 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Aware Heterogeneous GNN Architecture for Real-Time BESS Optimization in Unbalanced Distribution Systems
Dec 10, 2025Battery energy storage systems (BESS) have become increasingly vital in three-phase unbalanced distribution grids for maintaining voltage stability and enabling optimal dispatch. However, existing deep learning approaches often lack explicit three-phase representation, making it difficult to accurately model phase-specific dynamics and enforce operational constraints--leading to infeasible dispatch solutions. This paper demonstrates that by embedding detailed three-phase grid information--including phase voltages, unbalanced loads, and BESS states--into heterogeneous graph nodes, diverse GNN architectures (GCN, GAT, GraphSAGE, GPS) can jointly predict network state variables with high accuracy. Moreover, a physics-informed loss function incorporates critical battery constraints--SoC and C-rate limits--via soft penalties during training. Experimental validation on the CIGRE 18-bus distribution system shows that this embedding-loss approach achieves low prediction errors, with bus voltage MSEs of 6.92e-07 (GCN), 1.21e-06 (GAT), 3.29e-05 (GPS), and 9.04e-07 (SAGE). Importantly, the physics-informed method ensures nearly zero SoC and C-rate constraint violations, confirming its effectiveness for reliable, constraint-compliant dispatch.
Insights on Adversarial Attacks for Tabular Machine Learning via a Systematic Literature Review
Jun 18, 2025
Adversarial attacks in machine learning have been extensively reviewed in areas like computer vision and NLP, but research on tabular data remains scattered. This paper provides the first systematic literature review focused on adversarial attacks targeting tabular machine learning models. We highlight key trends, categorize attack strategies and analyze how they address practical considerations for real-world applicability. Additionally, we outline current challenges and open research questions. By offering a clear and structured overview, this review aims to guide future efforts in understanding and addressing adversarial vulnerabilities in tabular machine learning.
Brain Imaging Foundation Models, Are We There Yet? A Systematic Review of Foundation Models for Brain Imaging and Biomedical Research
Jun 16, 2025Foundation models (FMs), large neural networks pretrained on extensive and diverse datasets, have revolutionized artificial intelligence and shown significant promise in medical imaging by enabling robust performance with limited labeled data. Although numerous surveys have reviewed the application of FM in healthcare care, brain imaging remains underrepresented, despite its critical role in the diagnosis and treatment of neurological diseases using modalities such as MRI, CT, and PET. Existing reviews either marginalize brain imaging or lack depth on the unique challenges and requirements of FM in this domain, such as multimodal data integration, support for diverse clinical tasks, and handling of heterogeneous, fragmented datasets. To address this gap, we present the first comprehensive and curated review of FMs for brain imaging. We systematically analyze 161 brain imaging datasets and 86 FM architectures, providing information on key design choices, training paradigms, and optimizations driving recent advances. Our review highlights the leading models for various brain imaging tasks, summarizes their innovations, and critically examines current limitations and blind spots in the literature. We conclude by outlining future research directions to advance FM applications in brain imaging, with the aim of fostering progress in both clinical and research settings.
SafePowerGraph-LLM: Novel Power Grid Graph Embedding and Optimization with Large Language Models
Jan 13, 2025

