 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning to See, Ask, and GuessWhat
Sep 10, 2018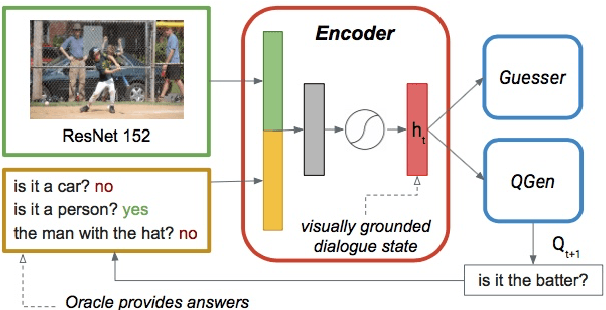
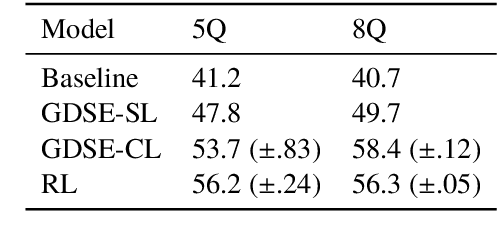
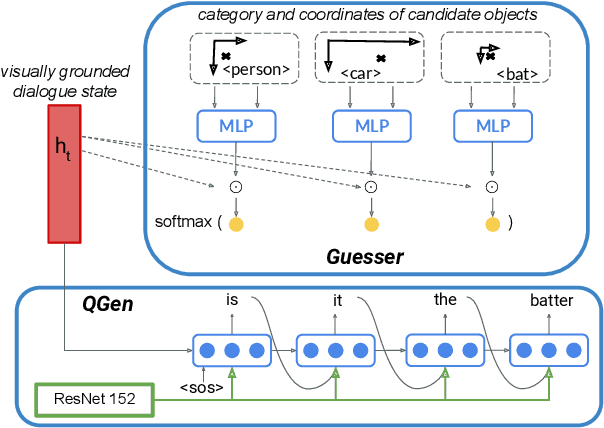
We are interested in understanding how the ability to ground language in vision interacts with other abilities at play in dialogue, such as asking a series of questions to obtain the necessary information to perform a certain task. With this aim, we develop a Questioner agent in the context of the GuessWhat?! game. Our model exploits a neural network architecture to build a continuous representation of the dialogue state that integrates information from the visual and linguistic modalities and conditions future action. To play the GuessWhat?! game, the Questioner agent has to be able to do both, ask questions and guess a target object in the visual environment. In our architecture, these two capabilities are considered jointly as a supervised multi-task learning problem, to which cooperative learning can be further applied. We show that the introduction of our new architecture combined with these learning regimes yields an increase of 19.5% in task success accuracy with respect to a baseline model that treats submodules independently. With this increase, we reach an accuracy comparable to state-of-the-art models that use reinforcement learning, with the advantage that our architecture is entirely differentiable and thus easier to train. This suggests that combining our approach with reinforcement learning could lead to further improvements in the future. Finally, we present a range of analyses that examine the quality of the dialogues and shed light on the internal dynamics of the model.
Ask No More: Deciding when to guess in referential visual dialogue
Jun 12, 2018

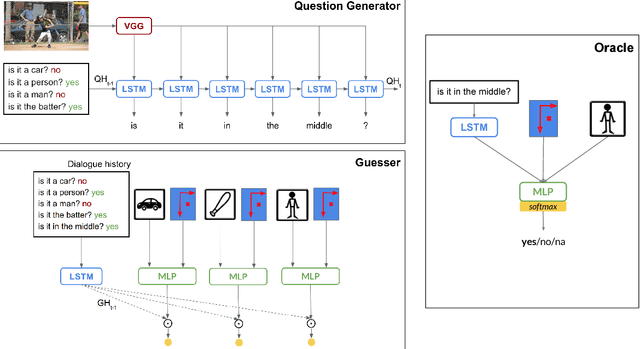

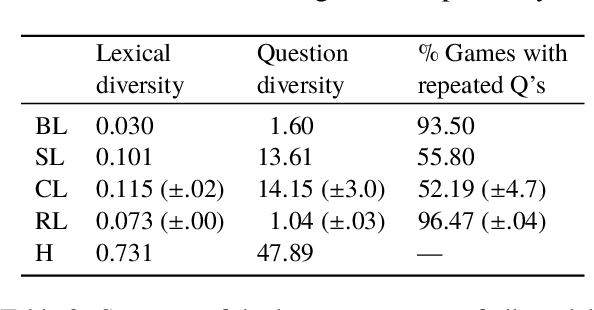
Our goal is to explore how the abilities brought in by a dialogue manager can be included in end-to-end visually grounded conversational agents. We make initial steps towards this general goal by augmenting a task-oriented visual dialogue model with a decision-making component that decides whether to ask a follow-up question to identify a target referent in an image, or to stop the conversation to make a guess. Our analyses show that adding a decision making component produces dialogues that are less repetitive and that include fewer unnecessary questions, thus potentially leading to more efficient and less unnatural interactions.