 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Guided Data Augmentation for Neural-Based Code Understanding
Feb 24, 2024Pre-trained code models lead the era of code intelligence. Many models have been designed with impressive performance recently. However, one important problem, data augmentation for code data that automatically helps developers prepare training data lacks study in the field of code learning. In this paper, we introduce a general data augmentation framework, GenCode, to enhance the training of code understanding models. GenCode follows a generation-and-selection paradigm to prepare useful training codes. Specifically, it uses code transformation techniques to generate new code candidates first and then selects important ones as the training data by importance metrics. To evaluate the effectiveness of GenCode with a general importance metric -- loss value, we conduct experiments on four code understanding tasks (e.g., code clone detection) and three pre-trained code models (e.g., CodeT5). Compared to the state-of-the-art (SOTA) code augmentation method, MixCode, GenCode produces code models with 2.92% higher accuracy and 4.90% robustness on average.
Boosting Source Code Learning with Data Augmentation: An Empirical Study
Mar 13, 2023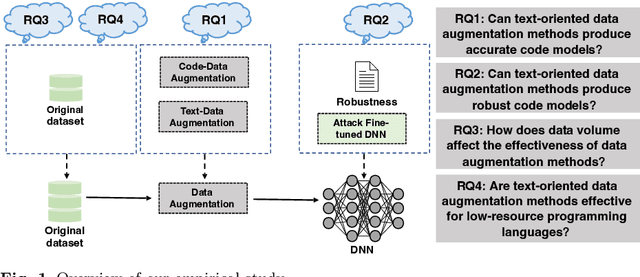
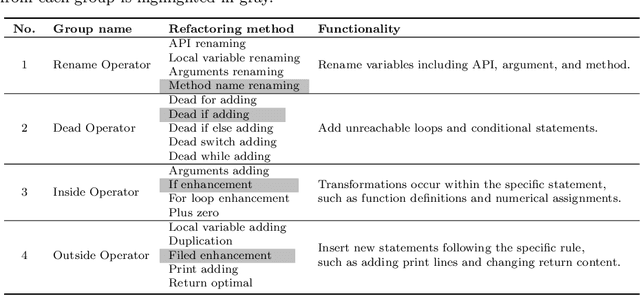
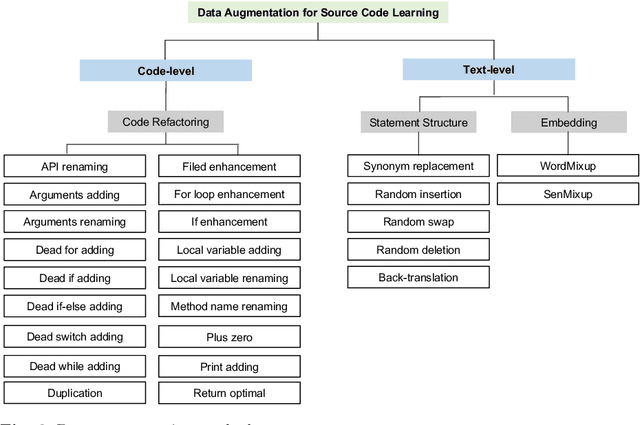
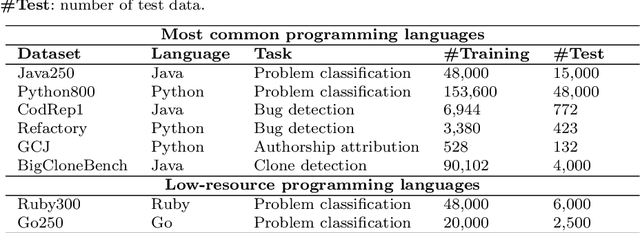
The next era of program understanding is being propelled by the use of machine learning to solve software problems. Recent studies have shown surprising results of source code learning, which applies deep neural networks (DNNs) to various critical software tasks, e.g., bug detection and clone detection. This success can be greatly attributed to the utilization of massive high-quality training data, and in practice, data augmentation, which is a technique used to produce additional training data, has been widely adopted in various domains, such as computer vision. However, in source code learning, data augmentation has not been extensively studied, and existing practice is limited to simple syntax-preserved methods, such as code refactoring. Essentially, source code is often represented in two ways, namely, sequentially as text data and structurally as graph data, when it is used as training data in source code learning. Inspired by these analogy relations, we take an early step to investigate whether data augmentation methods that are originally used for text and graphs are effective in improving the training quality of source code learning. To that end, we first collect and categorize data augmentation methods in the literature. Second, we conduct a comprehensive empirical study on four critical tasks and 11 DNN architectures to explore the effectiveness of 12 data augmentation methods (including code refactoring and 11 other methods for text and graph data). Our results identify the data augmentation methods that can produce more accurate and robust models for source code learning, including those based on mixup (e.g., SenMixup for texts and Manifold-Mixup for graphs), and those that slightly break the syntax of source code (e.g., random swap and random deletion for texts).
