 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Testing of Deep Neural Networks via Decision Boundary Analysis
Paper and Code
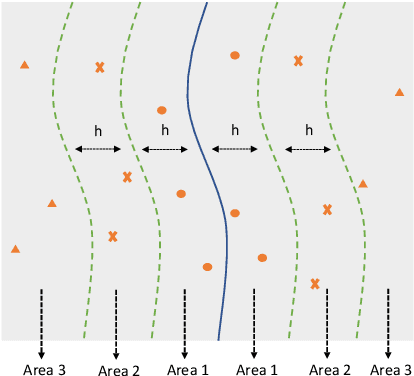

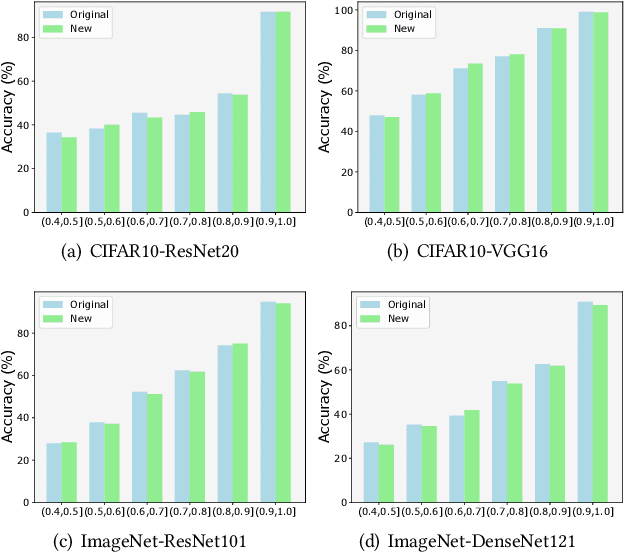

Deep learning plays a more and more important role in our daily life due to its competitive performance in multiple industrial application domains. As the core of DL-enabled systems, deep neural networks automatically learn knowledge from carefully collected and organized training data to gain the ability to predict the label of unseen data. Similar to the traditional software systems that need to be comprehensively tested, DNNs also need to be carefully evaluated to make sure the quality of the trained model meets the demand. In practice, the de facto standard to assess the quality of DNNs in industry is to check their performance (accuracy) on a collected set of labeled test data. However, preparing such labeled data is often not easy partly because of the huge labeling effort, i.e., data labeling is labor-intensive, especially with the massive new incoming unlabeled data every day. Recent studies show that test selection for DNN is a promising direction that tackles this issue by selecting minimal representative data to label and using these data to assess the model. However, it still requires human effort and cannot be automatic. In this paper, we propose a novel technique, named Aries, that can estimate the performance of DNNs on new unlabeled data using only the information obtained from the original test data. The key insight behind our technique is that the model should have similar prediction accuracy on the data which have similar distances to the decision boundary. We performed a large-scale evaluation of our technique on 13 types of data transformation methods. The results demonstrate the usefulness of our technique that the estimated accuracy by Aries is only 0.03% -- 2.60% (on average 0.61%) off the true accuracy. Besides, Aries also outperforms the state-of-the-art selection-labeling-based methods in most (96 out of 128) cases.