 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of the Imbalance Issue in Software Vulnerability Detection
Feb 12, 2026Vulnerability detection is crucial to protect software security. Nowadays, deep learning (DL) is the most promising technique to automate this detection task, leveraging its superior ability to extract patterns and representations within extensive code volumes. Despite its promise, DL-based vulnerability detection remains in its early stages, with model performance exhibiting variability across datasets. Drawing insights from other well-explored application areas like computer vision, we conjecture that the imbalance issue (the number of vulnerable code is extremely small) is at the core of the phenomenon. To validate this, we conduct a comprehensive empirical study involving nine open-source datasets and two state-of-the-art DL models. The results confirm our conjecture. We also obtain insightful findings on how existing imbalance solutions perform in vulnerability detection. It turns out that these solutions perform differently as well across datasets and evaluation metrics. Specifically: 1) Focal loss is more suitable to improve the precision, 2) mean false error and class-balanced loss encourages the recall, and 3) random over-sampling facilitates the F1-measure. However, none of them excels across all metrics. To delve deeper, we explore external influences on these solutions and offer insights for developing new solutions.
Data Quality Issues in Vulnerability Detection Datasets
Oct 08, 2024



Vulnerability detection is a crucial yet challenging task to identify potential weaknesses in software for cyber security. Recently, deep learning (DL) has made great progress in automating the detection process. Due to the complex multi-layer structure and a large number of parameters, a DL model requires massive labeled (vulnerable or secure) source code to gain knowledge to effectively distinguish between vulnerable and secure code. In the literature, many datasets have been created to train DL models for this purpose. However, these datasets suffer from several issues that will lead to low detection accuracy of DL models. In this paper, we define three critical issues (i.e., data imbalance, low vulnerability coverage, biased vulnerability distribution) that can significantly affect the model performance and three secondary issues (i.e., errors in source code, mislabeling, noisy historical data) that also affect the performance but can be addressed through a dedicated pre-processing procedure. In addition, we conduct a study of 14 papers along with 54 datasets for vulnerability detection to confirm these defined issues. Furthermore, we discuss good practices to use existing datasets and to create new ones.
Hazards in Deep Learning Testing: Prevalence, Impact and Recommendations
Sep 11, 2023Much research on Machine Learning testing relies on empirical studies that evaluate and show their potential. However, in this context empirical results are sensitive to a number of parameters that can adversely impact the results of the experiments and potentially lead to wrong conclusions (Type I errors, i.e., incorrectly rejecting the Null Hypothesis). To this end, we survey the related literature and identify 10 commonly adopted empirical evaluation hazards that may significantly impact experimental results. We then perform a sensitivity analysis on 30 influential studies that were published in top-tier SE venues, against our hazard set and demonstrate their criticality. Our findings indicate that all 10 hazards we identify have the potential to invalidate experimental findings, such as those made by the related literature, and should be handled properly. Going a step further, we propose a point set of 10 good empirical practices that has the potential to mitigate the impact of the hazards. We believe our work forms the first step towards raising awareness of the common pitfalls and good practices within the software engineering community and hopefully contribute towards setting particular expectations for empirical research in the field of deep learning testing.
Evaluating the Robustness of Test Selection Methods for Deep Neural Networks
Jul 29, 2023Testing deep learning-based systems is crucial but challenging due to the required time and labor for labeling collected raw data. To alleviate the labeling effort, multiple test selection methods have been proposed where only a subset of test data needs to be labeled while satisfying testing requirements. However, we observe that such methods with reported promising results are only evaluated under simple scenarios, e.g., testing on original test data. This brings a question to us: are they always reliable? In this paper, we explore when and to what extent test selection methods fail for testing. Specifically, first, we identify potential pitfalls of 11 selection methods from top-tier venues based on their construction. Second, we conduct a study on five datasets with two model architectures per dataset to empirically confirm the existence of these pitfalls. Furthermore, we demonstrate how pitfalls can break the reliability of these methods. Concretely, methods for fault detection suffer from test data that are: 1) correctly classified but uncertain, or 2) misclassified but confident. Remarkably, the test relative coverage achieved by such methods drops by up to 86.85%. On the other hand, methods for performance estimation are sensitive to the choice of intermediate-layer output. The effectiveness of such methods can be even worse than random selection when using an inappropriate layer.
