 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Doubt: Zero-shot Cross-Lingual Confidence Estimation for Language Models
May 29, 2026Confidence estimation (CE), i.e. quantifying the reliability of a model's prediction, has attracted great interest in the context of large language models (LLMs). However, most studies focus on English, ignoring the multilingual reality of LLM usage, while many CE methods degrade or require retraining across languages. To address this gap, we investigate whether multilingual LLMs encode shared, language-transferable confidence features. We use a lightweight linear probe that predicts answer correctness directly from intermediate representations. Trained monolingually, the probe generalizes zero-shot to unseen, typologically diverse languages without target-language supervision. Learned layer weights and multiple ablations reveal that confidence features concentrate in middle layers across languages, suggesting a shared confidence subspace. While zero-shot cross-lingual performance depends on similarity to the source language, the probe provides a strong baseline without any retraining and compares favorably to other popular confidence estimation methods.
Probing for Knowledge Attribution in Large Language Models
Feb 26, 2026Large language models (LLMs) often generate fluent but unfounded claims, or hallucinations, which fall into two types: (i) faithfulness violations - misusing user context - and (ii) factuality violations - errors from internal knowledge. Proper mitigation depends on knowing whether a model's answer is based on the prompt or its internal weights. This work focuses on the problem of contributive attribution: identifying the dominant knowledge source behind each output. We show that a probe, a simple linear classifier trained on model hidden representations, can reliably predict contributive attribution. For its training, we introduce AttriWiki, a self-supervised data pipeline that prompts models to recall withheld entities from memory or read them from context, generating labelled examples automatically. Probes trained on AttriWiki data reveal a strong attribution signal, achieving up to 0.96 Macro-F1 on Llama-3.1-8B, Mistral-7B, and Qwen-7B, transferring to out-of-domain benchmarks (SQuAD, WebQuestions) with 0.94-0.99 Macro-F1 without retraining. Attribution mismatches raise error rates by up to 70%, demonstrating a direct link between knowledge source confusion and unfaithful answers. Yet, models may still respond incorrectly even when attribution is correct, highlighting the need for broader detection frameworks.
Calibration Is Not Enough: Evaluating Confidence Estimation Under Language Variations
Jan 12, 2026Confidence estimation (CE) indicates how reliable the answers of large language models (LLMs) are, and can impact user trust and decision-making. Existing work evaluates CE methods almost exclusively through calibration, examining whether stated confidence aligns with accuracy, or discrimination, whether confidence is ranked higher for correct predictions than incorrect ones. However, these facets ignore pitfalls of CE in the context of LLMs and language variation: confidence estimates should remain consistent under semantically equivalent prompt or answer variations, and should change when the answer meaning differs. Therefore, we present a comprehensive evaluation framework for CE that measures their confidence quality on three new aspects: robustness of confidence against prompt perturbations, stability across semantic equivalent answers, and sensitivity to semantically different answers. In our work, we demonstrate that common CE methods for LLMs often fail on these metrics: methods that achieve good performance on calibration or discrimination are not robust to prompt variations or are not sensitive to answer changes. Overall, our framework reveals limitations of existing CE evaluations relevant for real-world LLM use cases and provides practical guidance for selecting and designing more reliable CE methods.
On Uncertainty In Natural Language Processing
Oct 04, 2024The last decade in deep learning has brought on increasingly capable systems that are deployed on a wide variety of applications. In natural language processing, the field has been transformed by a number of breakthroughs including large language models, which are used in increasingly many user-facing applications. In order to reap the benefits of this technology and reduce potential harms, it is important to quantify the reliability of model predictions and the uncertainties that shroud their development. This thesis studies how uncertainty in natural language processing can be characterized from a linguistic, statistical and neural perspective, and how it can be reduced and quantified through the design of the experimental pipeline. We further explore uncertainty quantification in modeling by theoretically and empirically investigating the effect of inductive model biases in text classification tasks. The corresponding experiments include data for three different languages (Danish, English and Finnish) and tasks as well as a large set of different uncertainty quantification approaches. Additionally, we propose a method for calibrated sampling in natural language generation based on non-exchangeable conformal prediction, which provides tighter token sets with better coverage of the actual continuation. Lastly, we develop an approach to quantify confidence in large black-box language models using auxiliary predictors, where the confidence is predicted from the input to and generated output text of the target model alone.