Enhancing Mixup-Based Graph Learning for Language Processing via Hybrid Pooling
Oct 06, 2022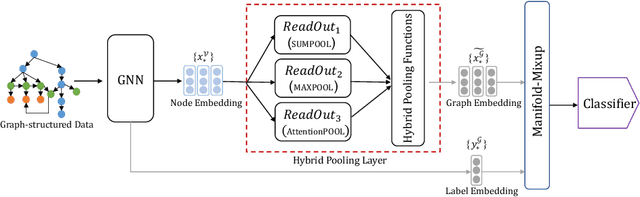
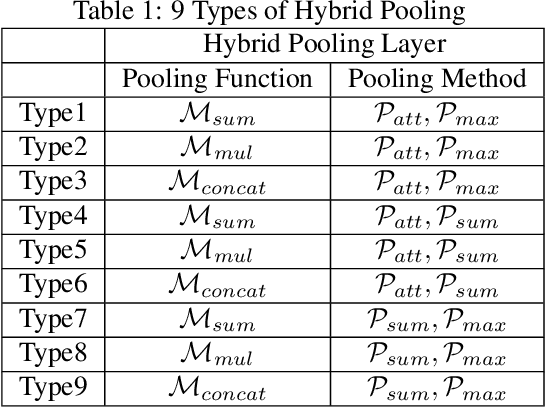
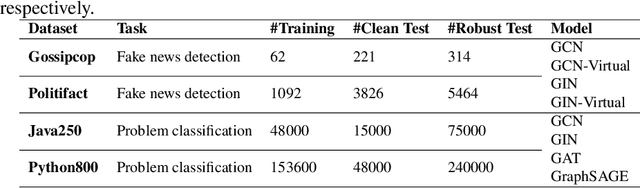
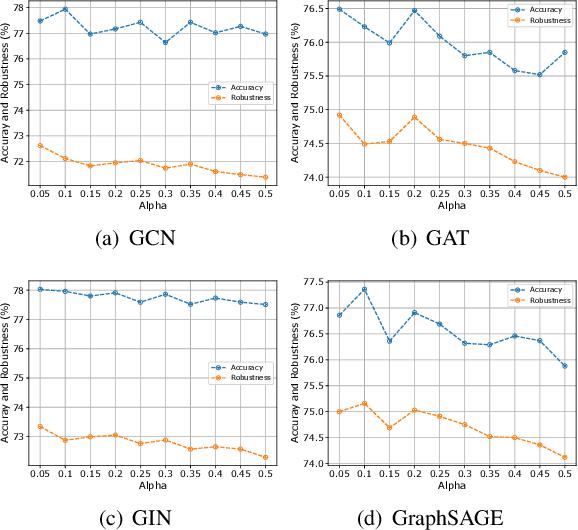
Graph neural networks (GNNs) have recently been popular in natural language and programming language processing, particularly in text and source code classification. Graph pooling which processes node representation into the entire graph representation, which can be used for multiple downstream tasks, e.g., graph classification, is a crucial component of GNNs. Recently, to enhance graph learning, Manifold Mixup, a data augmentation strategy that mixes the graph data vector after the pooling layer, has been introduced. However, since there are a series of graph pooling methods, how they affect the effectiveness of such a Mixup approach is unclear. In this paper, we take the first step to explore the influence of graph pooling methods on the effectiveness of the Mixup-based data augmentation approach. Specifically, 9 types of hybrid pooling methods are considered in the study, e.g., $\mathcal{M}_{sum}(\mathcal{P}_{att},\mathcal{P}_{max})$. The experimental results on both natural language datasets (Gossipcop, Politifact) and programming language datasets (Java250, Python800) demonstrate that hybrid pooling methods are more suitable for Mixup than the standard max pooling and the state-of-the-art graph multiset transformer (GMT) pooling, in terms of metric accuracy and robustness.