CodeLens: An Interactive Tool for Visualizing Code Representations
Jul 27, 2023Representing source code in a generic input format is crucial to automate software engineering tasks, e.g., applying machine learning algorithms to extract information. Visualizing code representations can further enable human experts to gain an intuitive insight into the code. Unfortunately, as of today, there is no universal tool that can simultaneously visualise different types of code representations. In this paper, we introduce a tool, CodeLens, which provides a visual interaction environment that supports various representation methods and helps developers understand and explore them. CodeLens is designed to support multiple programming languages, such as Java, Python, and JavaScript, and four types of code representations, including sequence of tokens, abstract syntax tree (AST), data flow graph (DFG), and control flow graph (CFG). By using CodeLens, developers can quickly visualize the specific code representation and also obtain the represented inputs for models of code. The Web-based interface of CodeLens is available at http://www.codelens.org. The demonstration video can be found at http://www.codelens.org/demo.
Boosting Source Code Learning with Data Augmentation: An Empirical Study
Mar 13, 2023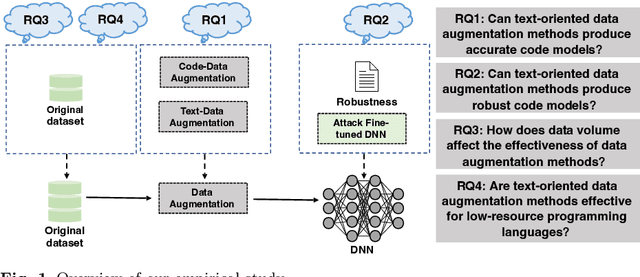
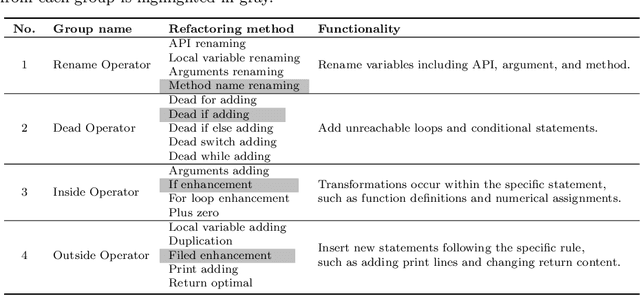
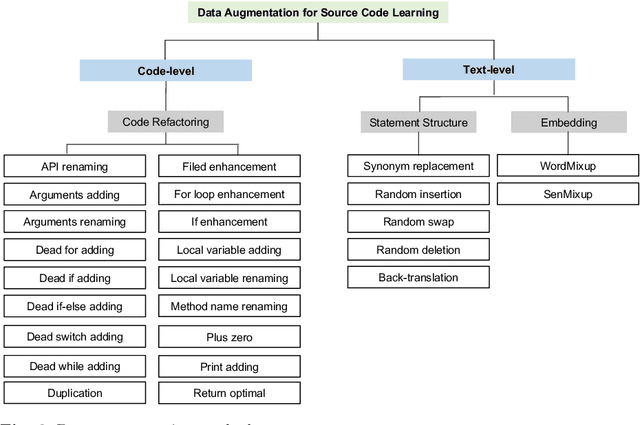
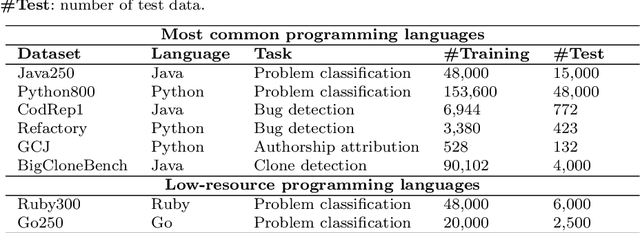
The next era of program understanding is being propelled by the use of machine learning to solve software problems. Recent studies have shown surprising results of source code learning, which applies deep neural networks (DNNs) to various critical software tasks, e.g., bug detection and clone detection. This success can be greatly attributed to the utilization of massive high-quality training data, and in practice, data augmentation, which is a technique used to produce additional training data, has been widely adopted in various domains, such as computer vision. However, in source code learning, data augmentation has not been extensively studied, and existing practice is limited to simple syntax-preserved methods, such as code refactoring. Essentially, source code is often represented in two ways, namely, sequentially as text data and structurally as graph data, when it is used as training data in source code learning. Inspired by these analogy relations, we take an early step to investigate whether data augmentation methods that are originally used for text and graphs are effective in improving the training quality of source code learning. To that end, we first collect and categorize data augmentation methods in the literature. Second, we conduct a comprehensive empirical study on four critical tasks and 11 DNN architectures to explore the effectiveness of 12 data augmentation methods (including code refactoring and 11 other methods for text and graph data). Our results identify the data augmentation methods that can produce more accurate and robust models for source code learning, including those based on mixup (e.g., SenMixup for texts and Manifold-Mixup for graphs), and those that slightly break the syntax of source code (e.g., random swap and random deletion for texts).
