 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Code Classification by Mixup-Based Data Augmentation
Paper and Code
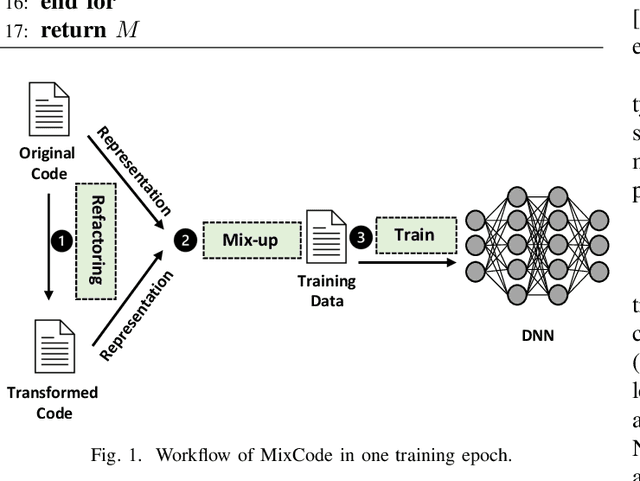
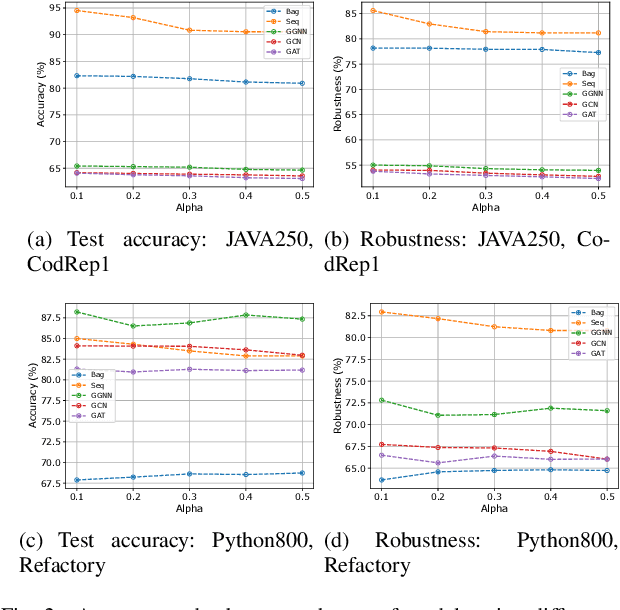
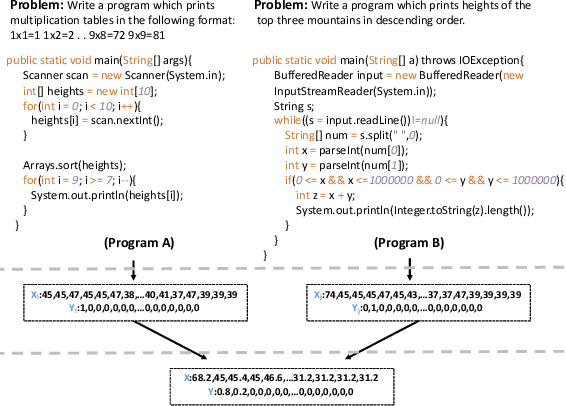
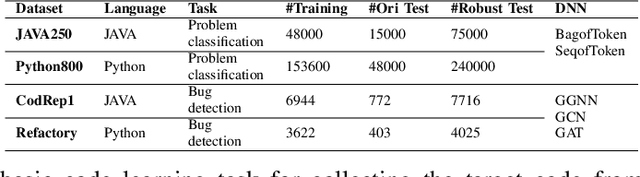
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.