Calibrating Large Language Models Using Their Generations Only
Mar 09, 2024As large language models (LLMs) are increasingly deployed in user-facing applications, building trust and maintaining safety by accurately quantifying a model's confidence in its prediction becomes even more important. However, finding effective ways to calibrate LLMs - especially when the only interface to the models is their generated text - remains a challenge. We propose APRICOT (auxiliary prediction of confidence targets): A method to set confidence targets and train an additional model that predicts an LLM's confidence based on its textual input and output alone. This approach has several advantages: It is conceptually simple, does not require access to the target model beyond its output, does not interfere with the language generation, and has a multitude of potential usages, for instance by verbalizing the predicted confidence or adjusting the given answer based on the confidence. We show how our approach performs competitively in terms of calibration error for white-box and black-box LLMs on closed-book question-answering to detect incorrect LLM answers.
TRAP: Targeted Random Adversarial Prompt Honeypot for Black-Box Identification
Feb 20, 2024



Large Language Model (LLM) services and models often come with legal rules on who can use them and how they must use them. Assessing the compliance of the released LLMs is crucial, as these rules protect the interests of the LLM contributor and prevent misuse. In this context, we describe the novel problem of Black-box Identity Verification (BBIV). The goal is to determine whether a third-party application uses a certain LLM through its chat function. We propose a method called Targeted Random Adversarial Prompt (TRAP) that identifies the specific LLM in use. We repurpose adversarial suffixes, originally proposed for jailbreaking, to get a pre-defined answer from the target LLM, while other models give random answers. TRAP detects the target LLMs with over 95% true positive rate at under 0.2% false positive rate even after a single interaction. TRAP remains effective even if the LLM has minor changes that do not significantly alter the original function.
Non-Exchangeable Conformal Language Generation with Nearest Neighbors
Feb 01, 2024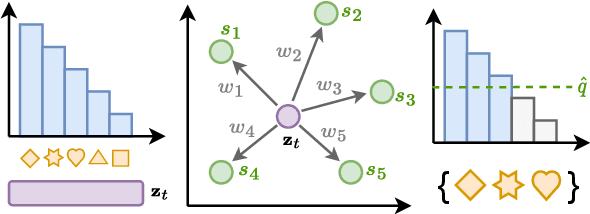
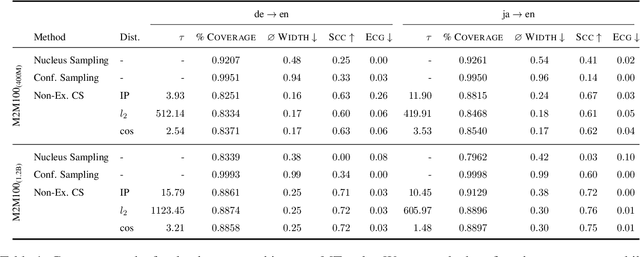
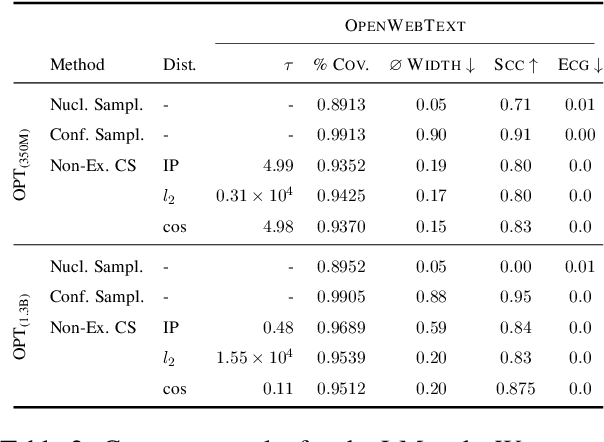
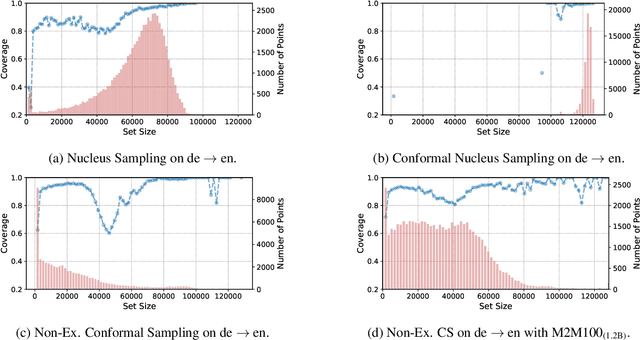
Quantifying uncertainty in automatically generated text is important for letting humans check potential hallucinations and making systems more reliable. Conformal prediction is an attractive framework to provide predictions imbued with statistical guarantees, however, its application to text generation is challenging since any i.i.d. assumptions are not realistic. In this paper, we bridge this gap by leveraging recent results on non-exchangeable conformal prediction, which still ensures bounds on coverage. The result, non-exchangeable conformal nucleus sampling, is a novel extension of the conformal prediction framework to generation based on nearest neighbors. Our method can be used post-hoc for an arbitrary model without extra training and supplies token-level, calibrated prediction sets equipped with statistical guarantees. Experiments in machine translation and language modeling show encouraging results in generation quality. By also producing tighter prediction sets with good coverage, we thus give a more theoretically principled way to perform sampling with conformal guarantees.