Enhancing Code Classification by Mixup-Based Data Augmentation
Oct 06, 2022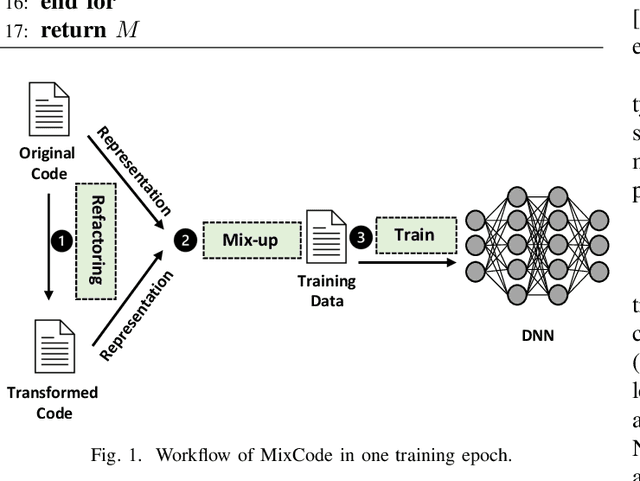
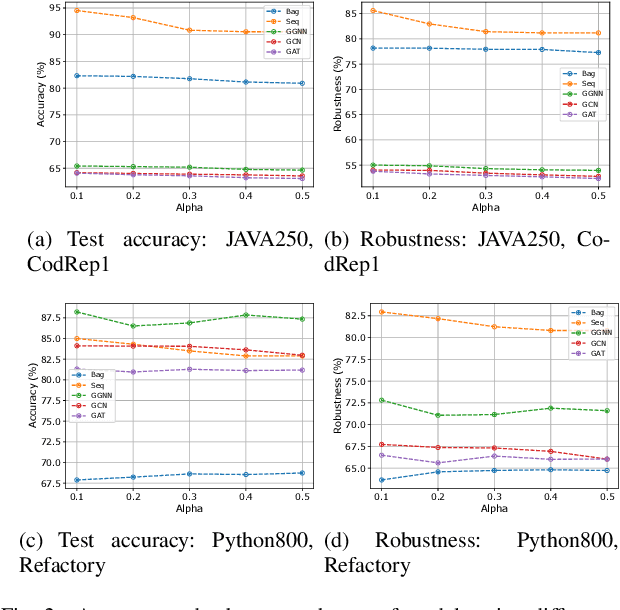
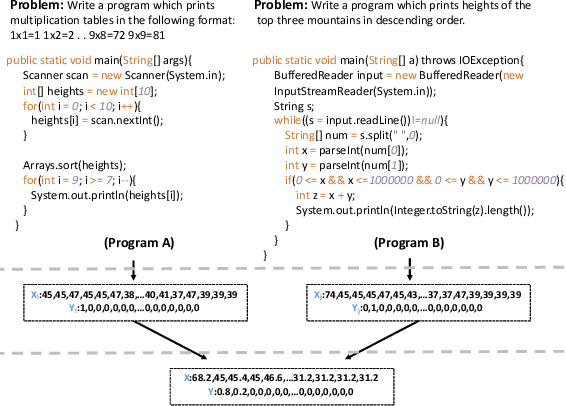
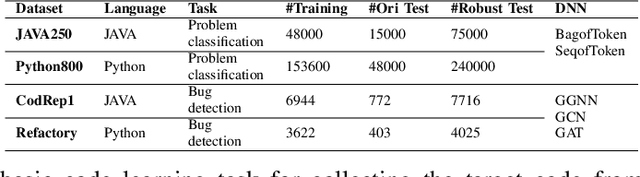
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.
