 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSPO: Constraint-Sensitive Policy Optimization for Safe Reinforcement Learning
Jun 12, 2026Safe reinforcement learning (Safe RL) aims to maximize expected return while satisfying safety constraints, typically modeled as Constrained Markov Decision Processes (CMDPs). While primal-dual methods scale well to deep RL, they often suffer from delayed constraint correction, leading to oscillatory behavior and prolonged safety violations. In this paper, we propose Constraint-Sensitive Policy Optimization (CSPO), a first-order primal-dual method that incorporates local constraint sensitivity into policy updates. CSPO augments the primal objective with a constraint-sensitive correction derived from the shortest signed distance to the safety boundary, enabling smarter recovery steps back to safety, compensating for delayed Lagrange multiplier updates, reducing oscillations near the boundary, and preserving the KKT solutions of the original constrained problem. Experiments on navigation and locomotion benchmarks demonstrate that CSPO achieves faster safety recovery and high reward preservation, resulting in higher constrained returns compared to state-of-the-art primal-dual and penalty-based methods
Optimized Federated Knowledge Distillation with Distributed Neural Architecture Search
May 20, 2026Federated Learning (FL) enables collaborative model training without centralizing data. However, real-world deployments must simultaneously address statistical heterogeneity across client data (non-IID), system heterogeneity in device capabilities, and communication efficiency. Existing FL approaches mitigate these challenges through improved aggregation, personalization, or knowledge distillation, but they almost universally assume a fixed client architecture, limiting adaptability to heterogeneous data complexity and hardware constraints. This architectural constraint often leads to suboptimal trade-offs between accuracy and efficiency in real-world FL systems. This work introduces FedKDNAS, a distillation-driven FL framework that combines client-side neural architecture selection with distillation of server-coordinated knowledge. Each client autonomously selects a lightweight model under accuracy-resource constraints. It then trains it locally using a hybrid objective combining supervised learning and knowledge distillation and shares only predictions on a public reference set. The server then aggregates and smooths these predictions, optionally combining them with a teacher model, to produce stable distillation targets for the next round. Extensive evaluation on six datasets against six representative FL baselines (FedAvg, Ditto, FedMD, FedDF, FedDistill, Local-KD) demonstrates that FedKDNAS consistently achieves superior Pareto efficiency, improving accuracy by up to 15\% under non-IID conditions, reducing client CPU usage by approximately 28\%, and decreasing communication overhead by up to 44 times while maintaining lightweight logit-based communication.
Defective Task Descriptions in LLM-Based Code Generation: Detection and Analysis
Apr 27, 2026Large language models are widely used for code generation, yet they rely on an implicit assumption that the task descriptions are sufficiently detailed and well-formed. However, in practice, users may provide defective descriptions, which can have a strong effect on code correctness. To address this issue, we develop SpecValidator, a lightweight classifier based on a small model that has been parameter-efficiently finetuned, to automatically detect task description defects. We evaluate SpecValidator on three types of defects, Lexical Vagueness, Under-Specification and Syntax-Formatting on 3 benchmarks with task descriptions of varying structure and complexity. Our results show that SpecValidator achieves defect detection of F1 = 0.804 and MCC = 0.745, significantly outperforming GPT-5-mini (F1 = 0.469 and MCC = 0.281) and Claude Sonnet 4 (F1 = 0.518 and MCC = 0.359). Perhaps more importantly, our analysis indicates that SpecValidator can generalize to unseen issues and detect unknown Under-Specification defects in the original (real) descriptions of the benchmarks used. Our results also show that the robustness of LLMs in task description defects depends primarily on the type of defect and the characteristics of the task description, rather than the capacity of the model, with Under-Specification defects being the most severe. We further found that benchmarks with richer contextual grounding, such as LiveCodeBench, exhibit substantially greater resilience, highlighting the importance of structured task descriptions for reliable LLM-based code generation.
An Empirical Study of the Imbalance Issue in Software Vulnerability Detection
Feb 12, 2026Vulnerability detection is crucial to protect software security. Nowadays, deep learning (DL) is the most promising technique to automate this detection task, leveraging its superior ability to extract patterns and representations within extensive code volumes. Despite its promise, DL-based vulnerability detection remains in its early stages, with model performance exhibiting variability across datasets. Drawing insights from other well-explored application areas like computer vision, we conjecture that the imbalance issue (the number of vulnerable code is extremely small) is at the core of the phenomenon. To validate this, we conduct a comprehensive empirical study involving nine open-source datasets and two state-of-the-art DL models. The results confirm our conjecture. We also obtain insightful findings on how existing imbalance solutions perform in vulnerability detection. It turns out that these solutions perform differently as well across datasets and evaluation metrics. Specifically: 1) Focal loss is more suitable to improve the precision, 2) mean false error and class-balanced loss encourages the recall, and 3) random over-sampling facilitates the F1-measure. However, none of them excels across all metrics. To delve deeper, we explore external influences on these solutions and offer insights for developing new solutions.
