 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Understanding the Behavior of Quantized Models for Reliable Deployment
Paper and Code
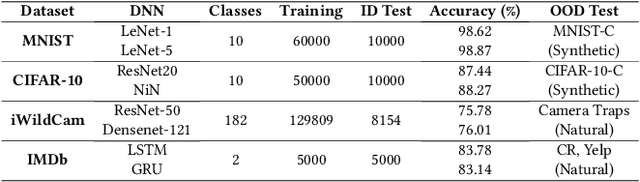
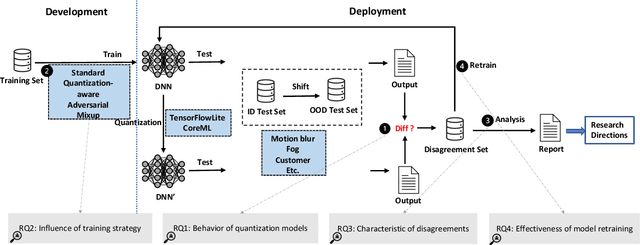
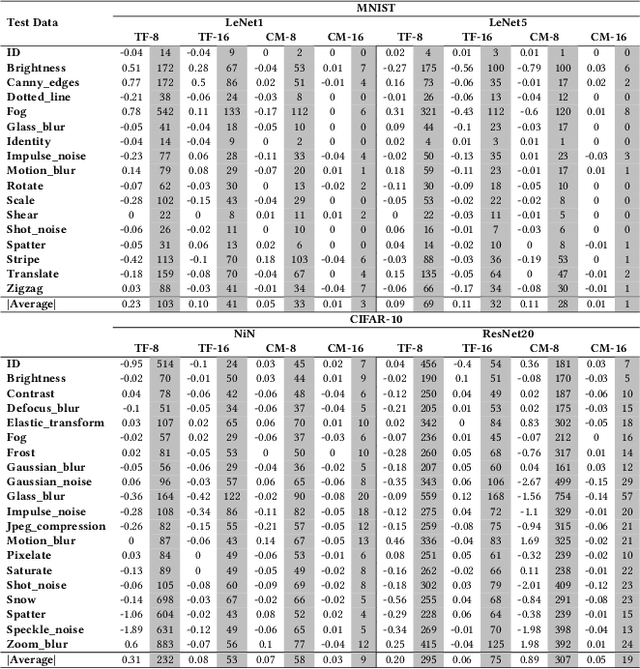
Deep Neural Networks (DNNs) have gained considerable attention in the past decades due to their astounding performance in different applications, such as natural language modeling, self-driving assistance, and source code understanding. With rapid exploration, more and more complex DNN architectures have been proposed along with huge pre-trained model parameters. The common way to use such DNN models in user-friendly devices (e.g., mobile phones) is to perform model compression before deployment. However, recent research has demonstrated that model compression, e.g., model quantization, yields accuracy degradation as well as outputs disagreements when tested on unseen data. Since the unseen data always include distribution shifts and often appear in the wild, the quality and reliability of quantized models are not ensured. In this paper, we conduct a comprehensive study to characterize and help users understand the behaviors of quantized models. Our study considers 4 datasets spanning from image to text, 8 DNN architectures including feed-forward neural networks and recurrent neural networks, and 42 shifted sets with both synthetic and natural distribution shifts. The results reveal that 1) data with distribution shifts happen more disagreements than without. 2) Quantization-aware training can produce more stable models than standard, adversarial, and Mixup training. 3) Disagreements often have closer top-1 and top-2 output probabilities, and $Margin$ is a better indicator than the other uncertainty metrics to distinguish disagreements. 4) Retraining with disagreements has limited efficiency in removing disagreements. We opensource our code and models as a new benchmark for further studying the quantized models.