Enhancing Mixup-Based Graph Learning for Language Processing via Hybrid Pooling
Oct 06, 2022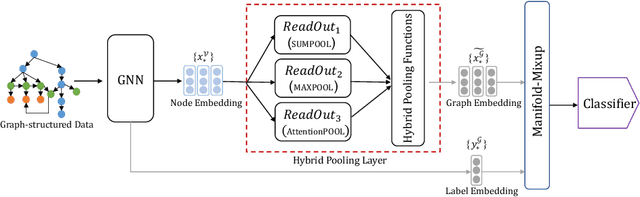
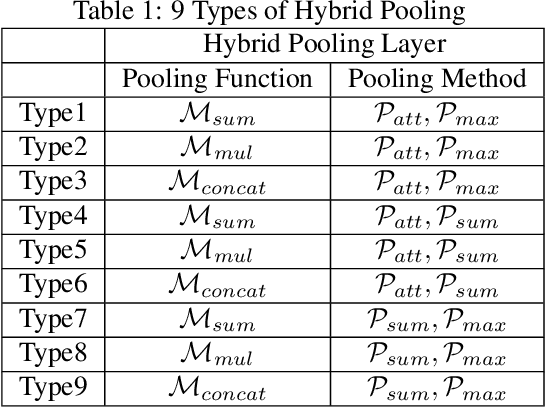
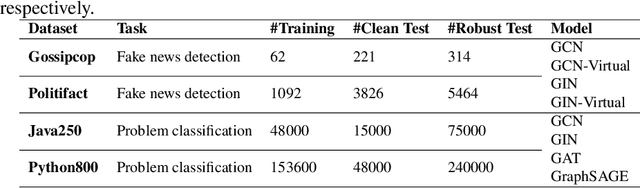
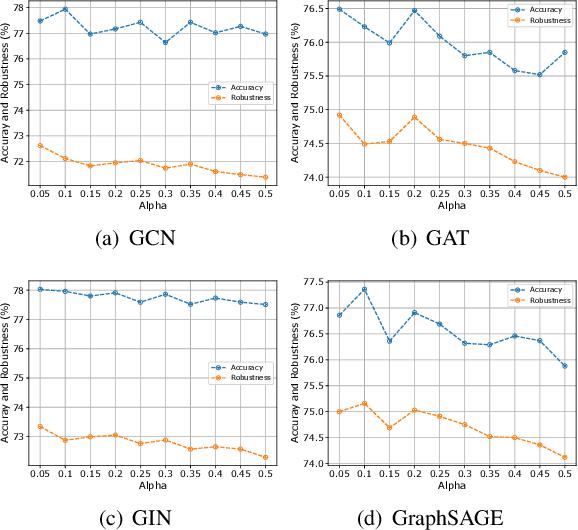
Graph neural networks (GNNs) have recently been popular in natural language and programming language processing, particularly in text and source code classification. Graph pooling which processes node representation into the entire graph representation, which can be used for multiple downstream tasks, e.g., graph classification, is a crucial component of GNNs. Recently, to enhance graph learning, Manifold Mixup, a data augmentation strategy that mixes the graph data vector after the pooling layer, has been introduced. However, since there are a series of graph pooling methods, how they affect the effectiveness of such a Mixup approach is unclear. In this paper, we take the first step to explore the influence of graph pooling methods on the effectiveness of the Mixup-based data augmentation approach. Specifically, 9 types of hybrid pooling methods are considered in the study, e.g., $\mathcal{M}_{sum}(\mathcal{P}_{att},\mathcal{P}_{max})$. The experimental results on both natural language datasets (Gossipcop, Politifact) and programming language datasets (Java250, Python800) demonstrate that hybrid pooling methods are more suitable for Mixup than the standard max pooling and the state-of-the-art graph multiset transformer (GMT) pooling, in terms of metric accuracy and robustness.