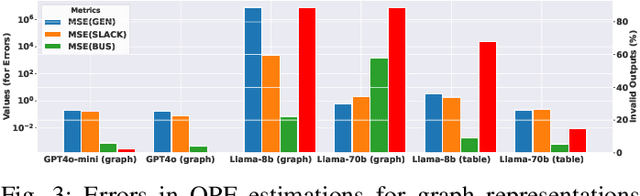

Efficiently solving Optimal Power Flow (OPF) problems in power systems is crucial for operational planning and grid management. There is a growing need for scalable algorithms capable of handling the increasing variability, constraints, and uncertainties in modern power networks while providing accurate and fast solutions. To address this, machine learning techniques, particularly Graph Neural Networks (GNNs) have emerged as promising approaches. This letter introduces SafePowerGraph-LLM, the first framework explicitly designed for solving OPF problems using Large Language Models (LLM)s. The proposed approach combines graph and tabular representations of power grids to effectively query LLMs, capturing the complex relationships and constraints in power systems. A new implementation of in-context learning and fine-tuning protocols for LLMs is introduced, tailored specifically for the OPF problem. SafePowerGraph-LLM demonstrates reliable performances using off-the-shelf LLM. Our study reveals the impact of LLM architecture, size, and fine-tuning and demonstrates our framework's ability to handle realistic grid components and constraints.
RobustBlack: Challenging Black-Box Adversarial Attacks on State-of-the-Art Defenses
Dec 30, 2024Although adversarial robustness has been extensively studied in white-box settings, recent advances in black-box attacks (including transfer- and query-based approaches) are primarily benchmarked against weak defenses, leaving a significant gap in the evaluation of their effectiveness against more recent and moderate robust models (e.g., those featured in the Robustbench leaderboard). In this paper, we question this lack of attention from black-box attacks to robust models. We establish a framework to evaluate the effectiveness of recent black-box attacks against both top-performing and standard defense mechanisms, on the ImageNet dataset. Our empirical evaluation reveals the following key findings: (1) the most advanced black-box attacks struggle to succeed even against simple adversarially trained models; (2) robust models that are optimized to withstand strong white-box attacks, such as AutoAttack, also exhibits enhanced resilience against black-box attacks; and (3) robustness alignment between the surrogate models and the target model plays a key factor in the success rate of transfer-based attacks
TabularBench: Benchmarking Adversarial Robustness for Tabular Deep Learning in Real-world Use-cases
Aug 14, 2024



While adversarial robustness in computer vision is a mature research field, fewer researchers have tackled the evasion attacks against tabular deep learning, and even fewer investigated robustification mechanisms and reliable defenses. We hypothesize that this lag in the research on tabular adversarial attacks is in part due to the lack of standardized benchmarks. To fill this gap, we propose TabularBench, the first comprehensive benchmark of robustness of tabular deep learning classification models. We evaluated adversarial robustness with CAA, an ensemble of gradient and search attacks which was recently demonstrated as the most effective attack against a tabular model. In addition to our open benchmark (https://github.com/serval-uni-lu/tabularbench) where we welcome submissions of new models and defenses, we implement 7 robustification mechanisms inspired by state-of-the-art defenses in computer vision and propose the largest benchmark of robust tabular deep learning over 200 models across five critical scenarios in finance, healthcare and security. We curated real datasets for each use case, augmented with hundreds of thousands of realistic synthetic inputs, and trained and assessed our models with and without data augmentations. We open-source our library that provides API access to all our pre-trained robust tabular models, and the largest datasets of real and synthetic tabular inputs. Finally, we analyze the impact of various defenses on the robustness and provide actionable insights to design new defenses and robustification mechanisms.
SafePowerGraph: Safety-aware Evaluation of Graph Neural Networks for Transmission Power Grids
Jul 17, 2024Power grids are critical infrastructures of paramount importance to modern society and their rapid evolution and interconnections has heightened the complexity of power systems (PS) operations. Traditional methods for grid analysis struggle with the computational demands of large-scale RES and ES integration, prompting the adoption of machine learning (ML) techniques, particularly Graph Neural Networks (GNNs). GNNs have proven effective in solving the alternating current (AC) Power Flow (PF) and Optimal Power Flow (OPF) problems, crucial for operational planning. However, existing benchmarks and datasets completely ignore safety and robustness requirements in their evaluation and never consider realistic safety-critical scenarios that most impact the operations of the power grids. We present SafePowerGraph, the first simulator-agnostic, safety-oriented framework and benchmark for GNNs in PS operations. SafePowerGraph integrates multiple PF and OPF simulators and assesses GNN performance under diverse scenarios, including energy price variations and power line outages. Our extensive experiments underscore the importance of self-supervised learning and graph attention architectures for GNN robustness. We provide at https://github.com/yamizi/SafePowerGraph our open-source repository, a comprehensive leaderboard, a dataset and model zoo and expect our framework to standardize and advance research in the critical field of GNN for power systems.
Robustness Analysis of AI Models in Critical Energy Systems
Jun 20, 2024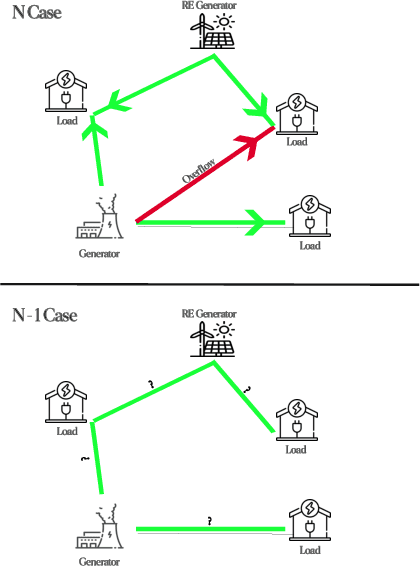
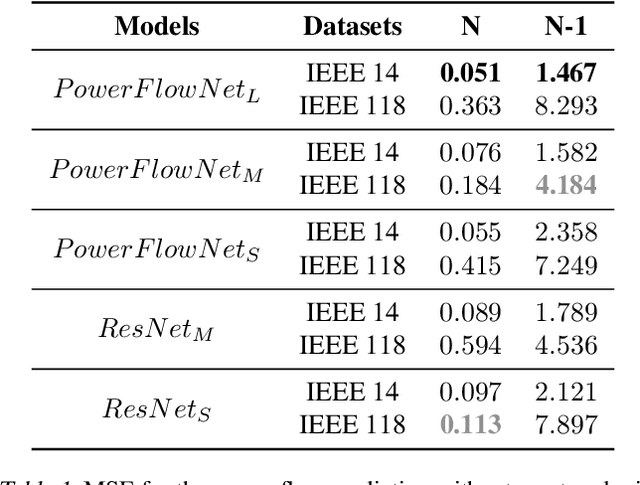
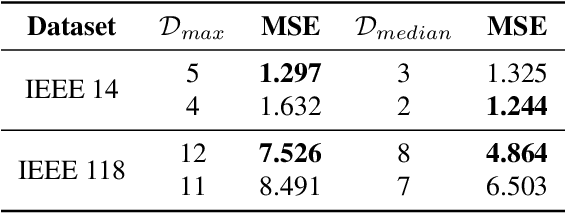
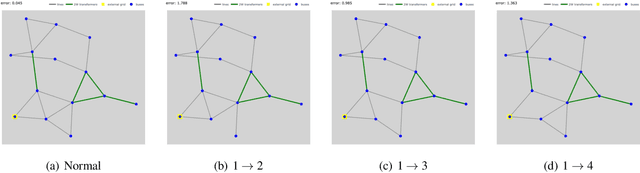
This paper analyzes the robustness of state-of-the-art AI-based models for power grid operations under the $N-1$ security criterion. While these models perform well in regular grid settings, our results highlight a significant loss in accuracy following the disconnection of a line.%under this security criterion. Using graph theory-based analysis, we demonstrate the impact of node connectivity on this loss. Our findings emphasize the need for practical scenario considerations in developing AI methodologies for critical infrastructure.
Constrained Adaptive Attack: Effective Adversarial Attack Against Deep Neural Networks for Tabular Data
Jun 02, 2024