Bootstrapping LLM-based Task-Oriented Dialogue Agents via Self-Talk
Jan 10, 2024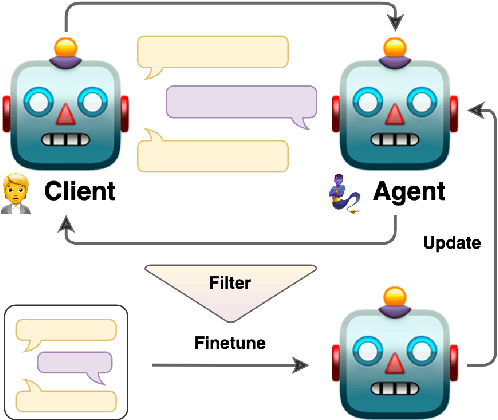

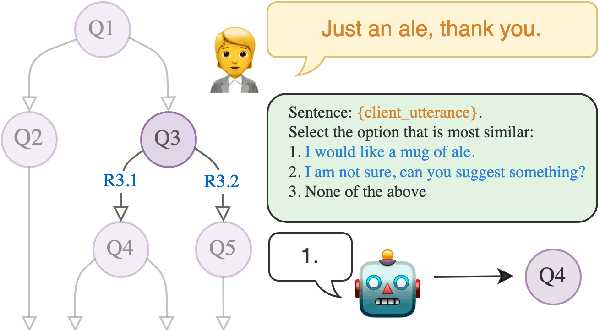

Large language models (LLMs) are powerful dialogue agents, but specializing them towards fulfilling a specific function can be challenging. Instructing tuning, i.e. tuning models on instruction and sample responses generated by humans (Ouyang et al., 2022), has proven as an effective method to do so, yet requires a number of data samples that a) might not be available or b) costly to generate. Furthermore, this cost increases when the goal is to make the LLM follow a specific workflow within a dialogue instead of single instructions. Inspired by the self-play technique in reinforcement learning and the use of LLMs to simulate human agents, we propose a more effective method for data collection through LLMs engaging in a conversation in various roles. This approach generates a training data via "self-talk" of LLMs that can be refined and utilized for supervised fine-tuning. We introduce an automated way to measure the (partial) success of a dialogue. This metric is used to filter the generated conversational data that is fed back in LLM for training. Based on our automated and human evaluations of conversation quality, we demonstrate that such self-talk data improves results. In addition, we examine the various characteristics that showcase the quality of generated dialogues and how they can be connected to their potential utility as training data.
Non-Exchangeable Conformal Risk Control
Oct 02, 2023Split conformal prediction has recently sparked great interest due to its ability to provide formally guaranteed uncertainty sets or intervals for predictions made by black-box neural models, ensuring a predefined probability of containing the actual ground truth. While the original formulation assumes data exchangeability, some extensions handle non-exchangeable data, which is often the case in many real-world scenarios. In parallel, some progress has been made in conformal methods that provide statistical guarantees for a broader range of objectives, such as bounding the best F1-score or minimizing the false negative rate in expectation. In this paper, we leverage and extend these two lines of work by proposing non-exchangeable conformal risk control, which allows controlling the expected value of any monotone loss function when the data is not exchangeable. Our framework is flexible, makes very few assumptions, and allows weighting the data based on its statistical similarity with the test examples; a careful choice of weights may result on tighter bounds, making our framework useful in the presence of change points, time series, or other forms of distribution drift. Experiments with both synthetic and real world data show the usefulness of our method.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.