supervised task by training LLMs on existing annotated datasets and show that training yields significantly improved results. We further show that by using the fine-tuned LLMs as teachers for annotating large amounts of multi-domain synthetic distillation data, we can train smaller student models with results similar to the teacher LLMs. We then demonstrate that our technique leads to effective domain generalization, by annotating data in two domains outside the original training data and evaluating on them. Finally, as a key contribution of the paper, we share an easy-to-use API for NLP practitioners to use.
Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data
Apr 08, 2024Reinforcement Learning from Human Feedback (RLHF) is a popular method for aligning Language Models (LM) with human values and preferences. RLHF requires a large number of preference pairs as training data, which are often used in both the Supervised Fine-Tuning and Reward Model training, and therefore publicly available datasets are commonly used. In this work, we study to what extent a malicious actor can manipulate the LMs generations by poisoning the preferences, i.e., injecting poisonous preference pairs into these datasets and the RLHF training process. We propose strategies to build poisonous preference pairs and test their performance by poisoning two widely used preference datasets. Our results show that preference poisoning is highly effective: by injecting a small amount of poisonous data (1-5% of the original dataset), we can effectively manipulate the LM to generate a target entity in a target sentiment (positive or negative). The findings from our experiments also shed light on strategies to defend against the preference poisoning attack.
UKP-SQuARE v3: A Platform for Multi-Agent QA Research
Mar 31, 2023



The continuous development of Question Answering (QA) datasets has drawn the research community's attention toward multi-domain models. A popular approach is to use multi-dataset models, which are models trained on multiple datasets to learn their regularities and prevent overfitting to a single dataset. However, with the proliferation of QA models in