 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHInter: Exposing Hidden Intersectional Bias in Large Language Models
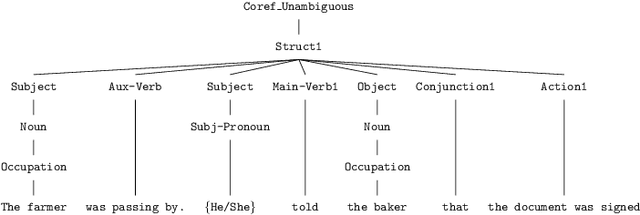
Mar 15, 2025Large Language Models (LLMs) may portray discrimination towards certain individuals, especially those characterized by multiple attributes (aka intersectional bias). Discovering intersectional bias in LLMs is challenging, as it involves complex inputs on multiple attributes (e.g. race and gender). To address this challenge, we propose HInter, a test technique that synergistically combines mutation analysis, dependency parsing and metamorphic oracles to automatically detect intersectional bias in LLMs. HInter generates test inputs by systematically mutating sentences using multiple mutations, validates inputs via a dependency invariant and detects biases by checking the LLM response on the original and mutated sentences. We evaluate HInter using six LLM architectures and 18 LLM models (GPT3.5, Llama2, BERT, etc) and find that 14.61% of the inputs generated by HInter expose intersectional bias. Results also show that our dependency invariant reduces false positives (incorrect test inputs) by an order of magnitude. Finally, we observed that 16.62% of intersectional bias errors are hidden, meaning that their corresponding atomic cases do not trigger biases. Overall, this work emphasize the importance of testing LLMs for intersectional bias.
Distribution-aware Fairness Test Generation
May 08, 2023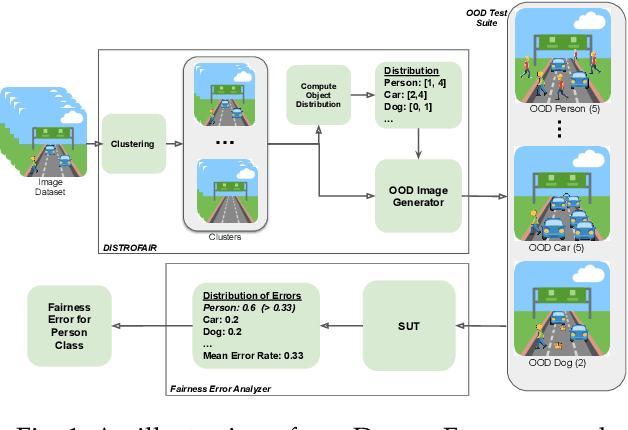

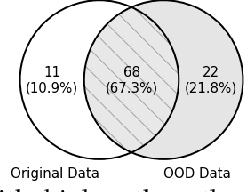

This work addresses how to validate group fairness in image recognition software. We propose a distribution-aware fairness testing approach (called DistroFair) that systematically exposes class-level fairness violations in image classifiers via a synergistic combination of out-of-distribution (OOD) testing and semantic-preserving image mutation. DistroFair automatically learns the distribution (e.g., number/orientation) of objects in a set of images. Then it systematically mutates objects in the images to become OOD using three semantic-preserving image mutations -- object deletion, object insertion and object rotation. We evaluate DistroFair using two well-known datasets (CityScapes and MS-COCO) and three major, commercial image recognition software (namely, Amazon Rekognition, Google Cloud Vision and Azure Computer Vision). Results show that about 21% of images generated by DistroFair reveal class-level fairness violations using either ground truth or metamorphic oracles. DistroFair is up to 2.3x more effective than two main baselines, i.e., (a) an approach which focuses on generating images only within the distribution (ID) and (b) fairness analysis using only the original image dataset. We further observed that DistroFair is efficient, it generates 460 images per hour, on average. Finally, we evaluate the semantic validity of our approach via a user study with 81 participants, using 30 real images and 30 corresponding mutated images generated by DistroFair. We found that images generated by DistroFair are 80% as realistic as real-world images.
Astraea: Grammar-based Fairness Testing
Oct 06, 2020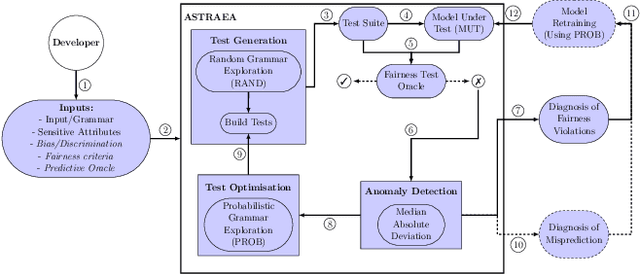


Software often produces biased outputs. In particular, machine learning (ML) based software are known to produce erroneous predictions when processing discriminatory inputs. Such unfair program behavior can be caused by societal bias. In the last few years, Amazon, Microsoft and Google have provided software services that produce unfair outputs, mostly due to societal bias (e.g. gender or race). In such events, developers are saddled with the task of conducting fairness testing. Fairness testing is challenging; developers are tasked with generating discriminatory inputs that reveal and explain biases. We propose a grammar-based fairness testing approach (called ASTRAEA) which leverages context-free grammars to generate discriminatory inputs that reveal fairness violations in software systems. Using probabilistic grammars, ASTRAEA also provides fault diagnosis by isolating the cause of observed software bias. ASTRAEA's diagnoses facilitate the improvement of ML fairness. ASTRAEA was evaluated on 18 software systems that provide three major natural language processing (NLP) services. In our evaluation, ASTRAEA generated fairness violations with a rate of ~18%. ASTRAEA generated over 573K discriminatory test cases and found over 102K fairness violations. Furthermore, ASTRAEA improves software fairness by ~76%, via model-retraining.
Exposing Backdoors in Robust Machine Learning Models
Feb 25, 2020
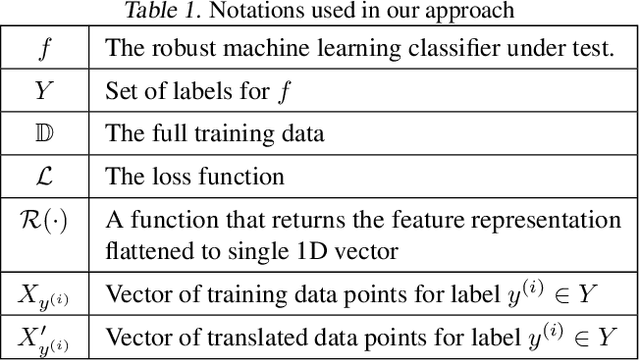


The introduction of robust optimisation has pushed the state-of-the-art in defending against adversarial attacks. However, the behaviour of such optimisation has not been studied in the light of a fundamentally different class of attacks called backdoors. In this paper, we demonstrate that adversarially robust models are susceptible to backdoor attacks. Subsequently, we observe that backdoors are reflected in the feature representation of such models. Then, this is leveraged to detect backdoor-infected models. Specifically, we use feature clustering to effectively detect backdoor-infected robust Deep Neural Networks (DNNs). In our evaluation of major classification tasks, our approach effectively detects robust DNNs infected with backdoors. Our investigation reveals that salient features of adversarially robust DNNs break the stealthy nature of backdoor attacks.