State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there are no effective attacks to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data, such as categorical features, immutability, and feature relationship constraints. To fill this gap, we first propose CAPGD, a gradient attack that overcomes the failures of existing gradient attacks with adaptive mechanisms. This new attack does not require parameter tuning and further degrades the accuracy, up to 81% points compared to the previous gradient attacks. Second, we design CAA, an efficient evasion attack that combines our CAPGD attack and MOEVA, the best search-based attack. We demonstrate the effectiveness of our attacks on five architectures and four critical use cases. Our empirical study demonstrates that CAA outperforms all existing attacks in 17 over the 20 settings, and leads to a drop in the accuracy by up to 96.1% points and 21.9% points compared to CAPGD and MOEVA respectively while being up to five times faster than MOEVA. Given the effectiveness and efficiency of our new attacks, we argue that they should become the minimal test for any new defense or robust architectures in tabular machine learning.
PowerFlowMultiNet: Multigraph Neural Networks for Unbalanced Three-Phase Distribution Systems
Mar 12, 2024



Efficiently solving unbalanced three-phase power flow in distribution grids is pivotal for grid analysis and simulation. There is a pressing need for scalable algorithms capable of handling large-scale unbalanced power grids that can provide accurate and fast solutions. To address this, deep learning techniques, especially Graph Neural Networks (GNNs), have emerged. However, existing literature primarily focuses on balanced networks, leaving a critical gap in supporting unbalanced three-phase power grids. This letter introduces PowerFlowMultiNet, a novel multigraph GNN framework explicitly designed for unbalanced three-phase power grids. The proposed approach models each phase separately in a multigraph representation, effectively capturing the inherent asymmetry in unbalanced grids. A graph embedding mechanism utilizing message passing is introduced to capture spatial dependencies within the power system network. PowerFlowMultiNet outperforms traditional methods and other deep learning approaches in terms of accuracy and computational speed. Rigorous testing reveals significantly lower error rates and a notable hundredfold increase in computational speed for large power networks compared to model-based methods.