online repositories such as GitHub or Hugging Face, an alternative is becoming viable. Recent works have demonstrated that combining expert agents can yield large performance gains over multi-dataset models. To ease research in multi-agent models, we extend UKP-SQuARE, an online platform for QA research, to support three families of multi-agent systems: i) agent selection, ii) early-fusion of agents, and iii) late-fusion of agents. We conduct experiments to evaluate their inference speed and discuss the performance vs. speed trade-off compared to multi-dataset models. UKP-SQuARE is open-source and publicly available at http://square.ukp-lab.de.
Incorporating Relevance Feedback for Information-Seeking Retrieval using Few-Shot Document Re-Ranking
Oct 19, 2022
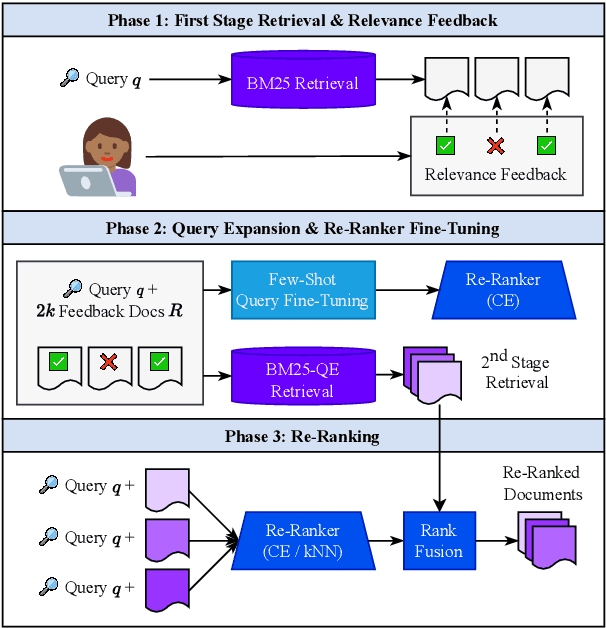
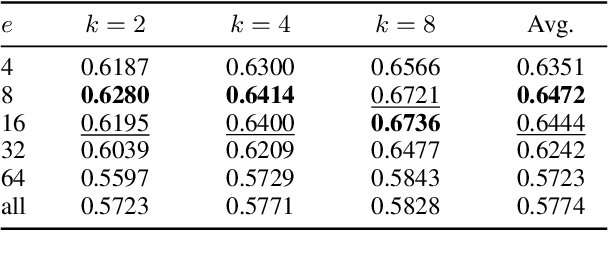
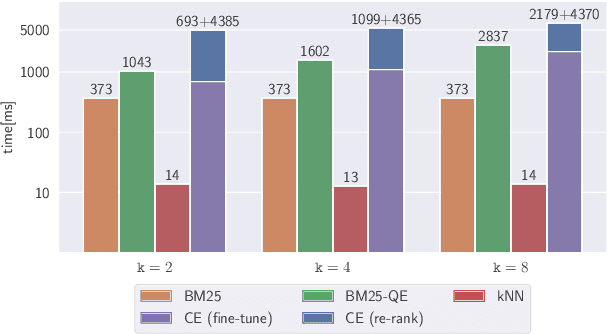
Pairing a lexical retriever with a neural re-ranking model has set state-of-the-art performance on large-scale information retrieval datasets. This pipeline covers scenarios like question answering or navigational queries, however, for information-seeking scenarios, users often provide information on whether a document is relevant to their query in form of clicks or explicit feedback. Therefore, in this work, we explore how relevance feedback can be directly integrated into neural re-ranking models by adopting few-shot and parameter-efficient learning techniques. Specifically, we introduce a kNN approach that re-ranks documents based on their similarity with the query and the documents the user considers relevant. Further, we explore Cross-Encoder models that we pre-train using meta-learning and subsequently fine-tune for each query, training only on the feedback documents. To evaluate our different integration strategies, we transform four existing information retrieval datasets into the relevance feedback scenario. Extensive experiments demonstrate that integrating relevance feedback directly in neural re-ranking models improves their performance, and fusing lexical ranking with our best performing neural re-ranker outperforms all other methods by 5.2 nDCG@20.