Enhancing Code Classification by Mixup-Based Data Augmentation
Oct 06, 2022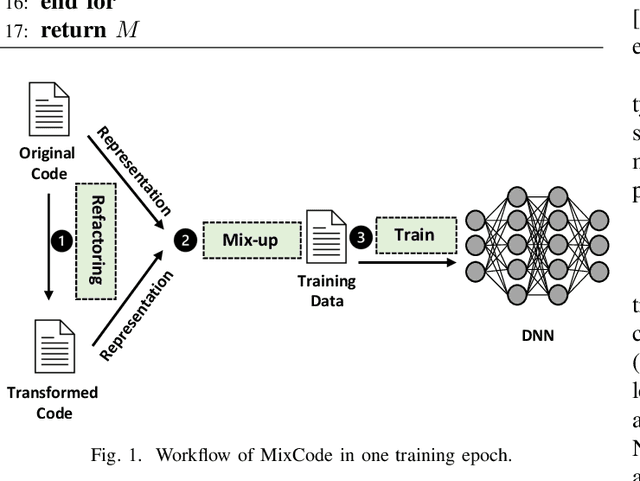
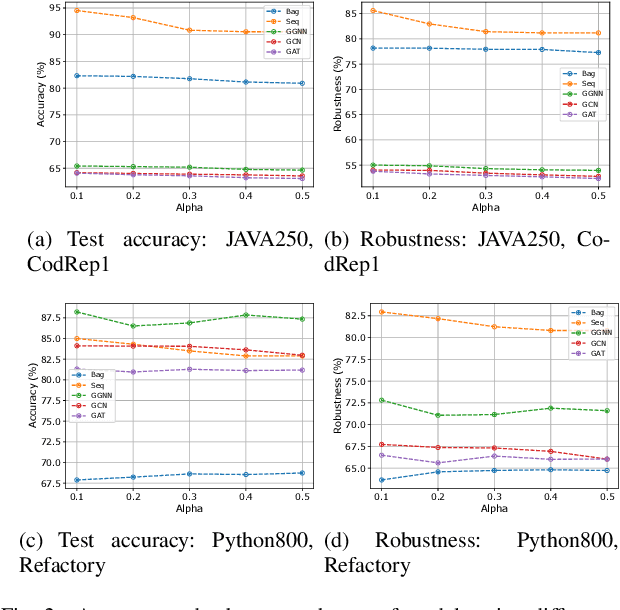
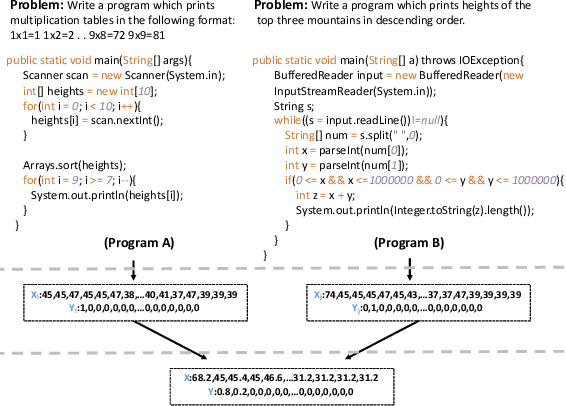
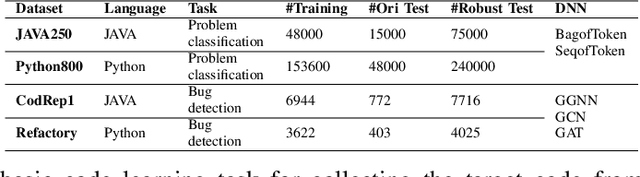
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.