 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Word Sense Representations via Definition Generation: The Case of Semantic Change Analysis
May 19, 2023



We propose using automatically generated natural language definitions of contextualised word usages as interpretable word and word sense representations. Given a collection of usage examples for a target word, and the corresponding data-driven usage clusters (i.e., word senses), a definition is generated for each usage with a specialised Flan-T5 language model, and the most prototypical definition in a usage cluster is chosen as the sense label. We demonstrate how the resulting sense labels can make existing approaches to semantic change analysis more interpretable, and how they can allow users -- historical linguists, lexicographers, or social scientists -- to explore and intuitively explain diachronic trajectories of word meaning. Semantic change analysis is only one of many possible applications of the `definitions as representations' paradigm. Beyond being human-readable, contextualised definitions also outperform token or usage sentence embeddings in word-in-context semantic similarity judgements, making them a new promising type of lexical representation for NLP.
Stop Measuring Calibration When Humans Disagree
Oct 28, 2022

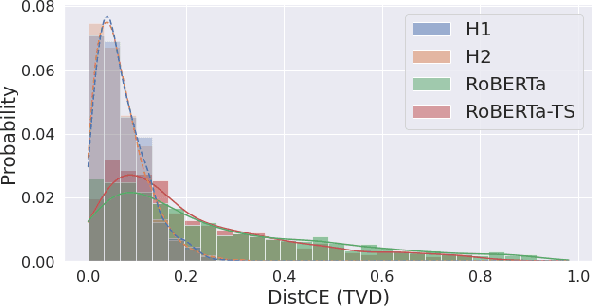

Calibration is a popular framework to evaluate whether a classifier knows when it does not know - i.e., its predictive probabilities are a good indication of how likely a prediction is to be correct. Correctness is commonly estimated against the human majority class. Recently, calibration to human majority has been measured on tasks where humans inherently disagree about which class applies. We show that measuring calibration to human majority given inherent disagreements is theoretically problematic, demonstrate this empirically on the ChaosNLI dataset, and derive several instance-level measures of calibration that capture key statistical properties of human judgements - class frequency, ranking and entropy.
Ask No More: Deciding when to guess in referential visual dialogue
Jun 12, 2018

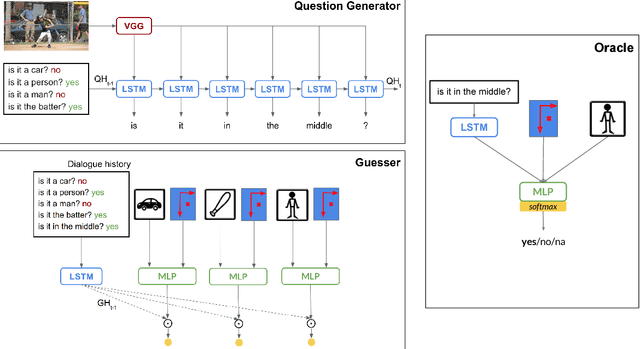

Our goal is to explore how the abilities brought in by a dialogue manager can be included in end-to-end visually grounded conversational agents. We make initial steps towards this general goal by augmenting a task-oriented visual dialogue model with a decision-making component that decides whether to ask a follow-up question to identify a target referent in an image, or to stop the conversation to make a guess. Our analyses show that adding a decision making component produces dialogues that are less repetitive and that include fewer unnecessary questions, thus potentially leading to more efficient and less unnatural interactions.