UKP-SQuARE v2 Explainability and Adversarial Attacks for Trustworthy QA
Aug 23, 2022
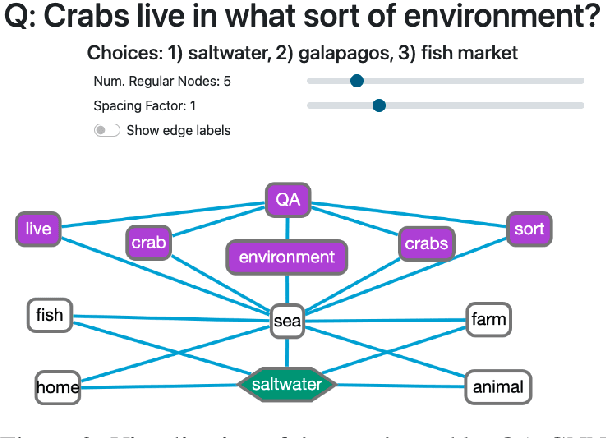
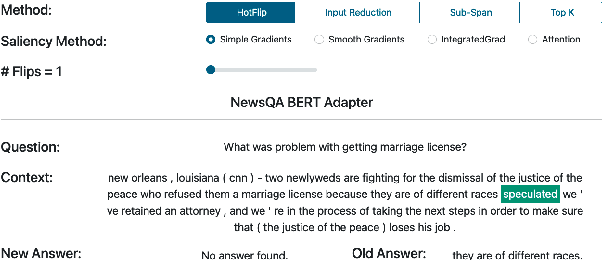

Question Answering (QA) systems are increasingly deployed in applications where they support real-world decisions. However, state-of-the-art models rely on deep neural networks, which are difficult to interpret by humans. Inherently interpretable models or post hoc explainability methods can help users to comprehend how a model arrives at its prediction and, if successful, increase their trust in the system. Furthermore, researchers can leverage these insights to develop new methods that are more accurate and less biased. In this paper, we introduce SQuARE v2, the new version of SQuARE, to provide an explainability infrastructure for comparing models based on methods such as saliency maps and graph-based explanations. While saliency maps are useful to inspect the importance of each input token for the model's prediction, graph-based explanations from external Knowledge Graphs enable the users to verify the reasoning behind the model prediction. In addition, we provide multiple adversarial attacks to compare the robustness of QA models. With these explainability methods and adversarial attacks, we aim to ease the research on trustworthy QA models. SQuARE is available on https://square.ukp-lab.de.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022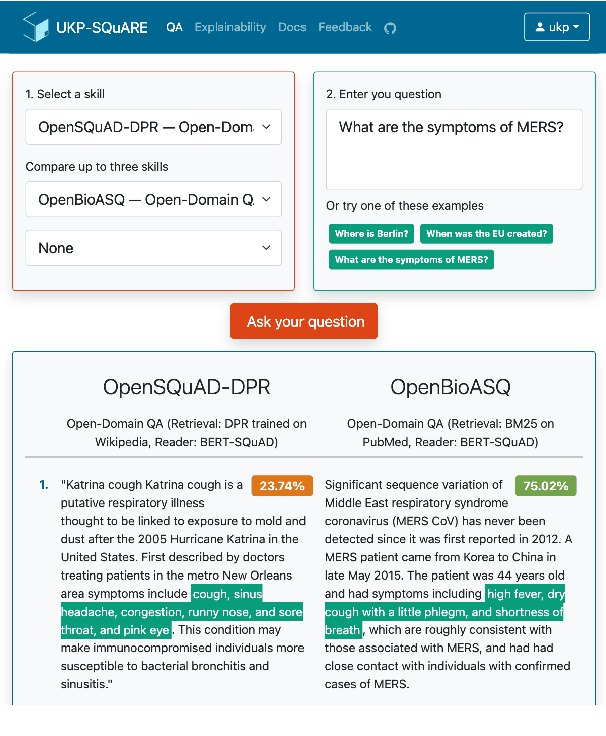

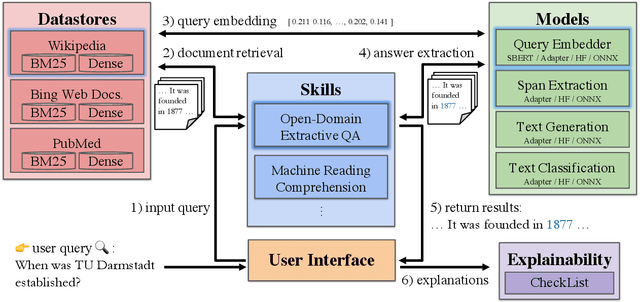
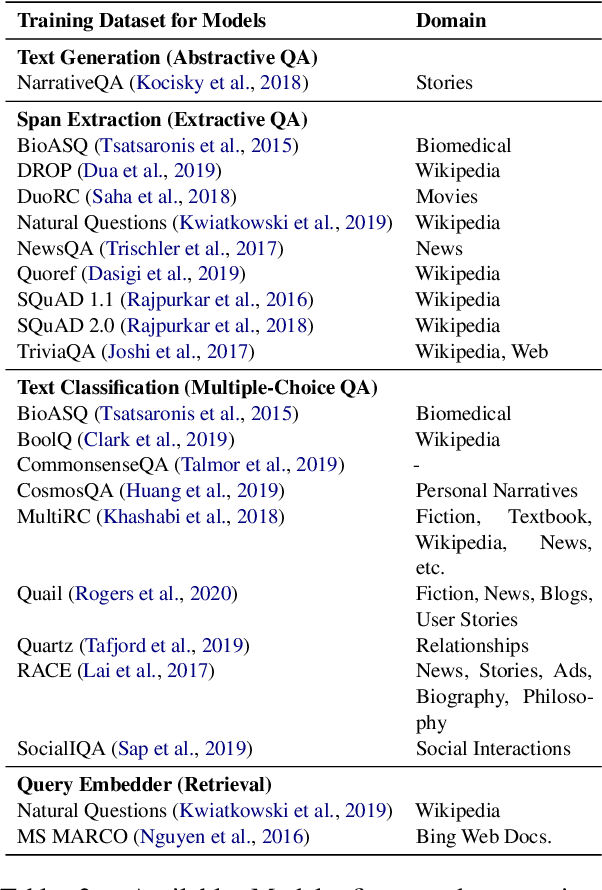
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
On the Realization of Compositionality in Neural Networks
Jun 06, 2019
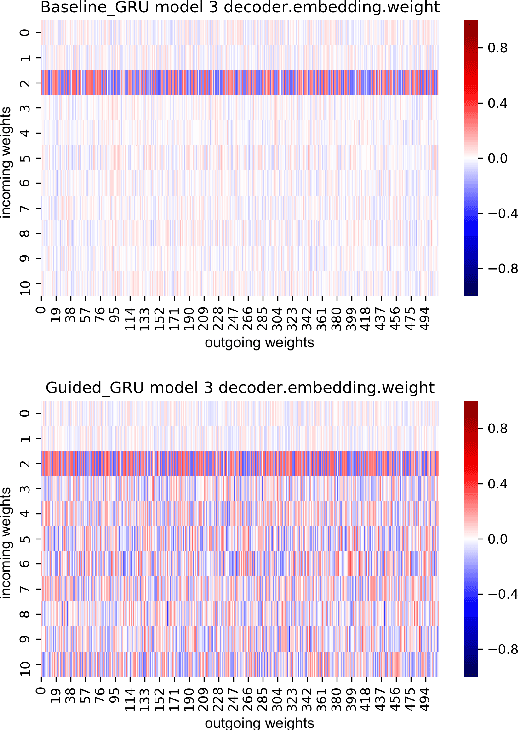
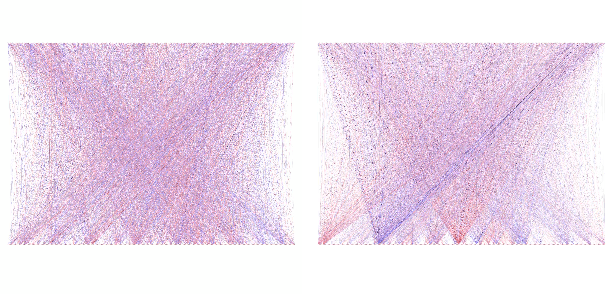
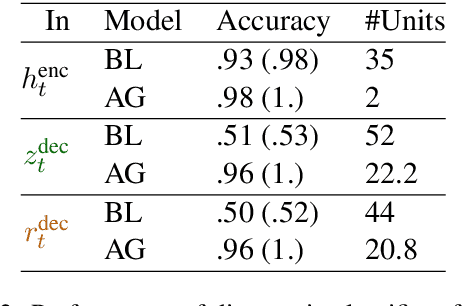
We present a detailed comparison of two types of sequence to sequence models trained to conduct a compositional task. The models are architecturally identical at inference time, but differ in the way that they are trained: our baseline model is trained with a task-success signal only, while the other model receives additional supervision on its attention mechanism (Attentive