When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions
Jul 27, 2025
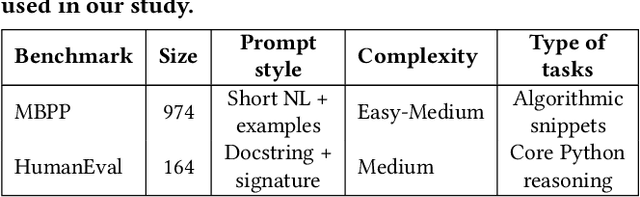
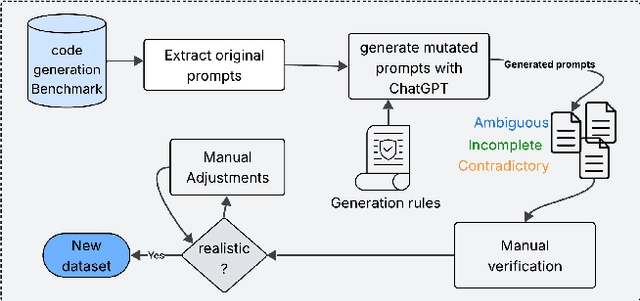
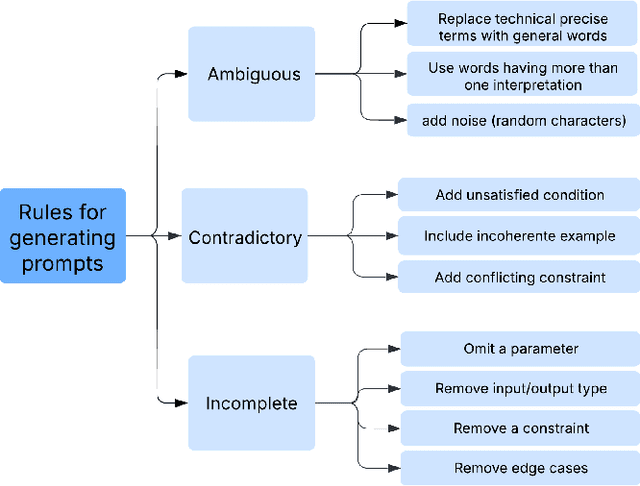
Large Language Models (LLMs) have demonstrated impressive performance in code generation tasks under idealized conditions, where task descriptions are clear and precise. However, in practice, task descriptions frequently exhibit ambiguity, incompleteness, or internal contradictions. In this paper, we present the first empirical study examining the robustness of state-of-the-art code generation models when faced with such unclear task descriptions. We extend the HumanEval and MBPP benchmarks by systematically introducing realistic task descriptions flaws through guided mutation strategies, producing a dataset that mirrors the messiness of informal developer instructions. We evaluate multiple LLMs of varying sizes and architectures, analyzing their functional correctness and failure modes across task descriptions categories. Our findings reveal that even minor imperfections in task description phrasing can cause significant performance degradation, with contradictory task descriptions resulting in numerous logical errors. Moreover, while larger models tend to be more resilient than smaller variants, they are not immune to the challenges posed by unclear requirements. We further analyze semantic error patterns and identify correlations between description clarity, model behavior, and error types. Our results underscore the critical need for developing LLMs that are not only powerful but also robust to the imperfections inherent in natural user tasks, highlighting important considerations for improving model training strategies, designing more realistic evaluation benchmarks, and ensuring reliable deployment in practical software development environments.
