 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASEval: Extending Multi-Agent Evaluation from Models to Systems
Mar 09, 2026The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks (smolagents, LangGraph, AutoGen, CAMEL, LlamaIndex, i.a.). Yet existing benchmarks are model-centric: they fix the agentic setup and do not compare other system components. We argue that implementation decisions substantially impact performance, including choices such as topology, orchestration logic, and error handling. MASEval addresses this evaluation gap with a framework-agnostic library that treats the entire system as the unit of analysis. Through a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks, we find that framework choice matters as much as model choice. MASEval allows researchers to explore all components of agentic systems, opening new avenues for principled system design, and practitioners to identify the best implementation for their use case. MASEval is available under the MIT licence https://github.com/parameterlab/MASEval.
Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Models
Jan 21, 2026We identify a novel phenomenon in language models: benign fine-tuning of frontier models can lead to privacy collapse. We find that diverse, subtle patterns in training data can degrade contextual privacy, including optimisation for helpfulness, exposure to user information, emotional and subjective dialogue, and debugging code printing internal variables, among others. Fine-tuned models lose their ability to reason about contextual privacy norms, share information inappropriately with tools, and violate memory boundaries across contexts. Privacy collapse is a ``silent failure'' because models maintain high performance on standard safety and utility benchmarks whilst exhibiting severe privacy vulnerabilities. Our experiments show evidence of privacy collapse across six models (closed and open weight), five fine-tuning datasets (real-world and controlled data), and two task categories (agentic and memory-based). Our mechanistic analysis reveals that privacy representations are uniquely fragile to fine-tuning, compared to task-relevant features which are preserved. Our results reveal a critical gap in current safety evaluations, in particular for the deployment of specialised agents.
Dr.LLM: Dynamic Layer Routing in LLMs
Oct 14, 2025Large Language Models (LLMs) process every token through all layers of a transformer stack, causing wasted computation on simple queries and insufficient flexibility for harder ones that need deeper reasoning. Adaptive-depth methods can improve efficiency, but prior approaches rely on costly inference-time search, architectural changes, or large-scale retraining, and in practice often degrade accuracy despite efficiency gains. We introduce Dr.LLM, Dynamic routing of Layers for LLMs, a retrofittable framework that equips pretrained models with lightweight per-layer routers deciding to skip, execute, or repeat a block. Routers are trained with explicit supervision: using Monte Carlo Tree Search (MCTS), we derive high-quality layer configurations that preserve or improve accuracy under a compute budget. Our design, windowed pooling for stable routing, focal loss with class balancing, and bottleneck MLP routers, ensures robustness under class imbalance and long sequences. On ARC (logic) and DART (math), Dr.LLM improves accuracy by up to +3.4%p while saving 5 layers per example on average. Routers generalize to out-of-domain tasks (MMLU, GSM8k, AIME, TruthfulQA, SQuADv2, GPQA, PIQA, AGIEval) with only 0.85% accuracy drop while retaining efficiency, and outperform prior routing methods by up to +7.7%p. Overall, Dr.LLM shows that explicitly supervised routers retrofit frozen LLMs for budget-aware, accuracy-driven inference without altering base weights.
DISCO: Diversifying Sample Condensation for Efficient Model Evaluation
Oct 09, 2025Evaluating modern machine learning models has become prohibitively expensive. Benchmarks such as LMMs-Eval and HELM demand thousands of GPU hours per model. Costly evaluation reduces inclusivity, slows the cycle of innovation, and worsens environmental impact. The typical approach follows two steps. First, select an anchor subset of data. Second, train a mapping from the accuracy on this subset to the final test result. The drawback is that anchor selection depends on clustering, which can be complex and sensitive to design choices. We argue that promoting diversity among samples is not essential; what matters is to select samples that $\textit{maximise diversity in model responses}$. Our method, $\textbf{Diversifying Sample Condensation (DISCO)}$, selects the top-k samples with the greatest model disagreements. This uses greedy, sample-wise statistics rather than global clustering. The approach is conceptually simpler. From a theoretical view, inter-model disagreement provides an information-theoretically optimal rule for such greedy selection. $\textbf{DISCO}$ shows empirical gains over prior methods, achieving state-of-the-art results in performance prediction across MMLU, Hellaswag, Winogrande, and ARC. Code is available here: https://github.com/arubique/disco-public.
Leaky Thoughts: Large Reasoning Models Are Not Private Thinkers
Jun 18, 2025We study privacy leakage in the reasoning traces of large reasoning models used as personal agents. Unlike final outputs, reasoning traces are often assumed to be internal and safe. We challenge this assumption by showing that reasoning traces frequently contain sensitive user data, which can be extracted via prompt injections or accidentally leak into outputs. Through probing and agentic evaluations, we demonstrate that test-time compute approaches, particularly increased reasoning steps, amplify such leakage. While increasing the budget of those test-time compute approaches makes models more cautious in their final answers, it also leads them to reason more verbosely and leak more in their own thinking. This reveals a core tension: reasoning improves utility but enlarges the privacy attack surface. We argue that safety efforts must extend to the model's internal thinking, not just its outputs.
Social Science Is Necessary for Operationalizing Socially Responsible Foundation Models
Dec 20, 2024With the rise of foundation models, there is growing concern about their potential social impacts. Social science has a long history of studying the social impacts of transformative technologies in terms of pre-existing systems of power and how these systems are disrupted or reinforced by new technologies. In this position paper, we build on prior work studying the social impacts of earlier technologies to propose a conceptual framework studying foundation models as sociotechnical systems, incorporating social science expertise to better understand how these models affect systems of power, anticipate the impacts of deploying these models in various applications, and study the effectiveness of technical interventions intended to mitigate social harms. We advocate for an interdisciplinary and collaborative research paradigm between AI and social science across all stages of foundation model research and development to promote socially responsible research practices and use cases, and outline several strategies to facilitate such research.