Guidance), which has shown to be an effective method for encouraging more compositional solutions (Hupkes et al.,2019). We first confirm that the models with attentive guidance indeed infer more compositional solutions than the baseline, by training them on the lookup table task presented by Li\v{s}ka et al. (2019). We then do an in-depth analysis of the structural differences between the two model types, focusing in particular on the organisation of the parameter space and the hidden layer activations and find noticeable differences in both these aspects. Guided networks focus more on the components of the input rather than the sequence as a whole and develop small functional groups of neurons with specific purposes that use their gates more selectively. Results from parameter heat maps, component swapping and graph analysis also indicate that guided networks exhibit a more modular structure with a small number of specialized, strongly connected neurons.
The PhotoBook Dataset: Building Common Ground through Visually-Grounded Dialogue
Jun 04, 2019
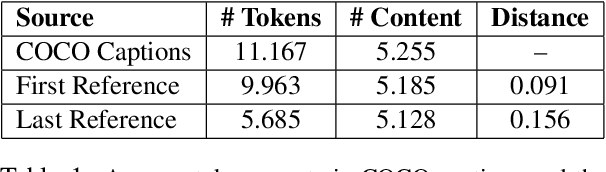
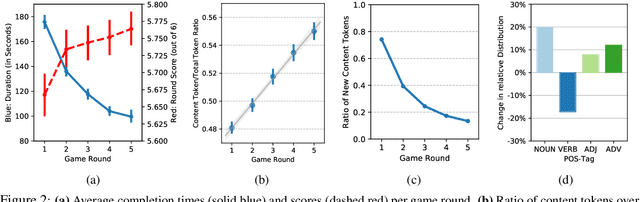
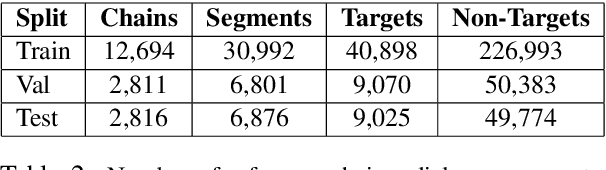
This paper introduces the PhotoBook dataset, a large-scale collection of visually-grounded, task-oriented dialogues in English designed to investigate shared dialogue history accumulating during conversation. Taking inspiration from seminal work on dialogue analysis, we propose a data-collection task formulated as a collaborative game prompting two online participants to refer to images utilising both their visual context as well as previously established referring expressions. We provide a detailed description of the task setup and a thorough analysis of the 2,500 dialogues collected. To further illustrate the novel features of the dataset, we propose a baseline model for reference resolution which uses a simple method to take into account shared information accumulated in a reference chain. Our results show that this information is particularly important to resolve later descriptions and underline the need to develop more sophisticated models of common ground in dialogue interaction.