Leveraging External Factors in Household-Level Electrical Consumption Forecasting using Hypernetworks
Jun 17, 2025
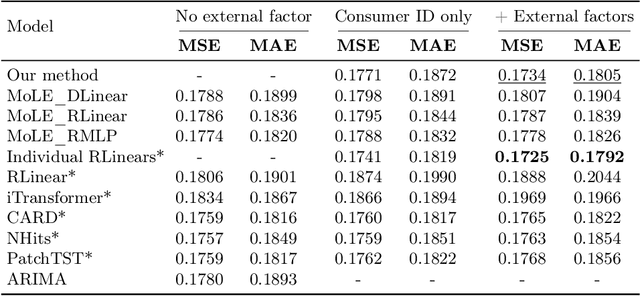

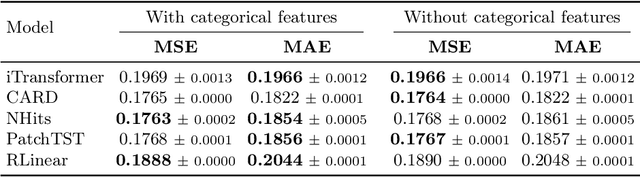
Accurate electrical consumption forecasting is crucial for efficient energy management and resource allocation. While traditional time series forecasting relies on historical patterns and temporal dependencies, incorporating external factors -- such as weather indicators -- has shown significant potential for improving prediction accuracy in complex real-world applications. However, the inclusion of these additional features often degrades the performance of global predictive models trained on entire populations, despite improving individual household-level models. To address this challenge, we found that a hypernetwork architecture can effectively leverage external factors to enhance the accuracy of global electrical consumption forecasting models, by specifically adjusting the model weights to each consumer. We collected a comprehensive dataset spanning two years, comprising consumption data from over 6000 luxembourgish households and corresponding external factors such as weather indicators, holidays, and major local events. By comparing various forecasting models, we demonstrate that a hypernetwork approach outperforms existing methods when associated to external factors, reducing forecasting errors and achieving the best accuracy while maintaining the benefits of a global model.
HInter: Exposing Hidden Intersectional Bias in Large Language Models
Mar 15, 2025Large Language Models (LLMs) may portray discrimination towards certain individuals, especially those characterized by multiple attributes (aka intersectional bias). Discovering intersectional bias in LLMs is challenging, as it involves complex inputs on multiple attributes (e.g. race and gender). To address this challenge, we propose HInter, a test technique that synergistically combines mutation analysis, dependency parsing and metamorphic oracles to automatically detect intersectional bias in LLMs. HInter generates test inputs by systematically mutating sentences using multiple mutations, validates inputs via a dependency invariant and detects biases by checking the LLM response on the original and mutated sentences. We evaluate HInter using six LLM architectures and 18 LLM models (GPT3.5, Llama2, BERT, etc) and find that 14.61% of the inputs generated by HInter expose intersectional bias. Results also show that our dependency invariant reduces false positives (incorrect test inputs) by an order of magnitude. Finally, we observed that 16.62% of intersectional bias errors are hidden, meaning that their corresponding atomic cases do not trigger biases. Overall, this work emphasize the importance of testing LLMs for intersectional bias.
Robustness Analysis of AI Models in Critical Energy Systems
Jun 20, 2024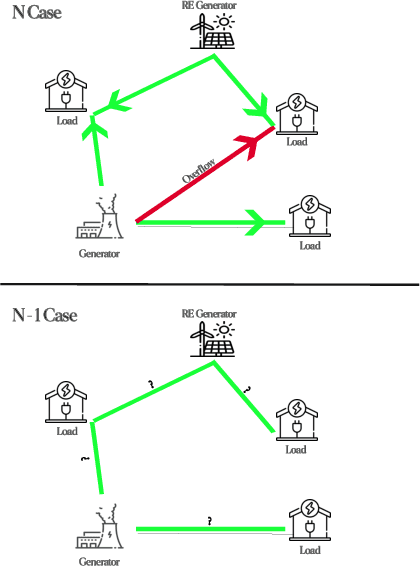
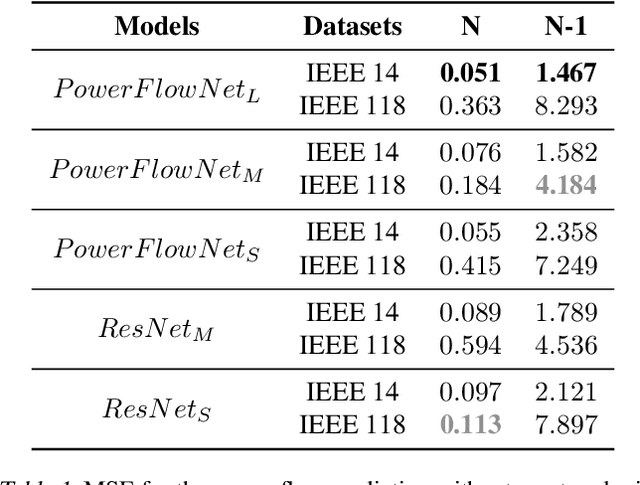
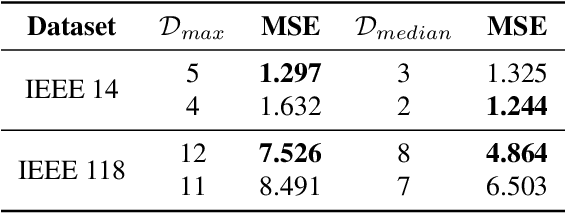
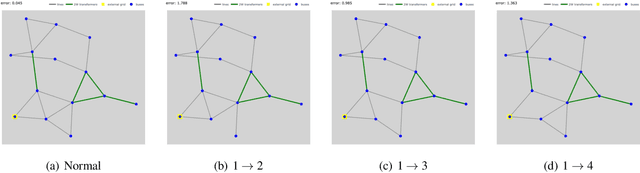
This paper analyzes the robustness of state-of-the-art AI-based models for power grid operations under the $N-1$ security criterion. While these models perform well in regular grid settings, our results highlight a significant loss in accuracy following the disconnection of a line.%under this security criterion. Using graph theory-based analysis, we demonstrate the impact of node connectivity on this loss. Our findings emphasize the need for practical scenario considerations in developing AI methodologies for critical infrastructure.