Scaling Up Membership Inference: When and How Attacks Succeed on Large Language Models
Oct 31, 2024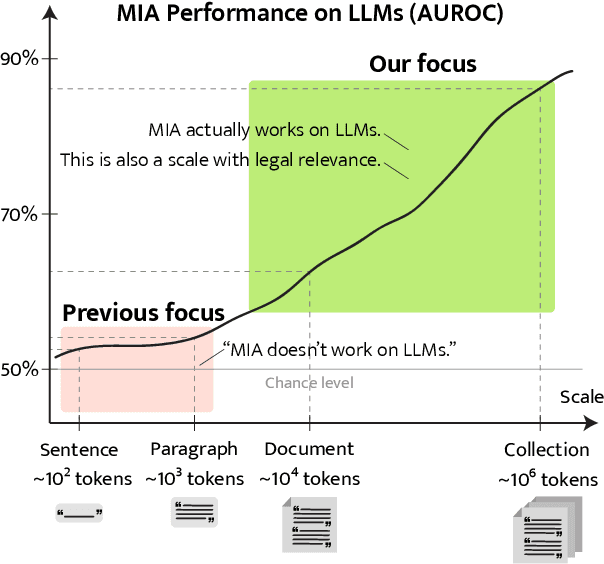
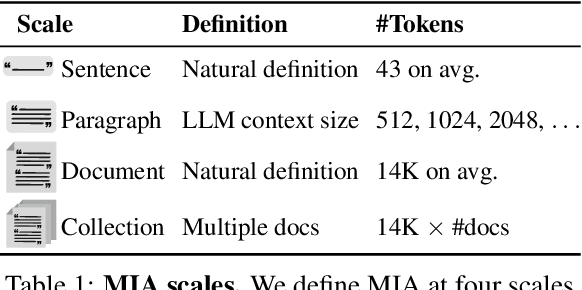
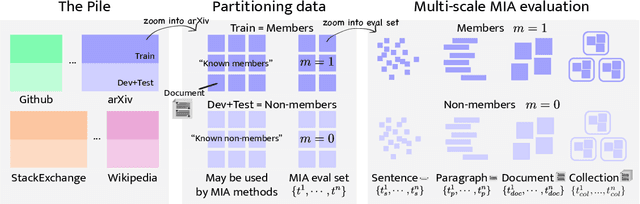
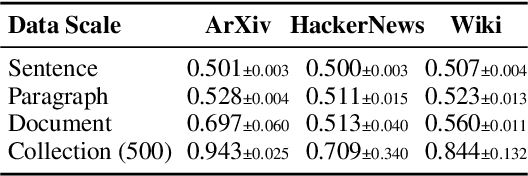
Membership inference attacks (MIA) attempt to verify the membership of a given data sample in the training set for a model. MIA has become relevant in recent years, following the rapid development of large language models (LLM). Many are concerned about the usage of copyrighted materials for training them and call for methods for detecting such usage. However, recent research has largely concluded that current MIA methods do not work on LLMs. Even when they seem to work, it is usually because of the ill-designed experimental setup where other shortcut features enable "cheating." In this work, we argue that MIA still works on LLMs, but only when multiple documents are presented for testing. We construct new benchmarks that measure the MIA performances at a continuous scale of data samples, from sentences (n-grams) to a collection of documents (multiple chunks of tokens). To validate the efficacy of current MIA approaches at greater scales, we adapt a recent work on Dataset Inference (DI) for the task of binary membership detection that aggregates paragraph-level MIA features to enable MIA at document and collection of documents level. This baseline achieves the first successful MIA on pre-trained and fine-tuned LLMs.
Calibrating Large Language Models Using Their Generations Only
Mar 09, 2024As large language models (LLMs) are increasingly deployed in user-facing applications, building trust and maintaining safety by accurately quantifying a model's confidence in its prediction becomes even more important. However, finding effective ways to calibrate LLMs - especially when the only interface to the models is their generated text - remains a challenge. We propose APRICOT (auxiliary prediction of confidence targets): A method to set confidence targets and train an additional model that predicts an LLM's confidence based on its textual input and output alone. This approach has several advantages: It is conceptually simple, does not require access to the target model beyond its output, does not interfere with the language generation, and has a multitude of potential usages, for instance by verbalizing the predicted confidence or adjusting the given answer based on the confidence. We show how our approach performs competitively in terms of calibration error for white-box and black-box LLMs on closed-book question-answering to detect incorrect LLM answers.
TRAP: Targeted Random Adversarial Prompt Honeypot for Black-Box Identification
Feb 20, 2024



Large Language Model (LLM) services and models often come with legal rules on who can use them and how they must use them. Assessing the compliance of the released LLMs is crucial, as these rules protect the interests of the LLM contributor and prevent misuse. In this context, we describe the novel problem of Black-box Identity Verification (BBIV). The goal is to determine whether a third-party application uses a certain LLM through its chat function. We propose a method called Targeted Random Adversarial Prompt (TRAP) that identifies the specific LLM in use. We repurpose adversarial suffixes, originally proposed for jailbreaking, to get a pre-defined answer from the target LLM, while other models give random answers. TRAP detects the target LLMs with over 95% true positive rate at under 0.2% false positive rate even after a single interaction. TRAP remains effective even if the LLM has minor changes that do not significantly alter the original function.
ProPILE: Probing Privacy Leakage in Large Language Models
Jul 04, 2023



The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.