 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Exchangeable Conformal Language Generation with Nearest Neighbors
Paper and Code
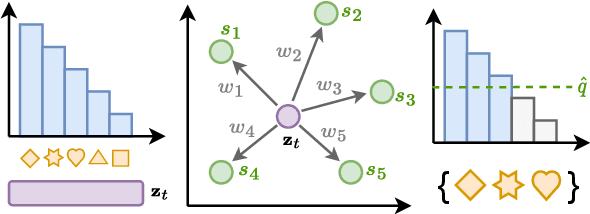
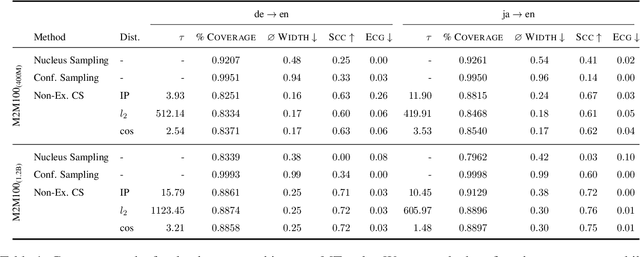
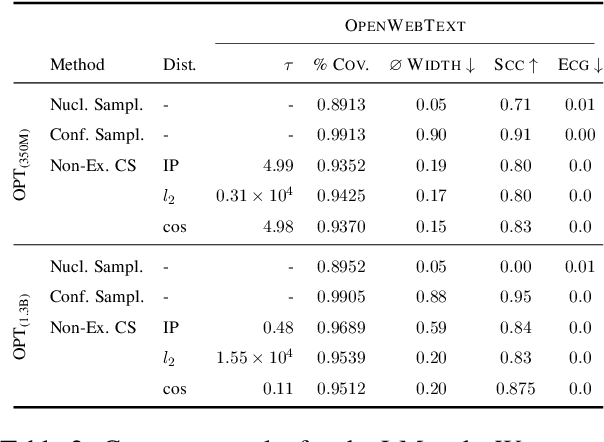
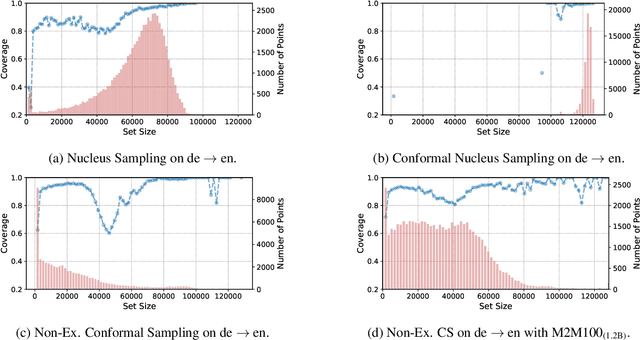
Quantifying uncertainty in automatically generated text is important for letting humans check potential hallucinations and making systems more reliable. Conformal prediction is an attractive framework to provide predictions imbued with statistical guarantees, however, its application to text generation is challenging since any i.i.d. assumptions are not realistic. In this paper, we bridge this gap by leveraging recent results on non-exchangeable conformal prediction, which still ensures bounds on coverage. The result, non-exchangeable conformal nucleus sampling, is a novel extension of the conformal prediction framework to generation based on nearest neighbors. Our method can be used post-hoc for an arbitrary model without extra training and supplies token-level, calibrated prediction sets equipped with statistical guarantees. Experiments in machine translation and language modeling show encouraging results in generation quality. By also producing tighter prediction sets with good coverage, we thus give a more theoretically principled way to perform sampling with conformal guarantees.