Efficient Testing of Deep Neural Networks via Decision Boundary Analysis
Jul 22, 2022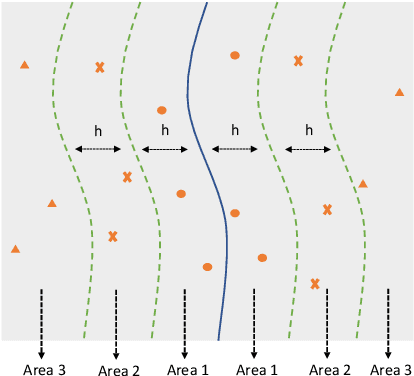

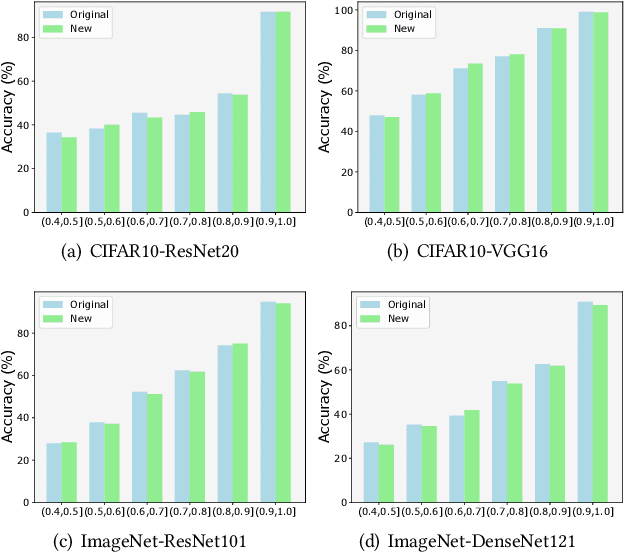

Deep learning plays a more and more important role in our daily life due to its competitive performance in multiple industrial application domains. As the core of DL-enabled systems, deep neural networks automatically learn knowledge from carefully collected and organized training data to gain the ability to predict the label of unseen data. Similar to the traditional software systems that need to be comprehensively tested, DNNs also need to be carefully evaluated to make sure the quality of the trained model meets the demand. In practice, the de facto standard to assess the quality of DNNs in industry is to check their performance (accuracy) on a collected set of labeled test data. However, preparing such labeled data is often not easy partly because of the huge labeling effort, i.e., data labeling is labor-intensive, especially with the massive new incoming unlabeled data every day. Recent studies show that test selection for DNN is a promising direction that tackles this issue by selecting minimal representative data to label and using these data to assess the model. However, it still requires human effort and cannot be automatic. In this paper, we propose a novel technique, named Aries, that can estimate the performance of DNNs on new unlabeled data using only the information obtained from the original test data. The key insight behind our technique is that the model should have similar prediction accuracy on the data which have similar distances to the decision boundary. We performed a large-scale evaluation of our technique on 13 types of data transformation methods. The results demonstrate the usefulness of our technique that the estimated accuracy by Aries is only 0.03% -- 2.60% (on average 0.61%) off the true accuracy. Besides, Aries also outperforms the state-of-the-art selection-labeling-based methods in most (96 out of 128) cases.
CodeS: A Distribution Shift Benchmark Dataset for Source Code Learning
Jun 11, 2022



Over the past few years, deep learning (DL) has been continuously expanding its applications and becoming a driving force for large-scale source code analysis in the big code era. Distribution shift, where the test set follows a different distribution from the training set, has been a longstanding challenge for the reliable deployment of DL models due to the unexpected accuracy degradation. Although recent progress on distribution shift benchmarking has been made in domains such as computer vision and natural language process. Limited progress has been made on distribution shift analysis and benchmarking for source code tasks, on which there comes a strong demand due to both its volume and its important role in supporting the foundations of almost all industrial sectors. To fill this gap, this paper initiates to propose CodeS, a distribution shift benchmark dataset, for source code learning. Specifically, CodeS supports 2 programming languages (i.e., Java and Python) and 5 types of code distribution shifts (i.e., task, programmer, time-stamp, token, and CST). To the best of our knowledge, we are the first to define the code representation-based distribution shifts. In the experiments, we first evaluate the effectiveness of existing out-of-distribution detectors and the reasonability of the distribution shift definitions and then measure the model generalization of popular code learning models (e.g., CodeBERT) on classification task. The results demonstrate that 1) only softmax score-based OOD detectors perform well on CodeS, 2) distribution shift causes the accuracy degradation in all code classification models, 3) representation-based distribution shifts have a higher impact on the model than others, and 4) pre-trained models are more resistant to distribution shifts. We make CodeS publicly available, enabling follow-up research on the quality assessment of code learning models.