Constrained Adaptive Attacks: Realistic Evaluation of Adversarial Examples and Robust Training of Deep Neural Networks for Tabular Data
Nov 08, 2023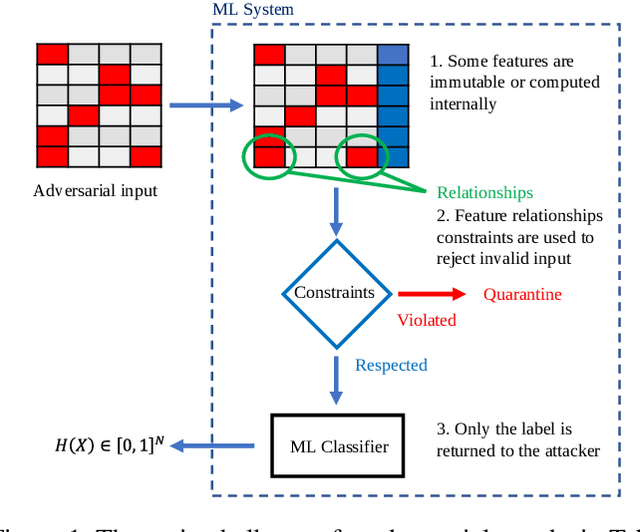



State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there is to date no realistic protocol to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data such as categorical features, immutability, and feature relationship constraints. To fill this gap, we propose CAA, the first efficient evasion attack for constrained tabular deep learning models. CAA is an iterative parameter-free attack that combines gradient and search attacks to generate adversarial examples under constraints. We leverage CAA to build a benchmark of deep tabular models across three popular use cases: credit scoring, phishing and botnet attacks detection. Our benchmark supports ten threat models with increasing capabilities of the attacker, and reflects real-world attack scenarios for each use case. Overall, our results demonstrate how domain knowledge, adversarial training, and attack budgets impact the robustness assessment of deep tabular models and provide security practitioners with a set of recommendations to improve the robustness of deep tabular models against various evasion attack scenarios.
Evaluating the Robustness of Test Selection Methods for Deep Neural Networks
Jul 29, 2023Testing deep learning-based systems is crucial but challenging due to the required time and labor for labeling collected raw data. To alleviate the labeling effort, multiple test selection methods have been proposed where only a subset of test data needs to be labeled while satisfying testing requirements. However, we observe that such methods with reported promising results are only evaluated under simple scenarios, e.g., testing on original test data. This brings a question to us: are they always reliable? In this paper, we explore when and to what extent test selection methods fail for testing. Specifically, first, we identify potential pitfalls of 11 selection methods from top-tier venues based on their construction. Second, we conduct a study on five datasets with two model architectures per dataset to empirically confirm the existence of these pitfalls. Furthermore, we demonstrate how pitfalls can break the reliability of these methods. Concretely, methods for fault detection suffer from test data that are: 1) correctly classified but uncertain, or 2) misclassified but confident. Remarkably, the test relative coverage achieved by such methods drops by up to 86.85%. On the other hand, methods for performance estimation are sensitive to the choice of intermediate-layer output. The effectiveness of such methods can be even worse than random selection when using an inappropriate layer.